Python — один из самых популярных языков программирования в области анализа данных и машинного обучения. Мощь и простота языка позволяют разработчикам легко и быстро проводить обработку данных, создавать модели и реализовывать алгоритмы машинного обучения.

Индивидуальный график
Индивидуальный график
Индивидуальный график
При обработке данных одним из важных шагов является их предварительная обработка и преобразование. Библиотека scikit-learn в Python предлагает широкий набор инструментов для работы с данными, включая методы кодирования категориальных признаков, масштабирования числовых значений и заполнения пропущенных данных.
После обработки данных можно создавать модели машинного обучения с использованием библиотеки scikit-learn. Библиотека предоставляет различные алгоритмы, такие как линейная регрессия, деревья решений, случайные леса и множество других. Каждая модель имеет свои особенности и подходит для разных типов данных и задач.
Используя библиотеку scikit-learn, разработчик может легко и эффективно проводить обработку данных и построение моделей машинного обучения на языке Python. Это позволяет сократить время и усилить результаты исследований и анализа данных, а также использовать полученные модели для решения практических задач.
Обработка данных и построение моделей на Python с помощью библиотеки scikit-learn
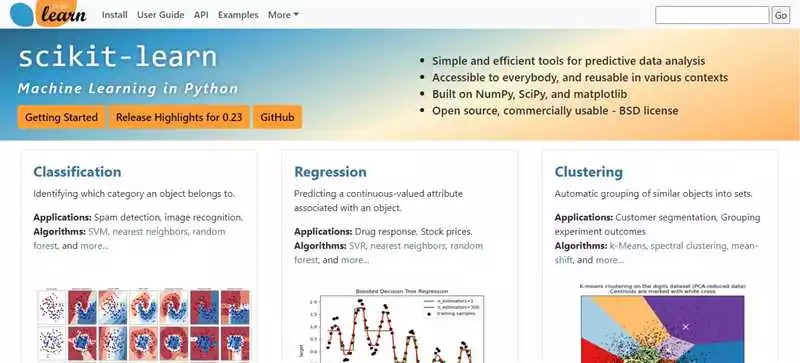
Scikit-learn — это одна из самых популярных и широко используемых библиотек машинного обучения на языке программирования Python. С её помощью можно создать и обучить различные модели машинного обучения для работы с данными.
Одним из первых шагов при работе с данными является их обработка. В scikit-learn существует множество инструментов для выполнения различных операций над данными, таких как:
- Загрузка данных из различных источников
- Предварительная обработка данных, включая заполнение пропущенных значений или удаление выбросов
- Кодирование категориальных переменных
- Масштабирование данных
- Преобразование данных в пригодный для моделирования формат
Для начала работы с данными в scikit-learn, их необходимо загрузить из соответствующего источника. Библиотека предоставляет методы для загрузки данных из файлов CSV, баз данных, а также с веб-страниц. После загрузки данных можно приступать к их обработке.
Обработка данных включает в себя такие операции, как заполнение пропущенных значений или удаление выбросов. Scikit-learn предлагает методы для выполнения этих операций, которые могут быть применены к различным типам данных.
Еще одним важным шагом при обработке данных является кодирование категориальных переменных. Категориальные переменные — это переменные, которые принимают значения из некоторого ограниченного набора. Scikit-learn предлагает методы для преобразования категориальных переменных в числовые значения, которые могут быть использованы моделью для обучения.
После обработки данных и кодирования категориальных переменных, следующим шагом является преобразование данных в формат, пригодный для моделирования. Scikit-learn предоставляет методы для выполнения различных преобразований данных, таких как масштабирование, нормализация или приведение к нужному диапазону значений.
В итоге, после завершения обработки данных, можно приступать к созданию и обучению моделей машинного обучения на Python с помощью библиотеки scikit-learn. Библиотека предлагает множество моделей, таких как линейная регрессия, случайный лес, метод главных компонент и многие другие. С их помощью можно решать различные задачи, от классификации и регрессии до кластеризации и снижения размерности данных.
