При работе с программированием в языке Python невозможно обойти понятие строки. Строка — это последовательность символов и один из основных типов данных в Python. Однако, чтобы полноценно пользоваться строками, необходимо иметь понимание о структуре и организации данных в них.

Индивидуальный график
Индивидуальный график
Индивидуальный график
Важным аспектом при работе с строками в Python является кодировка символов. В современном мире символы представляются в компьютерах с использованием стандарта UNICODE, который определяет целочисленное значение для каждого символа. Каждый символ имеет свой уникальный код, и их совокупность представляет собой UNICODE-строку.
Однако, непосредственно в памяти компьютера строки представлены более сложным образом, с использованием различных кодировок. Кодировка — это метод, с помощью которого символы UNICODE представляются в виде байтовых последовательностей. Наиболее распространеными кодировками в Python являются UTF-8, UTF-16, и Latin-1, каждая из которых имеет свои особенности и предназначена для определенного использования.
В данной статье мы рассмотрим основы работы со строками в Python и изучим особенности кодировок. Понимание структуры и организации строк в Python является важным аспектом для эффективной работы с данными и создания многоязыковых программ. Начнем с изучения основных функций работы со строками, а затем перейдем к изучению UNICODE и кодировок в Python.
Структура строки в Python: что такое UNICODE и кодировки
Концепция и организация строк в Python
Строки в Python представляют собой последовательности символов и являются неизменяемыми объектами. Каждый символ строки имеет свой индекс, начинающийся с 0. При обращении к элементам строки можно использовать положительные и отрицательные индексы. Положительные индексы считаются слева направо, а отрицательные — справа налево.
Понятие UNICODE и кодировок
Прежде чем рассматривать структуру строки в Python, необходимо понять, что такое UNICODE и кодировки. UNICODE — это стандарт, который содержит числовые значения для всех символов, используемых в текстовых данных различных языков и символов пунктуации.
Кодировка определяет способ представления символов UNICODE в виде последовательности битов. Кодировки в Python позволяют работать с символами различных языков и обрабатывать текстовые данные в различных форматах.
Структура строк в Python
В Python строки могут быть представлены в нескольких форматах:
- Строки в одинарных кавычках: ‘Пример строки’
- Строки в двойных кавычках: «Пример строки»
- Многострочные строки в тройных кавычках:
"""
Пример
многострочной
строки
"""
Строки в Python могут содержать символы UNICODE, которые представляются символьными значениями. Для удобства работы с UNICODE символами и строками, в Python существует ряд функций для их преобразования и обработки.
Пример использования структуры строк в Python
Ниже приведен пример использования структуры строк в Python:
s = 'Hello, World!' # создание строки
print(s) # вывод строки
c = s[0] # доступ к символу строки по индексу
print(c) # вывод символа
s2 = s[:5] # извлечение подстроки
print(s2) # вывод подстроки
s3 = s.upper() # преобразование строки в верхний регистр
print(s3) # вывод преобразованной строки
Вывод:
Строки в Python имеют свою структуру, которая позволяет работать с символами и символьными значениями UNICODE. Кодировки позволяют представлять символы в различных форматах. Понимание структуры строк и кодировок в Python является важным для успешной работы с текстовыми данными.
Строки strings

Строки являются одним из основных типов данных в языке программирования Python. Понимание структуры строк и понятия кодировок и Unicode важно для работы с ними.
Строка представляет собой последовательность символов. Эти символы могут быть буквами, цифрами, специальными символами и пробелами. В Python строки можно представить в одинарных, двойных или тройных кавычках.
Строки в Python имеют свою структуру и концепцию. Например, каждый символ строки имеет свой индекс, который можно использовать для доступа к отдельным символам строки.
