Веб-страницы в современном Интернете – это основа информационной среды. Мы постоянно общаемся с ними, исследуем их содержимое, ищем нужную информацию. Но что, если мы хотим автоматизировать этот процесс и извлекать нужные данные из веб-страниц? Вот где нам на помощь приходит парсинг веб-страниц с использованием библиотеки BeautifulSoup на языке Python!

Индивидуальный график
Индивидуальный график
Индивидуальный график
Beautiful Soup — это Python библиотека для извлечения данных из HTML и XML файлов. Она предоставляет удобный и простой способ обхода, поиска и манипулирования структурой веб-страниц. Благодаря простому и интуитивно понятному синтаксису, Beautiful Soup стал одним из самых популярных инструментов для парсинга веб-страниц на Python.
В этом практическом курсе мы научимся использовать библиотеку Beautiful Soup для парсинга веб-страниц на Python. Мы разберем основные принципы и техники парсинга, а также изучим различные методы поиска и фильтрации данных на веб-страницах. Будем использовать наши знания и навыки на практике, чтобы извлекать информацию из реальных веб-страниц.
Практический курс для начинающих
Beautiful Soup — это популярная библиотека на языке Python, которая предоставляет удобные инструменты для парсинга веб-страниц. С ее помощью вы можете извлекать информацию из HTML-кода и работать с ним в удобном формате. В этом практическом курсе мы рассмотрим основные возможности Beautiful Soup и научимся использовать их для парсинга веб-страниц.
Веб-страницы содержат множество различной информации, такой как текст, изображения, таблицы, списки и многое другое. Для того чтобы получить доступ к этой информации и использовать ее в своих проектах, необходимо научиться парсить веб-страницы. И именно в этом нам поможет Beautiful Soup.
Beautiful Soup предоставляет удобный интерфейс для работы с HTML-кодом. Он позволяет извлекать данные из различных элементов на веб-странице, таких как заголовки, абзацы, списки, таблицы и др. Благодаря этой библиотеке вы можете легко и быстро находить нужную информацию на веб-страницах и использовать ее для своих целей.
Для начала работы с Beautiful Soup, вам необходимо установить его на свой компьютер. Для этого выполните следующую команду в командной строке:
pip install beautifulsoup4
После установки Beautiful Soup вы можете начать использовать его в своих скриптах на Python. Для этого импортируйте его следующим образом:
from bs4 import BeautifulSoup
Теперь у вас есть доступ к функциям и методам Beautiful Soup для парсинга веб-страниц. С помощью них вы сможете находить нужные элементы на странице и работать с ними.
Beautiful Soup предоставляет множество методов для работы с различными типами элементов на веб-странице. Например, вы можете использовать метод find() для поиска первого элемента с указанным тегом, или метод find_all() для поиска всех элементов с указанным тегом.
Кроме того, вы можете использовать CSS-селекторы для поиска элементов на веб-странице с помощью метода select(). Такой подход очень удобен, так как позволяет находить элементы, которые удовлетворяют определенным условиям.
Beautiful Soup также предоставляет возможность работать с текстовым содержимым элементов, атрибутами, классами и другими свойствами веб-страницы. Вы можете извлекать нужную информацию и использовать ее в своих проектах.
В данном практическом курсе мы рассмотрим основные принципы парсинга веб-страниц с использованием Beautiful Soup. Мы научимся извлекать данные из различных элементов на веб-странице, работать с текстом, атрибутами и другими свойствами. Кроме того, мы рассмотрим различные методы и подходы к парсингу веб-страниц и научимся применять их на практике.
Теперь у вас есть все необходимые знания для начала работы с Beautiful Soup и парсинга веб-страниц на языке Python. Применяйте полученные навыки в своих проектах и используйте найденную информацию в своих целях. Удачи в ваших парсинговых приключениях!
Протокол HTTP и Web-разработка на Python
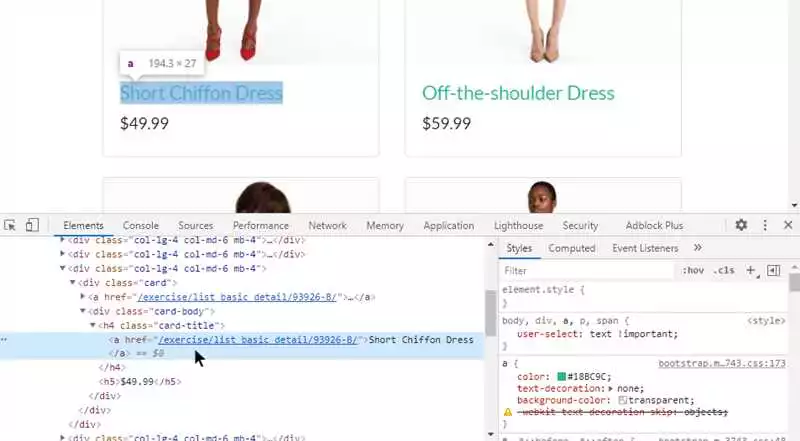
Протокол HTTP (Hypertext Transfer Protocol) — это основной протокол, используемый для передачи данных в Интернете. Он определяет формат сообщений и правила обмена данными между клиентом (например, веб-браузером) и сервером (например, веб-сервером). Каждый раз, когда вы заходите на веб-страницу, ваш веб-браузер отправляет HTTP-запрос на сервер, чтобы получить содержимое этой страницы.
