Обучение с подкреплением – одна из самых мощных и перспективных областей машинного обучения. Она позволяет разработать алгоритмы, способные самостоятельно изучать и принимать решения в динамическом окружении. Основное отличие обучения с подкреплением от обычных машинных обучающих систем состоит в том, что модели обучаются не на предварительно размеченных данных, а через взаимодействие с окружающей средой.

Индивидуальный график
Индивидуальный график
Индивидуальный график
PyTorch – одна из наиболее популярных и гибких библиотек для глубинного обучения. Она предоставляет широкий набор инструментов для создания и обучения моделей. С помощью PyTorch можно реализовать сложные алгоритмы обучения с подкреплением, используя базовые концепции, такие как марковские процессы принятия решений, Q-обучение и многое другое.
Обучение с подкреплением с помощью PyTorch позволяет решать широкий спектр сложных задач, от игровых симуляций до робототехники и финансового моделирования. Это невероятно полезный инструмент для исследования и разработки интеллектуальных систем, способных принимать оптимальные решения в меняющихся условиях.
В данной статье мы рассмотрим основные концепции обучения с подкреплением и применение библиотеки PyTorch для создания и обучения моделей. Рассмотрим такие алгоритмы, как Q-обучение, policy gradients и deep Q-networks. Узнаем, как применить эти алгоритмы для решения различных задач и как достичь высокой производительности и эффективности обучения.
Обучение с подкреплением с помощью PyTorch: основные концепции и сложные алгоритмы
Обучение с подкреплением — это раздел машинного обучения, где агент обучается принимать решения в среде, чтобы максимизировать суммарную награду. В этом процессе используется сильная связь между действиями агента и результатами, полученными средой.
PyTorch — это популярная библиотека глубокого обучения, которая также предоставляет функциональность для разработки алгоритмов обучения с подкреплением. С помощью PyTorch можно создавать и обучать нейронные сети, а также использовать различные алгоритмы обучения с подкреплением.
Для понимания обучения с подкреплением с помощью PyTorch полезно ознакомиться с базовыми концепциями:
- Среда: это внешний мир, в котором действует агент. Среда может быть физической или виртуальной и иметь различные свойства и правила.
- Агент: это искусственный интеллект, который принимает решения в заданной среде. Агент может наблюдать текущее состояние среды и совершать действия, влияющие на состояние среды.
- Состояние: это описание текущего состояния среды, которое агент может наблюдать. Состояние может быть полностью наблюдаемым или частично наблюдаемым.
- Действие: это выбор агента из доступных действий, которое он может совершить в текущем состоянии среды.
- Награда: это числовая оценка, которую агент получает от среды за совершенное действие. Цель агента — максимизировать суммарную награду.
Существует несколько сложных алгоритмов обучения с подкреплением, которые можно реализовать с помощью PyTorch:
- Q-обучение: это алгоритм, который основан на оценке функции Q — функции ценности. Агент обучается выбирать действия, максимизирующие ожидаемую суммарную награду, используя оценку функции Q.
- Алгоритмы глубокого Q-обучения: это расширение Q-обучения с использованием глубоких нейронных сетей. Агент обучается непосредственно на основе высокоуровневого представления состояний среды.
- Политика градиентов: это алгоритм, который изучает оптимальную политику, используя методы оптимизации градиента. Агент обучается прямо на основе политики, минимизируя функцию потерь.
- Прокладывание маршрута: это алгоритм, который изучает оптимальный путь в заданной среде, чтобы достичь заранее определенной цели. Агент обучается находить наилучший маршрут, минимизируя функцию стоимости.
Обучение с подкреплением с помощью PyTorch предоставляет мощный инструментарий для создания и обучения агентов, которые могут действовать в различных средах и достигать заданных целей. Использование PyTorch позволяет разработчикам быстро и эффективно реализовывать сложные алгоритмы обучения с подкреплением.
Основные понятия обучения с подкреплением

Обучение с подкреплением — это метод обучения машинного обучения, в котором агент обучается принимать решения в некоторой среде, получая от нее отклик в виде награды или наказания. Главная цель агента — максимизировать суммарную награду, получаемую от среды.
PyTorch — это библиотека машинного обучения, которая предоставляет удобные средства для работы с нейронными сетями и глубоким обучением. С помощью PyTorch можно создавать, обучать и оптимизировать модели глубокого обучения.
Основные концепции обучения с подкреплением:
- Агент — сущность, которая осуществляет принятие решений в среде на основе наблюдений и награды.
- Среда — виртуальное или реальное окружение, в котором действует агент. Среда может быть игровым полем, роботом, физической системой и т. д.
- Состояние — описание среды в конкретный момент времени. Состояние может быть полным или частичным, в зависимости от доступных наблюдений агента.
- Действие — выбор агентом определенной стратегии в ответ на состояние среды. Действия могут быть дискретными или непрерывными.
- Награда — числовая оценка, которую агент получает от среды за свои действия. Цель агента — максимизировать суммарную награду, полученную за определенный период времени.
