Регулярные выражения — мощный инструмент для работы с текстом в языке программирования Python. Они позволяют находить и обрабатывать определенные шаблоны символов в строках. В этом полном руководстве рассмотрим все аспекты использования регулярных выражений в Python, начиная с основных понятий и заканчивая сложными примерами и наиболее полезными функциями.

Индивидуальный график
Индивидуальный график
Индивидуальный график
Python — один из самых популярных языков программирования, который обладает богатым набором встроенных функций и библиотек. Регулярные выражения входят в стандартную библиотеку Python и являются неотъемлемой частью его функционала. Они позволяют эффективно работать с текстом, выполнять поиск, замену и извлечение данных из строк.
В этом руководстве вы узнаете, как создать регулярные выражения в Python, как применять их для поиска и замены текста, а также как использовать различные функции и методы для работы с регулярными выражениями. Вы также узнаете о некоторых продвинутых возможностях, таких как группировка, квантификаторы, альтернативы и многое другое.
Полное руководство по использованию регулярных выражений в Python для обработки текста
Регулярные выражения — мощный инструмент для обработки и анализа текста в Python. Они позволяют искать, извлекать и изменять строки с помощью специальных шаблонов.
В данном руководстве мы рассмотрим основные принципы работы с регулярными выражениями в Python и приведем примеры их применения.
Основные функции модуля re
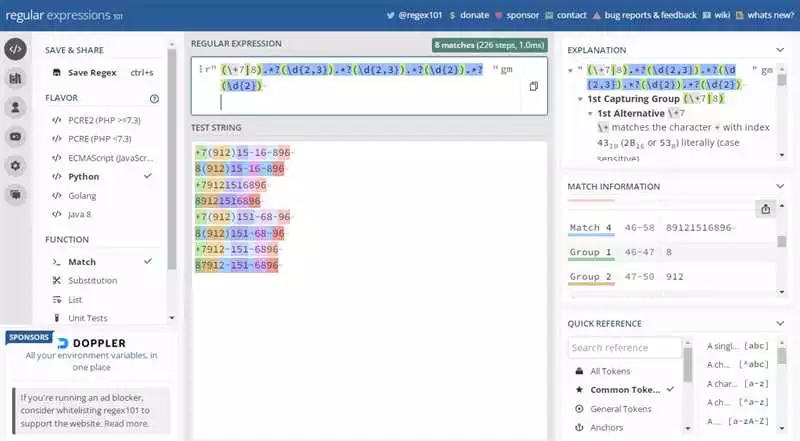
В Python для работы с регулярными выражениями используется модуль re. Он предоставляет набор функций для работы с текстом.
- re.search() — поиск первого совпадения с шаблоном
- re.match() — поиск совпадения в начале строки
- re.findall() — поиск всех совпадений в строке
- re.sub() — замена совпадений в строке
Шаблоны и метасимволы

Шаблоны в регулярных выражениях представляют собой последовательности символов, которые определяют правила поиска. В шаблонах можно использовать метасимволы, которые обозначают определенные классы символов.
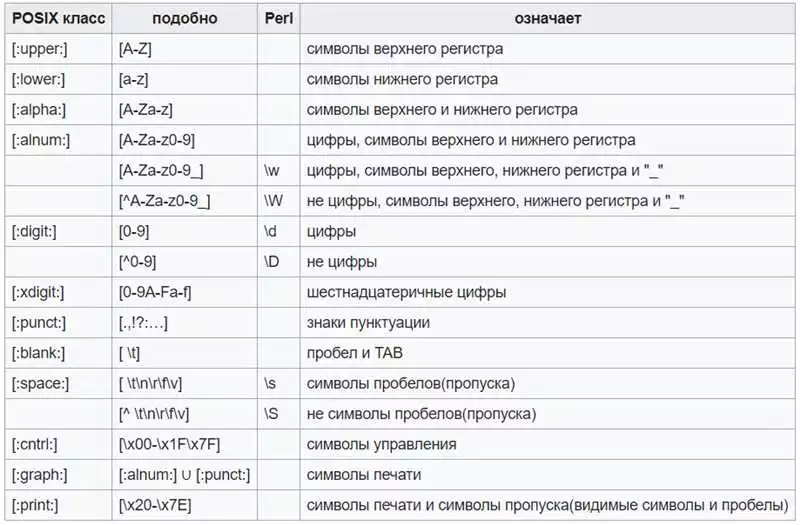
- . — любой символ, кроме новой строки
- \d — одна цифра
- \D — любой символ, кроме цифр
- \w — любой алфавитно-цифровой символ или знак подчеркивания
- \W — любой символ, кроме алфавитно-цифровых символов и знака подчеркивания
- \s — любой пробельный символ
- \S — любой непробельный символ
- \b — граница слова
Примеры использования

Ниже приведены примеры использования регулярных выражений в Python для обработки текста.