Web-разработка на Python позволяет создавать динамические веб-приложения и решать разнообразные задачи. Одним из основных инструментов для работы с веб-страницами на языке Python является библиотека Beautiful Soup. С ее помощью мы можем легко и удобно парсить HTML-код веб-страниц, извлекать нужные данные и проводить различные операции.
Курс «Учимся парсить веб-страницы на Python с помощью Beautiful Soup» представляет собой практическое руководство для начинающих, которые хотят освоить базовые навыки парсинга веб-страниц с использованием Python и библиотеки Beautiful Soup. В ходе курса вы научитесь извлекать данные из HTML-кода, навигировать по дереву DOM-дерева, работать с CSS-селекторами, управлять элементами страницы и многое другое.
Курс рассчитан на тех, кто уже знаком с основами языка Python и имеет базовые знания HTML и CSS. Он состоит из нескольких уроков, каждый из которых содержит практические примеры и пошаговое руководство. По окончании курса вы сможете самостоятельно решать задачи по парсингу веб-страниц на Python и использовать полученные данные для анализа, обработки или отображения.
Если вы заинтересованы в изучении парсинга веб-страниц на Python и улучшении ваших навыков веб-разработки, то курс «Учимся парсить веб-страницы на Python с помощью Beautiful Soup» будет отличным выбором для вас.
Изучаем протокол HTTP
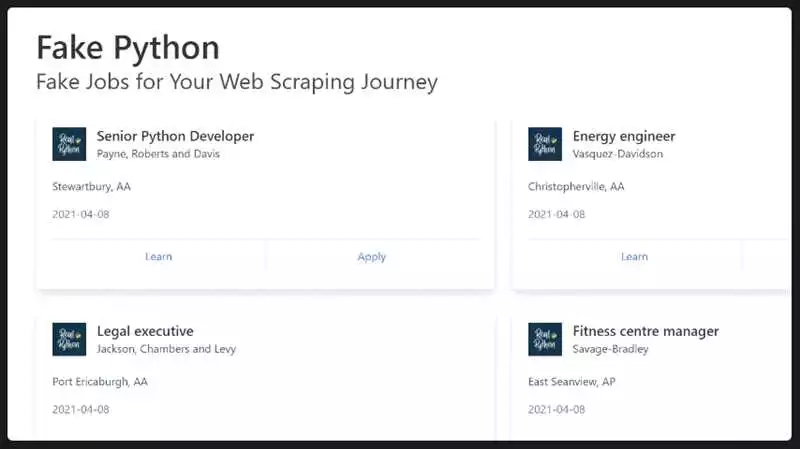
В контексте темы «Учимся парсить веб-страницы на Python с помощью Beautiful Soup практический курс для начинающих» мы изучаем протокол HTTP, который является основой взаимодействия между веб-страницами и серверами. Парсить веб-страницы с помощью Python и библиотеки Beautiful Soup становится значительно проще, когда мы понимаем, как работает этот протокол.
Протокол HTTP, или HyperText Transfer Protocol (Протокол передачи гипертекста), является протоколом прикладного уровня, который определяет, как клиент и сервер обмениваются информацией. Веб-страницы, состоящие из гипертекстовых документов, передаются посредством протокола HTTP.
При парсинге веб-страниц с помощью Python и библиотеки Beautiful Soup, мы отправляем HTTP-запросы на сервер, чтобы получить данные. Затем сервер отвечает на этот запрос, передавая нам код состояния, заголовки и саму веб-страницу. Эта информация передается с помощью методов и статусных кодов протокола HTTP.
Мы учимся парсить веб-страницы с использованием Python и библиотеки Beautiful Soup, чтобы получить доступ к содержимому HTML. Но перед этим мы должны понять, как правильно отправлять HTTP-запросы, как обрабатывать полученные HTTP-ответы и как интерпретировать статусные коды.
Процесс парсинга веб-страниц с помощью Python, Beautiful Soup и протокола HTTP является важным инструментом для сбора данных, автоматизации задач и создания веб-скрапера. Начинающим разработчикам крайне полезно изучать эту тему и освоить навыки парсинга веб-страниц.
