Библиотека Pandas – одна из самых популярных библиотек, которая используется для анализа данных в языке программирования Python. Главным образом, она служит для работы с таблицами, что делает ее неотъемлемым инструментом для анализа и обработки данных. С ее помощью можно легко и эффективно осуществлять манипуляции с данными, такие как фильтрация, сортировка, группировка и многое другое.

Индивидуальный график
Индивидуальный график
Индивидуальный график
Основными инструментами библиотеки Pandas являются два класса: DataFrame и Series. DataFrame представляет собой двумерную таблицу данных, а Series – одномерный массив с метками. С помощью этих классов можно выполнить множество операций, таких как чтение и запись данных из различных источников (csv, Excel, SQL), объединение таблиц, добавление и удаление столбцов, агрегирование данных и многое другое.
Для работы с DataFrame и Series в библиотеке Pandas существуют множество методов и атрибутов. Например, с помощью метода head() можно вывести первые несколько строк таблицы, чтобы увидеть структуру данных. Метод describe() позволяет получить сводную статистику по числовым данным. А метод groupby() позволяет группировать данные по определенному столбцу и применять агрегирующие функции к группам.
Библиотека Pandas – мощный инструмент для работы с таблицами на языке Python. Она предоставляет широкий выбор методов и функций для анализа, обработки и визуализации данных. Изучение и использование основных инструментов библиотеки Pandas позволяет упростить работу с таблицами и повысить эффективность работы с данными.
Основные инструменты библиотеки Pandas для работы с таблицами на Python
Библиотека Pandas предоставляет мощные инструменты для работы с таблицами на языке программирования Python. С ее помощью можно легко загружать, преобразовывать, анализировать и визуализировать данные, представленные в виде таблиц.
Ниже приведен список основных инструментов, которые предоставляет библиотека Pandas для работы с таблицами:
- DataFrame: основной объект для представления и работы с данными в виде таблицы. DataFrame предоставляет множество методов для выборки, фильтрации, преобразования и агрегации данных.
- Series: объект, представляющий колонку или столбец данных в таблице. Как и DataFrame, Series также предоставляет множество методов для работы с данными.
- Загрузка данных: библиотека Pandas поддерживает загрузку данных из различных источников, таких как CSV, Excel, SQL БД и других форматов.
- Преобразование данных: Pandas позволяет выполнять различные преобразования данных, такие как изменение типов данных, добавление новых столбцов, объединение и разделение таблиц и т.д.
- Агрегация данных: с помощью Pandas можно легко выполнять агрегацию данных, например, вычисление среднего, суммы, максимума или минимума значений в столбцах.
- Фильтрация данных: библиотека Pandas предоставляет мощные средства для фильтрации данных по заданным условиям, определенным в виде логических выражений.
- Визуализация данных: с помощью библиотеки Pandas можно легко визуализировать данные с помощью построения графиков и диаграмм.
Это лишь некоторые из основных инструментов, которые предоставляет библиотека Pandas для работы с таблицами на Python. Благодаря своему широкому функционалу и интуитивно понятному интерфейсу, Pandas стал одной из самых популярных библиотек для работы с данными в популярном языке программирования Python.
Изучаем принципиальные средства библиотеки Pandas

Библиотека Pandas является одним из основных инструментов для работы с таблицами на языке программирования Python. С помощью Pandas можно легко и эффективно выполнять множество операций с данными, таких как чтение и запись таблиц, фильтрация, сортировка, агрегация и многое другое.
Основные инструменты библиотеки Pandas для работы с таблицами включают:
- Структуры данных DataFrame и Series. DataFrame представляет собой двумерную таблицу данных, а Series — одномерный массив с метками.
- Операции для чтения данных, такие как read_csv() и read_excel(), которые позволяют считывать данные из файлов различных форматов.
- Методы и функции для фильтрации и выборки данных. С помощью .loc и .iloc можно выбирать данные по индексам или условиям.
- Возможности для агрегации и группировки данных. Методы .groupby() и .agg() позволяют суммировать, средствам знака конкретного значения.»,
- «.sort_values() используется для сортировки данных по значениям указанного столбца.
- Возможности для визуализации данных. Библиотека Pandas взаимодействует с другими библиотеками, такими как Matplotlib и Seaborn, для создания графиков и визуализации данных.
Благодаря этим инструментам и функциям, библиотека Pandas стала незаменимым инструментом для работы с таблицами на языке Python. Ее простота использования и возможности делают ее идеальным выбором для анализа данных и работы с большими наборами данных.
Основные инструменты Pandas
Библиотека Pandas — мощный инструмент для работы с таблицами и данными на языке программирования Python. Она предоставляет широкие возможности для обработки, анализа и визуализации данных.
При работе с таблицами в Pandas используются основные структуры данных: DataFrame и Series. DataFrame представляет собой двумерную таблицу с данными, а Series — одномерную структуру данных, похожую на столбец в таблице.