- Поиск слова «регулярных» в строке:
- Извлечение всех чисел из строки:
- Замена всех гласных букв на символ «*»:
import re
text = "Регулярные выражения - мощный инструмент"
match = re.search("регулярных", text)
if match:
print("Слово 'регулярных' найдено в тексте.")
else:
print("Слово 'регулярных' не найдено в тексте.")
import re
text = "В числах 1, 2, 3, 4, 5 скрыты секреты."
numbers = re.findall("\d", text)
print("Найденные числа:", numbers)
import re
text = "Привет, мир!"
new_text = re.sub("[аеёиоуыэюя]", "*", text)
print("Измененный текст:", new_text)
В данном руководстве были рассмотрены основные принципы работы с регулярными выражениями в Python. Подробное изучение регулярных выражений позволит вам эффективно обрабатывать и анализировать текстовые данные.
Сопоставление и поиск текста
В полное руководство по использованию регулярных выражений в Python для обработки текста, мы рассмотрим, как использовать регулярные выражения в Python для сопоставления и поиска текста.
Регулярные выражения — это шаблоны, которые позволяют сопоставлять и искать определенный текст в строке. Они состоят из уникального набора символов и метасимволов, которые позволяют указывать различные правила для сопоставления и поиска.
Python имеет встроенный модуль re, который предоставляет функции и методы для работы с регулярными выражениями. Мы можем использовать этот модуль для выполнения различных операций, таких как:
- Проверка, соответствует ли строка определенному шаблону
- Нахождение всех совпадений с заданным шаблоном в строке
- Замена совпадений заданным текстом
Для использования регулярных выражений в Python сначала необходимо импортировать модуль re. Затем мы можем использовать функции и методы этого модуля для работы с регулярными выражениями.
Вот некоторые из основных функций и методов, которые мы будем использовать при работе с регулярными выражениями в Python:
- re.search() — ищет первое совпадение с заданным шаблоном в строке
- re.match() — ищет совпадение с заданным шаблоном в начале строки
- re.findall() — находит все совпадения с заданным шаблоном в строке и возвращает их в виде списка
- re.sub() — заменяет все совпадения с заданным шаблоном в строке на указанный текст
Эти функции и методы предоставляют нам мощные инструменты для обработки текста с помощью регулярных выражений в Python.
Что такое регулярные выражения?
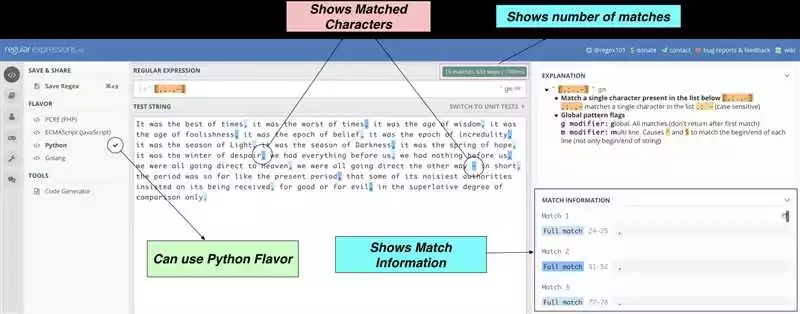
Регулярные выражения — это мощный инструмент для обработки текста в Python и других языках программирования. Они позволяют искать, извлекать и изменять подстроки в тексте с использованием специальных шаблонов.
В Python регулярные выражения встроены в модуль re. Они являются независимым языком синтаксических конструкций, которые позволяют задавать шаблоны для поиска и манипуляций с текстом.
Регулярные выражения могут выполнять различные операции, такие как:
- Поиск шаблона в тексте
- Извлечение подстроки, соответствующей шаблону
- Замена подстроки, соответствующей шаблону, на другую строку
- Разбиение строки на части с использованием шаблона
- Проверка соответствия строки шаблону
Регулярные выражения содержат несколько специальных символов и конструкций, которые могут быть использованы для создания шаблонов. Для начала работы с регулярными выражениями в Python нужно импортировать модуль re.
Например:
import re
Полное руководство по использованию регулярных выражений в Python доступно в официальной документации по модулю re.