Основы веб-разработки на Python
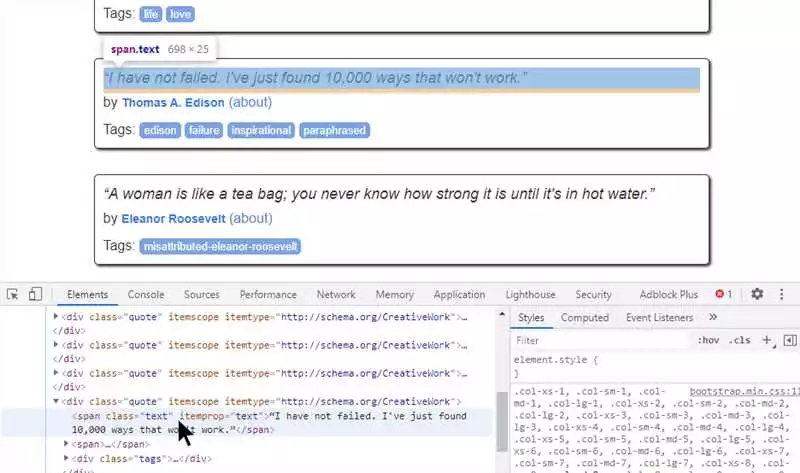
Python — один из самых популярных языков программирования в мире. Он широко применяется во множестве областей, включая веб-разработку. Веб-разработка на Python осуществляется с помощью различных библиотек и фреймворков, которые облегчают процесс создания веб-приложений.
Одной из таких библиотек является Beautiful Soup. Она предоставляет удобные средства для парсинга веб-страниц, что позволяет извлекать нужные данные и проводить анализ информации.
При работе с веб-страницами, парсинг является важной частью процесса. Парсинг позволяет извлекать данные из HTML-кода страницы, что может быть полезно для автоматизации задач, создания агрегаторов новостей, мониторинга цен и многого другого.
На практическом курсе по Beautiful Soup вы познакомитесь с основами парсинга веб-страниц на Python. Вы изучите различные методы и возможности библиотеки, чтобы с легкостью справляться с задачами по работе с HTML-кодом.
Кроме Beautiful Soup, веб-разработка на Python может включать использование других библиотек и фреймворков. Некоторые из них включают в себя Django, Flask, Pyramid, Tornado и другие. Эти инструменты облегчают создание веб-приложений, обработку запросов, работу с базами данных и многое другое.
Научиться веб-разработке на Python — это отличный способ расширить свои навыки программирования и получить возможность создавать современные и функциональные веб-приложения. Использование Python и его библиотек делает процесс разработки удобным и эффективным.
Применение Beautiful Soup в парсинге веб-страниц
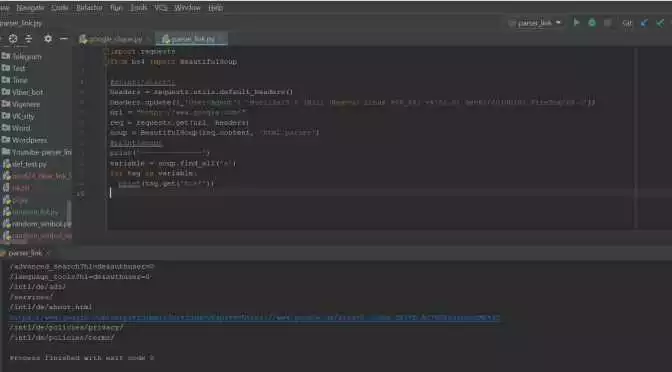
В данной статье мы рассмотрим практическое применение библиотеки Beautiful Soup для парсинга веб-страниц на языке Python. Beautiful Soup является одной из наиболее популярных и мощных библиотек для работы с HTML и XML структурами.
Beautiful Soup предоставляет удобные инструменты для извлечения и обработки информации с веб-страниц. Он позволяет легко находить интересующие нас элементы на странице и извлекать необходимые данные. Это особенно полезно при автоматизации процессов или извлечении информации для анализа.
Для начала работы с Beautiful Soup необходимо установить эту библиотеку на компьютер. Это можно сделать с помощью пакетного менеджера pip:
pip install beautifulsoup4Основными концепциями, которыми следует ознакомиться при использовании Beautiful Soup, являются объекты «тег» и «объект дерева». На веб-странице теги представляют элементы разметки, такие как заголовки, параграфы, таблицы и т.д. Объект дерева представляет всю иерархическую структуру веб-страницы.
Процесс парсинга веб-страницы с использованием Beautiful Soup включает следующие шаги:
- Загрузка веб-страницы с использованием библиотеки requests:
- Создание объекта Beautiful Soup на основе загруженного контента страницы:
- Выполнение поиска необходимых элементов на странице и извлечение нужной информации:
import requests
response = requests.get('https://example.com')
page_content = response.content
from bs4 import BeautifulSoup
soup = BeautifulSoup(page_content, 'html.parser')
# Нахождение всех заголовков h2 на странице
headers = soup.find_all('h2')
for header in headers:
print(header.text)
Beautiful Soup также предоставляет множество различных методов для поиска и фильтрации элементов на странице, таких как find(), find_all(), select() и др. Таким образом, мы можем легко находить и извлекать данные, например, по id, классу, тегу и другим атрибутам элементов.
В заключение можно сказать, что Beautiful Soup является мощным инструментом для парсинга веб-страниц на языке Python. Он позволяет нам эффективно извлекать и обрабатывать информацию с веб-страниц, что делает его очень полезным при работе с данными из интернета.