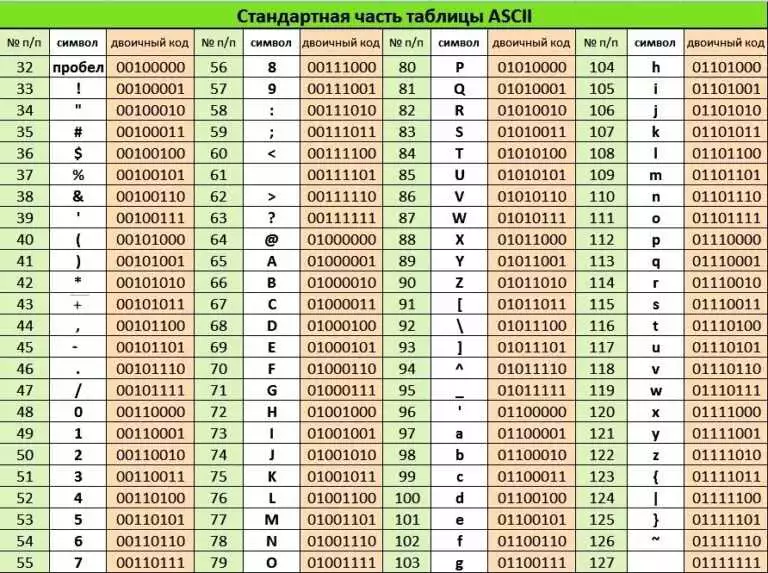
Python поддерживает различные кодировки, такие как ASCII, UTF-8, UTF-16 и т. д. Кодировка определяет способ представления символов в виде последовательности байтов.
Unicode — это стандарт, который представляет символы различных языков и символы разных систем письма. Unicode позволяет использовать символы различных языков в одной строке.
Кодировки и Unicode важны при работе с строками в Python. Правильное использование кодировок позволяет корректно обрабатывать и отображать символы различных языков и символы разных систем письма.
Нужно помнить о том, что при работе с кодировками и Unicode могут возникать различные проблемы, такие как неправильное отображение символов или ошибки в кодировке. Поэтому важно иметь хорошее понимание структуры строк и знать основы работы с кодировками и Unicode в Python.
Типы данных и переменные
В Python каждое значение имеет свой тип данных. Одним из наиболее важных типов данных является тип данных строка.
Строка — это пример структуры данных, представляющей собой последовательность символов. В Python строки представлены с помощью типа данных unicode.
Термин unicode относится к стандарту, позволяющему кодировать символы исходя из их числового представления. Понимание кодировок и структуры данных типа unicode является важным для работы с текстом в Python.
Организация и нумерация символов в кодировке unicode осуществляется с помощью кодовых точек. Каждому символу присваивается уникальный код, который состоит из одного или нескольких байтов.
Концепция unicode позволяет работать с символами различных алфавитов и языков, повышая универсальность и функциональность программного кода.
В Python строки объявляются с помощью кавычек. Например:
my_string = "Пример строки"
print(my_string)
В переменной my_string будет храниться строка «Пример строки».
Строки в Python являются неизменяемыми объектами. Это означает, что после объявления строки нельзя изменить ее содержимое. Однако, можно создавать новые строки на основе существующих с помощью различных методов и операций.
Понимание основных концепций и структуры строк в Python позволяет эффективно работать с текстовой информацией и выполнять различные операции над строками.
Формирование строки в Python: концепция UNICODE и кодировок

Организация структуры строки в Python связана с понятием UNICODE и различными кодировками. В этом контексте, UNICODE — это стандартное представление символов исходного кода, которое обеспечивает единый набор символов для всех языков и символьных систем.
Кодировка — это способ, с помощью которого символы UNICODE представляются в компьютере. Различные кодировки определяют, как символы UNICODE сохраняются и передаются в виде байтовых последовательностей.
В языке Python, все строки по умолчанию являются UNICODE. Это означает, что символы могут быть представлены с помощью различных кодировок. Например, кодировка UTF-8, которая широко используется в интернете, позволяет представить почти все символы из всех языков мира.
Концепция UNICODE и кодировок в Python позволяет работать с различными языками и символами в одной строке. Это особенно полезно при работе с многоязычными текстами, например, при разработке интернациональных веб-приложений.