- Ценность — ожидаемая суммарная награда, которую агент может получить, принимая определенные действия из определенных состояний. Ценность может быть оценена с помощью функции ценности.
- Модель среды — модель, которая аппроксимирует динамику и поведение среды. Модель может быть использована агентом для планирования действий и прогнозирования будущего состояния и награды.
- Эксплорация и эксплуатация — дилемма, которая возникает при принятии решений агентом. Агент может исследовать новые действия и состояния для получения большей информации о среде (эксплорация), или выбирать действия, которые уже известно, что приносят высокую награду (эксплуатация).
Обучение с подкреплением отличается от других методов машинного обучения базовыми понятиями, такими как взаимодействие с окружением и отклик в форме награды. Эти концепции позволяют агенту самостоятельно изучать и принимать решения без непосредственного учителя или метки.
Что такое обучение с подкреплением?
Обучение с подкреплением — это метод обучения машинного обучения, в котором агент (исполнитель) учится принимать решения в среде с целью максимизировать некоторую награду. Этот метод является одним из основных подходов для создания автономных систем, способных обучаться и принимать решения на основе опыта.
Основная идея обучения с подкреплением состоит в том, чтобы агент взаимодействовал с средой, осуществляя различные действия, и получал от неё обратную связь в виде награды или штрафа. Цель агента состоит в том, чтобы научиться выбирать оптимальные действия для достижения максимальной награды в долгосрочной перспективе. Для этого агент должен самостоятельно исследовать среду и найти эффективные стратегии действий.
В контексте PyTorch, обучение с подкреплением реализуется с использованием специальных алгоритмов и моделей, которые позволяют агенту эффективно обучаться на основе опыта. PyTorch предоставляет гибкую и мощную инфраструктуру для создания и обучения моделей глубокого обучения, что делает его идеальным инструментом для реализации задач обучения с подкреплением.
Обучение с подкреплением включает в себя множество концепций и методов, начиная от базовых понятий, таких как состояние, действие, награда и наблюдение, до более сложных алгоритмов, например, Q-обучения и глубокого Q-обучения. Основная цель обучения с подкреплением — это научить агента работать в неизвестном окружении, выбирать оптимальные действия и достигать максимальной награды.
Обучение с подкреплением имеет широкий спектр применений, включая управление роботами, автономную навигацию, игры и финансовые торги. Этот метод является одной из важных областей искусственного интеллекта и продолжает активно развиваться и исследоваться.
Основные принципы обучения с подкреплением
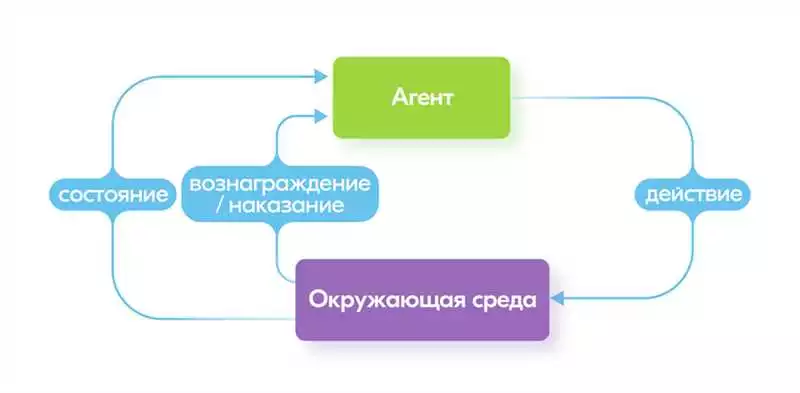
Обучение с подкреплением отличается от других форм обучения тем, что агент обучается путем взаимодействия с окружающей средой и получения положительных или отрицательных подкреплений за свои действия. Базовая концепция обучения с подкреплением состоит в том, что агент стремится максимизировать накопленную награду, находя оптимальную стратегию действий в данной среде.
Для обучения с подкреплением часто используется фреймворк PyTorch, который позволяет удобно создавать и обучать модели и нейронные сети. PyTorch обладает мощными инструментами для работы с графами вычислений и оптимизацией параметров модели.
Процесс обучения с подкреплением включает в себя следующие этапы:
- Определение состояний, действий и награды.
- Создание модели, которая будет принимать состояния и выдавать вероятности действий.
- Использование модели для прогнозирования действий агента в текущем состоянии.
- Выполнение действия в среде и получение награды.
- Обновление модели на основе полученной награды.
Важно отметить, что обучение с подкреплением является итерационным процессом, где агент взаимодействует с средой в течение нескольких эпох, пытаясь улучшить свою стратегию. Целью агента является получение наибольшей возможной награды для достижения поставленной цели.
В итоге, принципы обучения с подкреплением включают в себя определение состояний, действий и награды, создание модели, прогнозирование действий, взаимодействие с средой, получение награды и обновление модели. При использовании фреймворка PyTorch можно удобно реализовывать базовые концепции обучения с подкреплением и решать сложные задачи, используя готовые инструменты и алгоритмы.
