Научные вычисления являются важной составляющей многих современных исследований и приложений. Оптимизация вычислений и ускорение их выполнения имеют решающее значение для получения результатов в разумные сроки. И здесь на помощь приходит использование Python.
Индивидуальный график
Индивидуальный график

Индивидуальный график
Python – высокоуровневый язык программирования, но его скорость выполнения, особенно при работе с большими объемами данных, может быть существенно улучшена с помощью оптимизации. Множество методов оптимизации позволяют сократить время выполнения программного кода, ускоряя таким образом процесс вычислений.
Однако оптимизация только по процессору не всегда даёт ощутимый результат. Именно здесь на сцену выходят параллельные вычисления. Параллельное выполнение задач позволяет использовать одновременно несколько ядер процессора или даже несколько процессоров для ускорения работы. Код в Python, который может выполняться параллельно, может использовать многопоточность или быстродействие графических процессоров (GPU) для выполнения вычислений еще быстрее.
Вычисления в Python могут быть представлены в виде нескольких потоков и параллельно выполняться на разных ядрах, что позволяет достичь значительного ускорения операций.
Таким образом, оптимизация и параллельные вычисления становятся важным инструментом для эффективной работы с большим объемом данных и сложными математическими моделями. Использование Python позволяет максимально увеличить производительность вычислений, сохраняя при этом достаточно простой и удобный синтаксис кода.
Ускорение научных вычислений с помощью Python: оптимизация и параллельные вычисления
Использование Python для научных вычислений позволяет ускорить процесс обработки и анализа данных. Оптимизация кода и параллельные вычисления являются ключевыми инструментами для достижения эффективности и быстроты в вычислениях.
Оптимизация кода
Оптимизация кода в Python позволяет улучшить производительность программы путем устранения узких мест и использования более эффективных алгоритмов. Некоторые способы оптимизации включают:
- Использование встроенных функций Python вместо циклов
- Использование генераторов вместо списков
- Избегание повторного вычисления одних и тех же значений
Параллельные вычисления
Параллельные вычисления позволяют распределить вычислительную нагрузку между несколькими процессорами и ядрами компьютера. В Python для этого существуют различные библиотеки, такие как multiprocessing и concurrent.futures. Некоторые подходы к параллельным вычислениям в Python включают:
- Распараллеливание циклов с помощью библиотеки concurrent.futures
- Использование многопоточности или многопроцессорности при выполнении задач
Использование Python для научных вычислений
Python является одним из наиболее популярных языков программирования для научных вычислений. Множество библиотек, таких как NumPy, SciPy и Pandas, встроенных в Python, предоставляют мощные инструменты для работы с большими массивами данных, выполнения математических и статистических операций, а также для построения графиков и визуализации результатов.
Заключение

Ускорение научных вычислений с помощью Python осуществляется применением оптимизации кода и параллельных вычислений. Оптимизация кода позволяет улучшить производительность программы, а параллельные вычисления позволяют эффективно использовать ресурсы компьютера. Использование библиотек Python способствует удобству и эффективности в научных вычислениях.
Оптимизация программного кода для улучшения скорости вычислений
Оптимизация программного кода – это процесс внесения изменений в программу с целью улучшения ее производительности. При работе с научными вычислениями в языке программирования Python появляется необходимость в оптимизации кода для ускорения вычислений.
Одним из методов ускорения вычислений является оптимизация кода. Она позволяет устранить узкие места в программе и улучшить ее эффективность. В результате оптимизации кода можно сократить время выполнения программы и снизить нагрузку на систему.
Использование встроенных функций и библиотек – один из подходов к оптимизации кода. Python предлагает широкий набор встроенных функций и библиотек, которые позволяют ускорить выполнение программы. Например, можно использовать встроенную функцию sum() для быстрой суммирования элементов списка или библиотеку NumPy для работы с многомерными массивами.
Векторизация – техника оптимизации кода, которая заключается в выполнении операций над массивами данных вместо итерации по элементам. В языке Python для векторизации можно использовать библиотеку NumPy. Такой подход позволяет существенно увеличить скорость вычислений.
Использование распараллеливания – еще один метод оптимизации кода. В языке Python есть возможность выполнять вычисления параллельно с помощью библиотеки multiprocessing. Эта техника позволяет распределить вычисления по нескольким ядрам процессора и сократить время выполнения программы.
Профилирование кода – важный шаг при оптимизации программного кода. Профилирование позволяет выявить узкие места в программе и определить, где потребляется большая часть времени. С помощью профилирования можно оптимизировать и ускорить наиболее ресурсоемкие части кода.
В итоге, оптимизация программного кода позволяет существенно ускорить вычисления при работе с научными задачами в Python. Путем использования встроенных функций и библиотек, векторизации, распараллеливания и профилирования кода можно добиться значительного улучшения скорости вычислений.