Важно понимать, что при работе с кодировками в Python необходимо правильно настроить кодировки ввода и вывода, чтобы избежать проблем с отображением символов. Python обеспечивает широкий набор инструментов для работы с кодировками и конвертацией между ними.
| Кодировка | Описание |
|---|---|
| ASCII | Однобайтовая кодировка, поддерживающая основной набор английских символов |
| UTF-8 | Многоязычная кодировка, поддерживающая широкий набор символов из разных языков |
| Windows-1251 | Кодировка, используемая по умолчанию в операционных системах Windows |
Кодировки в Python облегчают работу с текстом в различных языках и символах. Знание и понимание концепции UNICODE и кодировок является важным для разработчика, чтобы эффективно работать с текстом и избежать проблем связанных с неправильным представлением символов.
Понимание UNICODE
Python — это интерпретируемый язык программирования, который широко используется для разработки веб-приложений, научных расчетов, автоматизации задач и многого другого. Одним из важных аспектов использования Python является понимание работы со строками и понятие UNICODE.
Строки в Python представляют собой последовательность символов, которые могут быть представлены различными кодировками, такими как ASCII, UTF-8, UTF-16 и т. д. Каждый символ имеет свой уникальный номер, который называется кодовой точкой.
Понятие UNICODE в Python относится к стандарту, который определяет уникальный числовой идентификатор (кодовую точку) для каждого символа во всех письменных системах. UNICODE позволяет представлять символы различных письменных систем и языков в компьютерных системах.
Кодировки в Python определяют, какие символы из UNICODE будут представлены в двоичной форме (байты). Все символы UNICODE могут быть представлены в компьютере с помощью различных кодировок, которые определяются набором правил. Поэтому для корректного отображения и обработки символов необходимо выбрать правильную кодировку.
Концепция UNICODE в Python состоит в том, что каждый символ представлен в виде своей уникальной кодовой точки, а не в виде байтов. Это позволяет работать с символами из различных письменных систем без привязки к конкретной кодировке.
Организация структуры UNICODE основана на таблицах символов, которые определяют отображение каждой кодовой точки на конкретный символ. Unicode Consortium является организацией, которая определяет, обновляет и поддерживает стандарт UNICODE.
| Кодовая точка | Символ |
|---|---|
| U+0041 | A |
| U+041F | П |
| U+00E9 | é |
Приведенная выше таблица показывает несколько примеров кодовых точек и соответствующих символов.
Таким образом, понимание UNICODE позволяет работать с символами различных письменных систем и языков в Python, выбирая подходящую кодировку для корректного отображения и обработки строковых данных.
Понимание кодировок

При работе с строками в Python важно понимать основные принципы организации и структуры кодировок. Кодировки используются для представления символов в компьютерных системах и являются основным инструментом для работы с текстом.
Одной из ключевых концепций кодировок является Unicode — универсальный стандарт кодирования, который содержит огромное количество символов и символьных наборов, включая символы практически всех письменных языков в мире.
В языке программирования Python строки представлены в виде последовательности символов Unicode. Это означает, что в строке можно использовать символы разных языков, включая кириллицу, латиницу, китайские и японские иероглифы и другие.
Однако, для хранения и передачи символов Unicode приходится использовать различные кодировки. Кодировка — это механизм, который определяет соответствие между символами и их числовым представлением в памяти компьютера.
В Python для работы с кодировками и преобразованиями между различными представлениями символов используются различные библиотеки и модули, такие как codecs или стандартная библиотека string.
Например, для кодирования строки в байтовую последовательность можно использовать метод encode(), а для декодирования — метод decode().
Для более удобного представления информации о различных кодировках можно использовать таблицы, в которых перечислены символы и соответствующие им числовые значения. Ниже приведен пример такой таблицы для кодировки UTF-8:
| Символ | Числовое значение |
|---|---|
| A | 65 |
| B | 66 |
| … | … |
Важно помнить, что каждая кодировка может использовать разное количество байт для представления символа. Например, в ASCII каждый символ занимает 1 байт, в UTF-8 — от 1 до 4 байт, в UTF-16 — от 2 до 4 байт и т.д.
Для успешной работы с кодировками в Python необходимо иметь хорошее понимание основных концепций и принципов их работы. Это позволяет избежать проблем, связанных с неправильным отображением символов или неправильным считыванием и записью текстовых файлов.