С использованием регулярных выражений в Python вы можете повысить эффективность обработки текста, упростить задачи поиска и изменения текста и сделать ваш код более гибким.
Примеры использования регулярных выражений

В данном разделе представлены примеры использования регулярных выражений в Python для обработки текстовых данных.
-
Поиск слова в тексте:
Для поиска слова в тексте можно использовать следующий код:
import retext = "Это пример текста для поиска."
pattern = r"текст"
match = re.search(pattern, text)
if match:
print("Слово найдено")
else:
print("Слово не найдено")
-
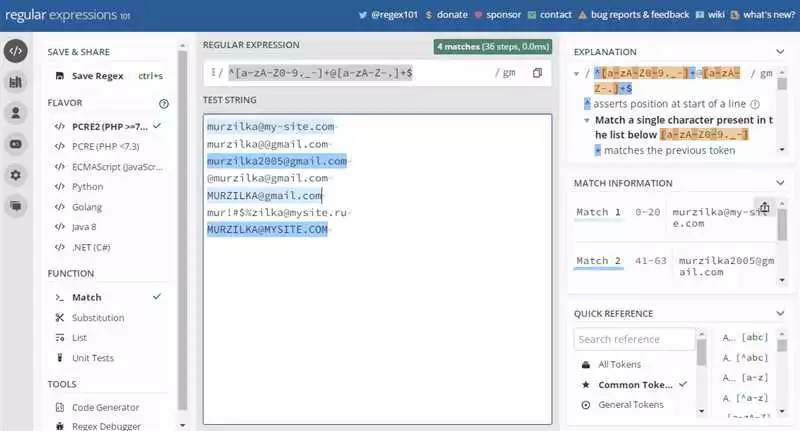
Проверка формата email:
Для проверки формата email можно использовать следующий код:
import reemail = "example@example.com"
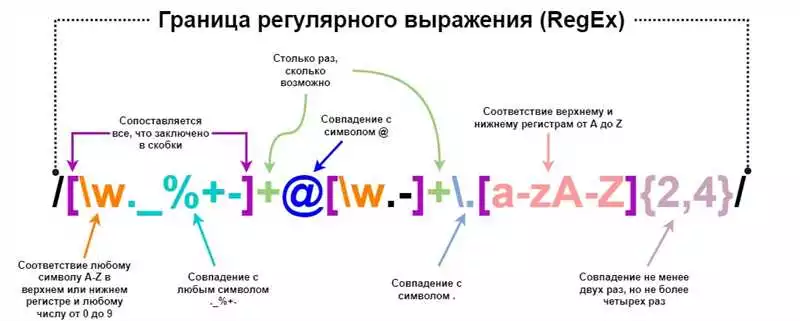
pattern = r"^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$"
if re.match(pattern, email):
print("Email валиден")
else:
print("Email невалиден")
-
Замена подстроки в тексте:
Для замены подстроки в тексте можно использовать следующий код:
import retext = "Это пример текста для замены."
pattern = r"текст"
replacement = "строка"
new_text = re.sub(pattern, replacement, text)
print(new_text)
-
Разбиение текста на предложения:
Для разбиения текста на предложения можно использовать следующий код:
import retext = "Это пример текста. Текст содержит два предложения. Вот и все."
pattern = r"[.!?]"
sentences = re.split(pattern, text)
for sentence in sentences:
print(sentence)
Это только небольшая часть возможностей регулярных выражений в Python. Полное руководство по использованию регулярных выражений в Python можно найти в официальной документации.
Регулярные выражения
Регулярные выражения (Regular Expressions) — это мощный инструмент для обработки и поиска текста. В Python существует полное руководство по использованию регулярных выражений для различных задач.
Для работы с регулярными выражениями в Python используется модуль re. Этот модуль содержит набор функций и методов, которые позволяют выполнять различные операции с текстом, основываясь на заданных шаблонах.
Регулярные выражения состоят из символов и специальных последовательностей символов, которые образуют шаблон поиска. С помощью регулярных выражений можно искать, заменять и разделять текст на основании определенных правил.
Основные операции, которые можно выполнять с помощью регулярных выражений:
- Поиск подстроки с заданным шаблоном
- Замена одной подстроки на другую
- Разделение текста на отдельные элементы
- Проверка соответствия текста заданному шаблону
Пример использования регулярных выражений в Python:
import re
# Поиск подстроки с заданным шаблоном
pattern = r'\b\w+\b'
text = "Regular expressions are powerful tools for processing text"
result = re.findall(pattern, text)
print(result)
# Output: ['Regular', 'expressions', 'are', 'powerful', 'tools', 'for', 'processing', 'text']
В данном примере мы использовали функцию re.findall() для поиска всех слов в тексте. Паттерн r’\b\w+\b’ задает шаблон поиска, в котором \b обозначает границу слова, а \w+ обозначает один или более символов слова.