Идентификация узких мест в коде
Для ускорения научных вычислений с использованием Python необходимо проводить оптимизацию кода. Одним из этапов этой оптимизации является идентификация узких мест в коде, то есть мест, где происходит наиболее значительное замедление процесса вычислений.
Идентификация узких мест в коде может быть выполнена с помощью различных инструментов и методов. Один из таких инструментов — профилирование кода. При профилировании собирается информация о времени выполнения каждой строки кода, что позволяет выявить участки, которые занимают больше всего времени.
Другим способом идентификации узких мест является использование специализированных библиотек для профилирования и анализа кода. Такие библиотеки позволяют более детально исследовать производительность кода, выявлять проблемные места и предлагать оптимизации.
При идентификации узких мест необходимо обратить внимание на следующие факторы:
- Время выполнения: участки кода, которые занимают наибольшее время выполнения, могут быть потенциальными узкими местами;
- Частота вызова: код, который вызывается внутри цикла или множество раз, может также быть узким местом, даже если его время выполнения невелико;
- Использование ресурсов: код, который использует большое количество памяти или процессорного времени, может замедлять работу всей системы;
- Операции ввода-вывода: код, который часто выполняет операции ввода-вывода (например, чтение или запись данных на диск), может быть узким местом из-за медленного доступа к файловой системе.
После идентификации узких мест необходимо провести оптимизацию кода, например, путем использования более эффективных алгоритмов, векторизации операций или внесения изменений в архитектуру вычислений.
| Участок кода | Время выполнения, сек | Частота вызова |
|---|---|---|
| Функция A | 5.342 | 2345 |
| Функция B | 2.987 | 541 |
| Функция C | 1.235 | 1423 |
В итоге, идентификация узких мест в коде является важным шагом при ускорении научных вычислений с помощью Python. Найденные узкие места дают возможность провести оптимизацию кода, чтобы повысить скорость и эффективность вычислений.
Применение векторизации для оптимизации вычислений

Одним из эффективных способов ускорить вычисления в научных кодах на Python является использование векторизации. Векторизация позволяет выполнять операции над массивами данных, а не над отдельными элементами. Это особенно полезно при работе с большими объемами данных, так как позволяет сократить количество выполненных инструкций и увеличить производительность программы.
Для применения векторизации в Python можно использовать библиотеки, такие как numpy или pandas. Они предоставляют удобные инструменты для работы с массивами данных и выполняют операции сразу над всеми элементами массива. Например, с помощью numpy можно выполнять математические операции, применять функции к массивам, а также выполнять операции сравнения и логические операции.
При использовании векторизации важно учесть особенности работы с массивами. Векторизованный код может быть более эффективным, но он может потребовать больше памяти для хранения массива данных. Кроме того, не все операции могут быть векторизованы, поэтому при написании кода нужно учитывать ограничения и возможности выбранной библиотеки.
Применение векторизации в научных вычислениях с помощью Python позволяет значительно ускорить выполнение программы. Благодаря возможности параллельного выполнения операций над большими массивами данных, можно достичь высокой производительности и сократить время, затрачиваемое на вычисления.
Использование библиотек для избегания медленных операций
Одним из ключевых аспектов ускорения научных вычислений с помощью Python является оптимизация кода и избегание медленных операций. Для этого существуют специализированные библиотеки, которые предоставляют эффективные реализации некоторых операций и алгоритмов.
Одной из таких библиотек является NumPy, которая предоставляет массивы и функции для работы с ними. Массивы NumPy являются гораздо более эффективными по сравнению со встроенными списками Python, особенно при выполнении численных операций. Благодаря использованию более компактного представления данных и оптимизированных алгоритмов, операции с массивами NumPy выполняются значительно быстрее.
Еще одной полезной библиотекой является pandas, которая предоставляет эффективные структуры данных и операции над ними. Благодаря использованию специализированных структур данных, таких как DataFrame, pandas позволяет обрабатывать большие объемы данных быстрее, чем стандартные структуры данных Python.
Для выполнения параллельных вычислений и распределенных вычислений можно использовать библиотеки, такие как multiprocessing и mpi4py. Они предоставляют инструменты для создания и управления параллельными задачами, а также обмена данными между процессами или узлами вычислительного кластера.
Для оптимизации кода и повышения его производительности также можно использовать различные инструменты для профилирования, такие как cProfile или line_profiler. Они позволяют выявить узкие места в коде и оптимизировать их для достижения наилучшей производительности.
Использование специализированных библиотек для избегания медленных операций является важным аспектом ускорения научных вычислений с помощью Python. Эти библиотеки предоставляют эффективные реализации операций и алгоритмов, что позволяет значительно ускорить выполнение вычислений и повысить производительность кода.