Роли агента и среды в обучении с подкреплением

В обучении с подкреплением агент является основным участником процесса обучения. Он находится в состоянии взаимодействия со средой и принимает решения на основе получаемых от нее наград. Агент может использовать различные алгоритмы и стратегии для максимизации собранной награды.
Среда, в свою очередь, представляет собой окружение, в котором происходит взаимодействие агента с внешним миром. Это может быть, например, виртуальный мир в компьютерной игре или модель реальной жизненной ситуации. Среда определяет состояния, в которых может находиться агент, а также набор доступных действий, которые агент может предпринимать.
Основная цель обучения с подкреплением состоит в том, чтобы агент научился выбирать оптимальные действия в каждом состоянии с целью максимизации суммарной награды от среды. Для достижения этой цели агент может использовать базовые алгоритмы обучения с подкреплением, которые реализуют стратегии выбора действий, а также методы обучения и оценки функции ценности состояний и действий.
PyTorch — это популярный фреймворк для глубокого обучения, который предоставляет удобные инструменты для реализации алгоритмов обучения с подкреплением. С его помощью можно создавать и обучать нейронные сети, определять функцию награды и реализовывать различные алгоритмы оптимизации.
Обучение с подкреплением с помощью PyTorch открывает широкие возможности для исследования и разработки новых методов и моделей в области искусственного интеллекта. Оно позволяет создавать агентов, способных эффективно решать сложные задачи, требующие принятия решений в реальном времени и участия в долгосрочном планировании.
Применение PyTorch в обучении с подкреплением
Обучение с подкреплением (reinforcement learning) является одной из базовых областей машинного обучения, которая занимается разработкой алгоритмов, позволяющих агенту осуществлять принятие решений и оптимизировать свое поведение на основе получаемых наград.
PyTorch — это открытая библиотека машинного обучения, которая предоставляет возможность эффективно реализовывать и обучать различные модели глубокого обучения. С помощью PyTorch также можно разрабатывать и обучать алгоритмы обучения с подкреплением.
PyTorch предоставляет набор базовых функций и классов, которые позволяют легко описывать и обучать модели обучения с подкреплением. Например, такие базовые классы, как nn.Module и optim.Optimizer, позволяют удобно описывать структуру и оптимизацию моделей.
В обучении с подкреплением, обычно агент взаимодействует с окружением через последовательность действий и наблюдений. PyTorch предоставляет возможность эффективно хранить и обрабатывать эти данные с использованием своих тензорных операций.
Одним из ключевых понятий в обучении с подкреплением является функция награды, которая определяет цель обучения и оценивает полезность различных действий. PyTorch позволяет легко определить и вычислить функцию награды для обучаемого агента.
В PyTorch также доступны различные алгоритмы обучения с подкреплением, такие как Q-learning и Policy Gradient, которые можно использовать для решения задач, связанных с обучением с подкреплением.
Кроме того, PyTorch предоставляет возможность использования графического процессора (GPU), что позволяет ускорить обучение алгоритмов обучения с подкреплением и улучшить их производительность.
В итоге, с использованием PyTorch можно эффективно разрабатывать и обучать алгоритмы обучения с подкреплением, до значительно повышая их производительность и качество.
Преимущества использования PyTorch
PyTorch является одной из самых популярных и эффективных библиотек для обучения с подкреплением. Он обладает рядом преимуществ перед другими инструментами и позволяет легко и эффективно реализовывать различные алгоритмы обучения с подкреплением.
1. Простота и удобство использования
PyTorch предоставляет простой и интуитивно понятный интерфейс для создания и обучения моделей обучения с подкреплением. Он основан на базовых концепциях и позволяет легко понять, как работает каждый шаг алгоритма.
2. Гибкость
PyTorch предоставляет широкий выбор функций и возможностей, которые позволяют настраивать и адаптировать модели обучения с подкреплением под различные задачи. Он позволяет использовать различные типы нейронных сетей, поддерживает работу с различными типами данных и предоставляет множество оптимизаторов и функций потерь для настройки процесса обучения.
3. Эффективность
PyTorch предоставляет эффективные реализации алгоритмов обучения с подкреплением, которые позволяют добиться высокой производительности в процессе обучения и использования модели. Он использует механизмы автоматического дифференцирования, которые позволяют автоматически вычислять градиенты и обновлять параметры модели во время обучения. Кроме того, PyTorch обладает хорошей масштабируемостью и позволяет эффективно использовать вычислительные ресурсы, включая GPU и распределенные вычисления.
4. Активное сообщество и поддержка
PyTorch имеет активное сообщество разработчиков и пользователей, которые активно поддерживают и развивают эту библиотеку. Существует множество документации, руководств, блогов и примеров кода, которые помогают разработчикам освоить и использовать PyTorch. Также существуют форумы и ресурсы, где можно получить помощь и поддержку в решении возникающих проблем и вопросов.
В целом, использование PyTorch для обучения с подкреплением позволяет легко реализовывать сложные алгоритмы и осуществлять базовые концепции с помощью интуитивно понятного и эффективного инструмента.