Машинное обучение — это раздел искусственного интеллекта, который занимается разработкой и применением алгоритмов для анализа данных. Одним из самых популярных инструментов в этой области является язык программирования Python. Python обладает простым синтаксисом, что делает его идеальным выбором для описания и реализации алгоритмов классификации.

Индивидуальный график
Индивидуальный график
Индивидуальный график
Алгоритмы классификации позволяют автоматически разделять данные на различные категории или классы, основываясь на определенных признаках или характеристиках. Такие алгоритмы находят широкое применение во многих областях — от анализа текстов и изображений до прогнозирования рынка и обнаружения мошенничества.
Python предоставляет различные инструменты и библиотеки, которые упрощают работу с алгоритмами классификации. Одной из таких библиотек является scikit-learn, которая содержит множество реализаций различных алгоритмов.
В этой статье мы погрузимся в мир машинного обучения и классификации данных с помощью Python. Мы рассмотрим основные понятия и термины, связанные с алгоритмами классификации, и покажем, как использовать scikit-learn для создания и обучения модели классификации. Если вы новичок в машинном обучении или уже имеете опыт в этой области, эта статья будет полезной для вас.
Python и машинное обучение: работа с алгоритмами классификации
Машинное обучение — это процесс обучения моделей на основе данных для автоматического извлечения закономерностей и принятия решений без явного программирования. Анализ данных и классификация – важные задачи машинного обучения. В Python существует множество библиотек, которые помогают упростить задачу анализа данных и реализации алгоритмов классификации.
Для начала работы с алгоритмами классификации в Python, необходимо иметь набор данных. Данные должны быть предварительно обработаны и подготовлены для анализа. В Python используется библиотека pandas для работы с данными. Она позволяет импортировать и обрабатывать данные из различных источников.
Следующим шагом является выбор алгоритма классификации. Существует множество алгоритмов, каждый из которых имеет свои особенности и преимущества. Наиболее популярными алгоритмами классификации являются:
- Логистическая регрессия
- Метод k-ближайших соседей (k-NN)
- Метод опорных векторов (SVM)
- Наивный байесовский классификатор
- Решающие деревья
- Случайный лес
- Градиентный бустинг
Python предоставляет мощные библиотеки для реализации этих алгоритмов, такие как scikit-learn. Библиотека scikit-learn содержит множество функций и классов для обучения моделей машинного обучения и выполнения анализа данных.
После выбора алгоритма классификации и подготовки данных, необходимо произвести обучение модели. Для этого в Python можно использовать методы и функции из библиотеки scikit-learn. Обучение модели происходит на основе предоставленных данных, исходя из заданных параметров алгоритма.
После обучения модели можно произвести тестирование на новых данных. Для этого необходимо подготовить тестовый набор данных и передать его в модель для классификации. Модель будет предсказывать класс для каждого объекта в тестовом наборе данных.
В результате работы с алгоритмами классификации в Python можно получить множество полезных результатов, таких как предсказания классов объектов, оценки точности модели и важности признаков.
Python и машинное обучение предоставляют мощные инструменты для работы с алгоритмами классификации. Выбор правильного алгоритма, предварительная обработка данных и обучение модели – ключевые шаги, которые помогут получить точные и надежные результаты при анализе данных.
Python и алгоритмы классификации
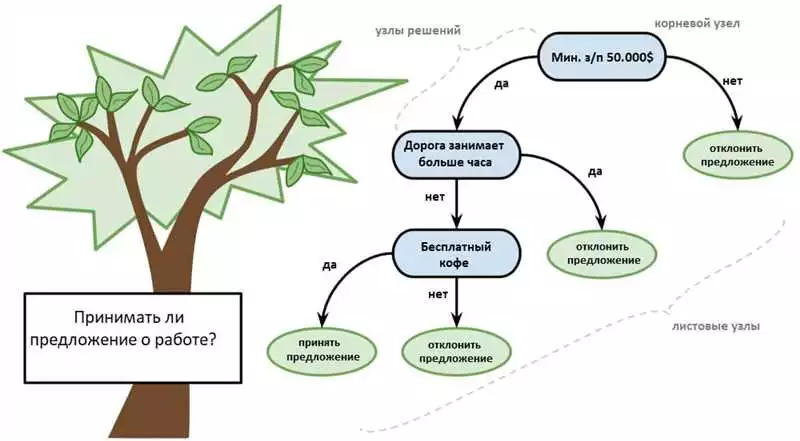
Анализ данных является одной из ключевых областей в машинном обучении. В рамках анализа данных используются различные алгоритмы классификации, которые позволяют автоматически распределять объекты по заранее определенным категориям.
Python — один из наиболее популярных языков программирования, используемых для работы с алгоритмами классификации. Он предоставляет мощные библиотеки, такие как Scikit-learn и TensorFlow, которые содержат широкий спектр алгоритмов классификации.
Для начала работы с алгоритмами классификации в Python, вам необходимо импортировать соответствующие библиотеки:
- Импортирование библиотеки Scikit-learn:
import sklearn
- Импортирование библиотеки TensorFlow:
import tensorflow
После импорта библиотек вы можете начать работу с алгоритмами классификации. Для этого необходимо подготовить данные, разделить их на тренировочный и тестовый наборы и обучить модель с использованием выбранного алгоритма классификации.
Пример кода для обучения модели с использованием алгоритма классификации k-ближайших соседей (k-nearest neighbors) из библиотеки Scikit-learn:
from sklearn.neighbors import KNeighborsClassifier
data = [[2, 4], [3, 5], [1, 3], [4, 6]]
labels = [0, 0, 1, 1]
model = KNeighborsClassifier()
model.fit(data, labels)
test_data = [[5, 7], [2, 3]]
predictions = model.predict(test_data)
print(predictions) # выводит [1, 0]
В приведенном примере мы создали модель на основе алгоритма k-ближайших соседей, обучили ее на тренировочных данных и использовали ее для предсказания меток классов для тестовых данных. Вывод программы показывает предсказанные метки классов для каждого тестового объекта.
Таким образом, Python предоставляет много возможностей для работы с алгоритмами классификации в машинном обучении. Используя соответствующие библиотеки и методы, вы можете провести анализ данных, разделить их на тренировочный и тестовый наборы и обучить модель с использованием различных алгоритмов классификации. Это отличное начало для работы с машинным обучением на Python.
Машинное обучение с использованием Python
Python — один из самых популярных языков программирования для машинного обучения.
Он предоставляет обширный набор инструментов и библиотек, которые облегчают процесс разработки и работу с алгоритмами классификации.
Для начала работы с алгоритмами классификации в Python необходимо иметь набор данных, на которых будут производиться анализы и обучение.
Этот набор данных обычно представляет собой таблицу, где каждая строка соответствует отдельному наблюдению, а каждый столбец — различным признакам или характеристикам.
После получения набора данных, можно приступать к машинному анализу и построению классификационных моделей.
Существует множество алгоритмов классификации в Python, некоторые из которых:
- Логистическая регрессия
- Решающие деревья
- Случайные леса
- Метод ближайших соседей
- Наивный Байесовский классификатор
- Метод опорных векторов (SVM)
Каждый из этих алгоритмов имеет свои преимущества и недостатки, и выбор конкретного алгоритма будет зависеть от поставленной задачи и особенностей данных.
При использовании Python для машинного обучения, необходимо иметь некоторые навыки программирования на языке Python, а также знание основных принципов и техник машинного обучения.
В целом, Python — мощный инструмент для работы с алгоритмами классификации и машинным обучением.
Он позволяет проводить анализ данных, обучать модели, оценивать их качество и применять полученные модели для классификации новых наблюдений.