Применение параллельных вычислений для повышения эффективности
Одним из основных способов улучшения производительности научных вычислений является оптимизация кода. Однако, в некоторых случаях оптимизация может иметь ограниченный эффект, особенно при работе с большими объемами данных или сложными алгоритмами. В таких ситуациях использование параллельных вычислений может значительно ускорить процесс.
Python является мощным инструментом для научных вычислений благодаря своим богатым библиотекам и простому синтаксису. Однако, по умолчанию Python выполняет вычисления последовательно, используя только одно ядро процессора. Это может быть неэффективно при работе с большими объемами данных или сложными вычислительными задачами.
Для ускорения вычислений в Python можно использовать параллельные вычисления. Параллельные вычисления позволяют разделить задачу на несколько частей и выполнять их одновременно на разных ядрах процессора. Это позволяет увеличить общую производительность и сократить время выполнения задачи.
Существует несколько способов реализации параллельных вычислений в Python. Один из них — использование модуля multiprocessing. Модуль multiprocessing предоставляет функционал для создания и управления параллельными процессами. С его помощью можно легко разделить задачу на подзадачи и распределить их по доступным ядрам процессора.
Кроме модуля multiprocessing, существует также модуль concurrent.futures, который предоставляет удобный интерфейс для параллельных вычислений. Он позволяет работать с пулом потоков или процессов, а также выполнять асинхронные задачи.
Важно отметить, что использование параллельных вычислений требует рассмотрения некоторых особенностей. Например, не все задачи могут быть эффективно распараллелены, и результаты могут зависеть от специфики алгоритма или структуры данных. Также необходимо учесть, что параллельные вычисления требуют больше ресурсов процессора, поэтому могут возникать проблемы с памятью или производительностью.
Выводя бенефиты и риски в применении параллельных вычислений для повышения эффективности кода научных вычислений на Python — можно сделать вывод, что при правильном применении эта техника может значительно ускорить выполнение сложных задач и повысить общую производительность. Однако, перед применением параллельных вычислений необходимо тщательно изучить свою задачу, определить возможность и эффективность распараллеливания, а также учесть ограничения и особенности использования данной техники.
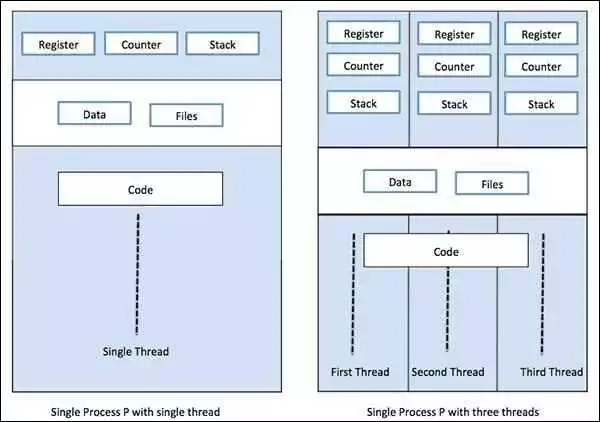
Распараллеливание задач на несколько ядер процессора

Распараллеливание задач – это одна из ключевых стратегий для оптимизации вычислений. Оптимизация вычислений позволяет повысить производительность программного кода, ускорить работу алгоритмов и эффективнее использовать ресурсы процессора.
Python — это один из самых популярных языков программирования для научных вычислений. Его удобство и богатый функционал позволяют легко реализовывать вычислительные задачи. Однако для достижения максимальной производительности часто требуется использование параллельных вычислений.
С помощью Python можно реализовать распараллеливание задач на несколько ядер процессора. Для этого существуют различные библиотеки и инструменты, такие как multiprocessing, threading и asyncio. Каждый из них имеет свои особенности и применяется в зависимости от типа задачи и требуемой степени параллелизма.
Использование многопоточности и многопроцессорности позволяет распараллелить выполнение кода на несколько потоков или процессов, что позволяет параллельно выполнять несколько вычислительных задач. В результате, время выполнения программы сокращается, что приводит к ускорению работы и повышению эффективности алгоритма.
Однако при использовании параллельных вычислений необходимо учитывать возможность возникновения гонок данных и проблем с синхронизацией. Необходимо правильно организовать разделение данных и управление доступом к ним, чтобы избежать ошибок и некорректных результатов.
Плюсы использования распараллеливания задач на несколько ядер процессора в Python:
- Ускорение выполнения кода и повышение производительности программы.
- Эффективное использование ресурсов процессора.
- Возможность обработки больших объемов данных.
- Параллельное выполнение нескольких вычислительных задач.
Однако при использовании параллельных вычислений необходимо также учитывать потерю части вычислительной производительности на организацию параллельной работы и синхронизацию данных. Поэтому перед применением параллельных вычислений рекомендуется проводить анализ задачи и оценивать потенциальное ускорение и эффективность при использовании распараллеливания.