Scikit-learn — мощный инструмент для работы с данными и построения моделей на Python. Он предоставляет широкий набор функций для обработки данных и создания моделей, что делает его одним из самых популярных выборов для любого проекта, связанного с машинным обучением и анализом данных.
Обработка данных и построение моделей на Python с помощью библиотеки scikit-learn
Библиотека scikit-learn предоставляет широкий набор инструментов для обработки данных и построения моделей на языке программирования Python. Эта библиотека является одной из самых популярных и мощных в области машинного обучения и анализа данных.
Одной из основных задач обработки данных является преобразование и представление исходных данных в формат, пригодный для использования в алгоритмах машинного обучения. Scikit-learn предоставляет множество инструментов для работы с различными типами данных.
Для начала работы с данными в scikit-learn, необходимо их загрузить и подготовить. Для этого можно использовать различные функции, например, load_iris или load_boston, которые загружают предустановленные наборы данных.
После загрузки данных, их можно преобразовать с помощью различных методов. Например, функция scale позволяет нормализовать данные путем центрирования и масштабирования. Другой полезный метод — polynomial_features, который позволяет создавать полиномиальные признаки из исходных данных.
Кроме преобразования данных, scikit-learn предоставляет возможность кодирования категориальных переменных. Например, функция LabelEncoder позволяет преобразовать текстовые значения в числовые коды. Также можно использовать метод OneHotEncoder для создания бинарных признаков из категориальных.
После обработки данных можно приступить к созданию моделей машинного обучения. Scikit-learn предоставляет множество различных моделей, таких как линейная регрессия, дерево решений, случайный лес и многие другие. Для создания модели необходимо выбрать подходящую функцию из библиотеки и обучить ее на обработанных данных.
После обучения модели можно использовать ее для предсказания новых данных. Например, функция predict позволяет предсказать значение зависимой переменной на основе входных данных. Также можно использовать функцию score, чтобы оценить точность модели на тестовых данных.
Обработка данных и построение моделей на Python с помощью библиотеки scikit-learn является очень удобным и эффективным процессом. С помощью этой библиотеки можно легко и быстро преобразовать данные, закодировать категориальные переменные и создать модели машинного обучения. Это делает scikit-learn одной из наиболее популярных библиотек для работы с данными и построения моделей на Python.
Как закодировать данные и создать модели
Процесс создания модели машинного обучения с использованием scikit-learn — это непростая задача, которая включает в себя обработку и преобразование данных, а также выбор и настройку подходящей модели. Для успешного выполнения этой задачи необходимо правильно закодировать данные и применить соответствующие методы.
Библиотека scikit-learn предоставляет широкий набор инструментов для обработки и преобразования данных с помощью методов кодирования. Она позволяет преобразовать категориальные данные в числовые, чтобы обучаемая модель могла эффективно работать с ними.
Одним из наиболее распространенных методов кодирования, предоставляемых scikit-learn, является метод One-Hot Encoding. Он позволяет преобразовать каждое уникальное значение категориальной переменной в новый бинарный столбец. Это позволяет модели машинного обучения учитывать различия между различными категориями.
Процесс применения кодирования с использованием scikit-learn обычно выглядит следующим образом:
- Импорт необходимых модулей и классов из библиотеки scikit-learn.
- Получение данных и их подготовка для обработки. Это включает в себя удаление пустых значений, масштабирование числовых данных и сегментацию на обучающий и тестовый наборы.
- Применение метода кодирования к категориальным переменным. Например, использование класса OneHotEncoder для кодирования переменных типа «object».
- Объединение закодированных переменных с числовыми данными, чтобы создать полный набор данных для обучения модели.
- Выбор и создание модели машинного обучения из библиотеки scikit-learn.
- Настройка параметров модели и ее обучение с использованием подготовленных данных.
- Оценка производительности модели с помощью метрик, таких как точность, полнота и F-мера.
После успешной обработки данных и создания модели, она может быть использована для предсказания новых наблюдений на основе уже известных данных. Для этого необходимо сначала преобразовать новые данные в правильный формат и затем применить обученную модель для предсказания.