Основные инструменты Pandas для работы с таблицами:
- Загрузка данных: с помощью функций pandas.read_csv(), pandas.read_excel() и других можно загрузить данные из различных источников — файлов CSV, Excel, баз данных и т.д.
- Просмотр данных: с помощью функций head(), tail() и sample() можно быстро ознакомиться с содержимым таблицы.
- Фильтрация данных: с помощью оператора [] и функции query() можно отфильтровать таблицу по определенным условиям.
- Сортировка данных: с помощью функций sort_values() и sort_index() можно отсортировать данные в таблице по значениям в столбцах или индексам.
- Группировка данных: с помощью функции groupby() можно группировать данные по значениям в столбцах и применять к ним агрегирующие функции.
- Добавление и удаление столбцов: с помощью оператора [] можно добавить новый столбец в таблицу или удалить существующий.
- Объединение данных: с помощью функций merge() и concat() можно объединить несколько таблиц по определенным ключам или просто соединить их в одну.
- Агрегация данных: с помощью функций sum(), mean(), count() и других можно получить сумму, среднее значение, количество и т.д. по определенным столбцам или группам данных.
- Визуализация данных: с помощью функций plot() и plot.bar() можно визуализировать данные в виде графиков и диаграмм.
C помощью этих основных инструментов Pandas можно эффективно работать с таблицами, выполнять различные операции по обработке и анализу данных, а также проводить визуализацию результатов.
Структура данных DataFrame
В контексте темы «Основные инструменты библиотеки Pandas для работы с таблицами на Python» мы изучаем инструменты для работы с таблицами, а одним из основных инструментов является структура данных DataFrame.
DataFrame представляет собой таблицу с данными, состоящую из строк и столбцов. В таблице можно хранить и анализировать данные различных типов, таких как числа, строки, даты и другие.
Преимущества использования DataFrame:
- Удобная структура для работы с данными.
- Возможность выполнения различных операций с данными, таких как фильтрация, сортировка, агрегация и другие.
- Поддержка множества различных источников данных, таких как CSV файлы, базы данных, эксель файлы и другие.
В таблице DataFrame строки обычно представляют собой отдельные наблюдения или объекты, а столбцы содержат значения соответствующих признаков или переменных.
Пример создания DataFrame:
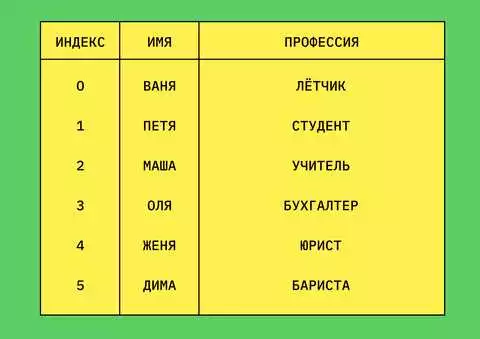
| Имя | Возраст | Город |
|---|---|---|
| Иван | 25 | Москва |
| Анна | 30 | Санкт-Петербург |
| Петр | 35 | Новосибирск |
В данном примере DataFrame содержит три столбца: «Имя», «Возраст» и «Город». Каждая строка представляет собой отдельную запись о человеке.
DataFrame позволяет легко обращаться к данным, проводить анализ и манипулировать ими. Он предоставляет множество методов и функций для работы с данными, таких как чтение данных из файла, фильтрация, сортировка, агрегация, объединение таблиц и многое другое.
Использование DataFrame является одним из основных инструментов библиотеки Pandas для работы с таблицами на Python, и его изучение позволит нам эффективно и удобно работать с данными в таблицах.
Манипуляции с данными
Одним из основных инструментов работы с таблицами в библиотеке Pandas являются методы и функции для манипуляции с данными. Эти инструменты позволяют изучаем фрейм данных, менять его структуру, фильтровать и сортировать данные, а также осуществлять другие операции для получения нужных результатов.
Основные инструменты Pandas для работы с таблицами:
- Методы для просмотра данных:
head()— выводит первые несколько строк таблицыtail()— выводит последние несколько строк таблицыsample()— выводит случайные строки таблицы
- Методы для изменения данных:
rename()— переименовывает столбцы или индексы таблицыdrop()— удаляет столбцы или строки таблицыfillna()— заполняет пропущенные значения в таблице
- Методы для фильтрации данных:
loc[]— фильтрует таблицу по меткам столбцов или индексовiloc[]— фильтрует таблицу по числовым индексам столбцов или индексовquery()— фильтрует таблицу по условию
- Методы для сортировки данных:
sort_values()— сортирует таблицу по значениям столбца или нескольких столбцовsort_index()— сортирует таблицу по индексам столбцов или индексов
Это лишь небольшой перечень основных инструментов библиотеки Pandas для работы с таблицами на языке Python. С их помощью вы сможете легко манипулировать данными, проводить анализ и получать нужные результаты.