Регулярные выражения в Python предоставляют широкие возможности для работы с текстом. Использование регулярных выражений может значительно упростить обработку и поиск информации в больших объемах текста.
При использовании регулярных выражений важно учитывать особенности синтаксиса и правила написания шаблонов, чтобы достичь нужной функциональности. Но после того, как вы освоите основы регулярных выражений в Python, вы сможете легко и эффективно решать множество задач по обработке текста.
Основные конструкции регулярных выражений
Регулярные выражения (Regex) — это мощный инструмент для обработки и поиска текста в Python. Они позволяют искать соответствующие шаблоны символов и фраз в строках и выполнять различные операции с найденными совпадениями.
В Python модуль re предоставляет функции и методы для работы с регулярными выражениями. Он позволяет найти совпадения, заменить части строки и выполнить другие операции, используя шаблоны.
Ниже приведены основные конструкции, используемые в регулярных выражениях:
- Символы — символы представляют собой основные строительные блоки регулярных выражений. Например, символ «a» соответствует букве «a» в тексте. Существуют также специальные символы, такие как «.», который соответствует любому символу, кроме новой строки, и «\d», который соответствует любой цифре.
- Квантификаторы — квантификаторы определяют количество совпадений символов или фраз. Например, «*» указывает, что предыдущий символ или фраза может быть повторена ноль или более раз, а «+» означает, что предыдущий символ или фраза должны быть повторены один или более раз.
- Группировка — группировка позволяет объединять символы или фразы, чтобы применять к ним операции. Например, «(abc)» создает группу из символов «a», «b» и «c», которая может быть использована вместе с квантификаторами и другими операциями.
- Альтернативы — альтернативы указывают на несколько вариантов символов или фраз, которые могут быть найдены. Например, «a|b» означает, что может быть найдена либо буква «a», либо буква «b».
- Начало и конец строки — символы «^» и «$» используются для указания начала и конца строки соответственно. Например, «^abc» означает, что строка должна начинаться с символов «a», «b» и «c».
- Специальные последовательности — специальные последовательности представляют собой комбинации символов, которые имеют определенные значения. Например, «\d» соответствует любой цифре, а «\s» соответствует любому пробельному символу.
Это лишь некоторые из основных конструкций регулярных выражений, которые могут быть использованы в Python для обработки и поиска текста. При изучении регулярных выражений полезно ознакомиться с документацией модуля re и провести практические упражнения для лучшего понимания их работы.
Символы и метасимволы

Регулярные выражения — это мощный инструмент в Python для обработки и поиска текста. Полное руководство по использованию регулярных выражений в Python дает возможность более гибко и эффективно работать с текстовыми данными.
В регулярных выражениях существуют специальные символы, называемые метасимволами, которые служат для задания шаблонов поиска. Некоторые из наиболее часто используемых метасимволов:
- ^ — соответствует началу строки. Например, выражение ‘^Python’ найдет все строки, которые начинаются с слова «Python».
- $ — соответствует концу строки. Например, выражение ‘Python$’ найдет все строки, которые заканчиваются на слово «Python».
- . — соответствует любому символу, кроме символа новой строки. Например, выражение ‘P.t’ найдет все строки, в которых между символами «P» и «t» находится один любой символ.
- [ ] — определяет класс символов. Например, выражение ‘[0-9]’ найдет все строки, содержащие цифры от 0 до 9.
- * — указывает, что предыдущий символ или группа символов может повторяться любое количество раз (включая ноль раз). Например, выражение ‘ab*’ найдет строки, в которых после символа «a» может быть любое количество символов «b».
- + — указывает, что предыдущий символ или группа символов должны повторяться один или более раз. Например, выражение ‘ab+’ найдет строки, в которых после символа «a» должен быть хотя бы один символ «b».
- ? — указывает, что предыдущий символ или группа символов может встретиться один раз или не встречаться вообще. Например, выражение ‘ab?’ найдет строки, в которых после символа «a» может быть необязательный символ «b».
Это всего лишь некоторые из метасимволов, которые можно использовать в регулярных выражениях в Python. Все они имеют различные функции и могут быть комбинированы, чтобы создавать более сложные шаблоны поиска.
Более подробную информацию о символах и метасимволах регулярных выражений в Python можно найти в официальной документации.