Создание моделей машинного обучения с использованием библиотеки scikit-learn является мощным инструментом для анализа данных и предсказания. Правильное преобразование и кодирование данных является ключевым этапом этого процесса и позволяет использовать всю мощность моделей.
Преобразование данных для обработки

В процессе обработки данных перед построением модели машинного обучения важным шагом является преобразование этих данных. Преобразование данных часто включает в себя закодирование категориальных переменных, масштабирование непрерывных переменных и удаление выбросов. Для этих целей в Python можно использовать популярную библиотеку scikit-learn.
Scikit-learn предоставляет широкие возможности для преобразования данных. Она позволяет создать и применить различные методики преобразования данных для подготовки данных к обучению модели.
Одним из наиболее распространенных способов преобразования данных является закодирование категориальных переменных. Категориальные переменные представляют собой переменные, которые принимают ограниченное количество значений. Например, переменная «цвет» может принимать значения «красный», «зеленый» и «синий». Для обработки такой переменной можно использовать методика прямого кодирования (one-hot encoding) или методика кодирования меток (label encoding), которая присваивает каждому значению целочисленную метку.
Для масштабирования непрерывных переменных, которые представляют собой переменные, принимающие любые значения на некотором интервале, можно использовать методики стандартизации или нормализации. Стандартизация масштабирует данные таким образом, чтобы их среднее значение было равно нулю и стандартное отклонение было равно единице. Нормализация масштабирует данные в интервал от 0 до 1.
Еще одним важным шагом в обработке данных является удаление выбросов. Выбросы — это значения, которые сильно отличаются от остальных значений переменной и могут искажать результаты моделирования. Для удаления выбросов можно использовать различные методики, такие как удаление по пороговому значению, замена выбросов на среднее или медиану, или применение статистических методов, таких как z-оценка.
Преобразование данных является важным этапом в обработке данных и подготовке их к обучению модели. Библиотека scikit-learn в Python предоставляет удобные и эффективные методы для выполнения этого преобразования, что позволяет упростить процесс и повысить качество моделирования данных.
Создание моделей с помощью scikit-learn
Библиотека scikit-learn — одна из самых популярных библиотек для обработки данных и создания моделей на языке Python. Она предоставляет широкий спектр инструментов и алгоритмов, которые помогают исследователям и разработчикам в работе с данными.
Для создания модели с использованием scikit-learn необходимо следовать нескольким шагам. Первым шагом является закодирование данных. Это означает преобразование категориальных или текстовых переменных в числовые значения, к которым модели могут обращаться. Scikit-learn предоставляет различные методы для кодирования данных, такие как LabelEncoder или OneHotEncoder.
После того как данные были закодированы, следующим шагом является обработка данных. Это включает в себя шаги, такие как масштабирование данных или заполнение пропущенных значений. Scikit-learn предоставляет инструменты для выполнения этих операций, такие как StandardScaler или Imputer.
После обработки данных необходимо создать модель. Scikit-learn предлагает большой выбор моделей, включая линейные модели, деревья решений, случайные леса, градиентный бустинг и многое другое. Для каждой модели существуют параметры, которые можно настроить для достижения лучших результатов.
После создания модели ее необходимо обучить на обучающих данных. Для этого используется метод fit, который принимает на вход тренировочные данные и соответствующие им целевые значения. В процессе обучения модель настраивает свои параметры, чтобы максимизировать точность предсказания.
Когда модель была обучена, можно использовать ее для делания предсказаний. Для этого используется метод predict, который принимает на вход новые данные и возвращает предсказанные значения. Это позволяет использовать модель для прогнозирования новых наблюдений.
В заключение, создание моделей с помощью scikit-learn — это процесс, включающий в себя закодирование данных, обработку данных, создание и обучение модели. Благодаря широкому выбору инструментов и алгоритмов, предоставляемых библиотекой scikit-learn, исследователи и разработчики могут эффективно работать с данными и создавать точные предсказательные модели на языке Python.