Несбалансированные данные являются распространенной проблемой в машинном обучении. В таких данных один класс представлен намного меньшим количеством примеров, чем другой. Однако, с помощью метода опорных векторов (SVM) можно эффективно обрабатывать такие данные.

Индивидуальный график
Индивидуальный график
Индивидуальный график
SVM – это мощный алгоритм, который использует векторы для разделения двух классов. Он строит разделяющую гиперплоскость, которая максимально отделяет классы друг от друга. Такой подход позволяет эффективно обрабатывать несбалансированные данные, так как SVM учитывает как больший, так и меньший класс при построении гиперплоскости.
В этом практическом руководстве мы рассмотрим, как обрабатывать несбалансированные данные с помощью метода опорных векторов в Python. Мы рассмотрим несколько вариантов балансировки данных, включая андерсэмплинг и оверсэмплинг, а также покажем, как настроить и обучить модель SVM с помощью библиотеки scikit-learn. Мы также предоставим полезные советы для улучшения результатов классификации и оценки модели на несбалансированных данных.
Готовы начать обрабатывать несбалансированные данные с помощью метода опорных векторов? Продолжайте чтение!
Обработка несбалансированных данных с помощью метода опорных векторов в Python – практическое руководство
Обработка несбалансированных данных является одной из важных задач в анализе данных. Несбалансированные данные возникают, когда один класс данных представлен значительно меньшим количеством примеров по сравнению с другим классом. Это может возникать, например, в задачах детектирования мошеннических транзакций, где мошеннические транзакции составляют лишь небольшую долю от общего числа транзакций.
Метод опорных векторов (Support Vector Machines — SVM) является мощным инструментом для обработки таких несбалансированных данных. Он позволяет обучать модель, которая учитывает различия между классами и дает предпочтение правильной классификации примеров из меньшего класса.
Используя метод опорных векторов для обработки несбалансированных данных, можно улучшить производительность моделей машинного обучения и получить более точные результаты.
Как обрабатывать несбалансированные данные с помощью метода опорных векторов в Python?
Для начала необходимо импортировать необходимые библиотеки:
import pandas as pd
import numpy as np
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import RandomUnderSampler
from imblearn.pipeline import Pipeline
Затем необходимо загрузить данные и разделить их на обучающую и тестовую выборки:
# Загрузка данных
data = pd.read_csv('data.csv')
# Разделение данных на признаки (X) и метки (y)
X = data.drop('target', axis=1)
y = data['target']
# Разделение данных на обучающую и тестовую выборки
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Далее необходимо создать конвейер для обработки несбалансированных данных с помощью метода опорных векторов:
# Создание конвейера
pipeline = Pipeline([
('oversampling', SMOTE(random_state=42)),
('undersampling', RandomUnderSampler(random_state=42)),
('classifier', SVC(random_state=42))
])
# Обучение модели
pipeline.fit(X_train, y_train)
# Предсказание классов на тестовой выборке
y_pred = pipeline.predict(X_test)
Наконец, можно оценить производительность модели с помощью метрик качества:
# Оценка производительности модели
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
В результате выполнения данного руководства вы сможете обрабатывать несбалансированные данные с помощью метода опорных векторов в Python и получать более точные результаты в задачах анализа данных.
Обработка несбалансированных данных с помощью метода опорных векторов в Python
Метод опорных векторов (Support Vector Machines, SVM) является одним из самых популярных алгоритмов машинного обучения, который может быть использован для обработки несбалансированных данных. Несбалансированные данные представляют собой ситуацию, когда количество примеров одного класса значительно превышает количество примеров другого класса. В таких случаях использование классических алгоритмов машинного обучения может привести к смещению результатов в сторону более представленного класса.
Метод опорных векторов позволяет решить эту проблему, применяя специальные стратегии, которые учитывают различную важность и вес примеров разных классов. Вместо простого минимизации ошибки классификации, SVM подбирает разделяющие гиперплоскости, которые наилучшим образом разделяют различные классы данных.
Как обрабатывать несбалансированные данные с помощью метода опорных векторов в Python:
- Проведите балансировку данных, чтобы сбалансировать количество примеров в каждом классе. Для этого можно использовать методы, такие как undersampling (уменьшение выборки меньшего класса), oversampling (увеличение выборки меньшего класса) или синтетическую генерацию данных.
- Разделите данные на обучающую и тестовую выборки с учетом сбалансированности классов.
- Обучите модель метода опорных векторов на обучающей выборке.
- Оцените производительность модели на тестовой выборке с помощью метрик, таких как точность (accuracy), полнота (recall), F-мера (F1-score) и др.
- Если модель показывает недостаточную производительность, можно попробовать варианты модификации SVM, такие как изменение параметров или выбор другого типа ядра.
Использование метода опорных векторов для обработки несбалансированных данных требует внимательного подхода к выбору стратегии балансировки данных и настройке параметров модели. При правильной настройке и интерпретации результатов, SVM может быть очень эффективным инструментом для работы с такими типами данных.
Понятие и проблемы несбалансированных данных
Как мы уже знаем, данные играют решающую роль в анализе и прогнозировании различных явлений и событий. Обработка данных — важнейший этап в исследовании, ведь точность и качество результатов зависят от качества и структуры данных.
Однако иногда встречаются ситуации, когда данные несбалансированы, то есть классы или категории данных представлены неравномерно. Если простыми словами, один класс данных имеет значительно больше примеров, чем другой класс данных.
Такая ситуация может возникнуть в различных областях, например, в медицине, финансах, маркетинге и т. д. Например, в задаче определения редких заболеваний, количество случаев редкого заболевания будет значительно меньше, чем количество здоровых людей.
Одна из распространенных проблем при работе с несбалансированными данными — недооценка или неправильная интерпретация меньшего класса. В результате такого неравномерного распределения данных алгоритмы могут быть предвзяты и склоняться к классу с большим количеством примеров.
Для решения этой проблемы можно использовать методы обработки несбалансированных данных. Один из наиболее эффективных методов — метод опорных векторов. Метод опорных векторов (SVM) — это алгоритм машинного обучения, который может быть использован для классификации или регрессионного анализа. Он основывается на идеях разделения данных гиперплоскостью с максимальной шириной отступа от двух классов данных.
Применение метода опорных векторов для обработки несбалансированных данных позволяет достичь более справедливого распределения классов и повышения точности предсказаний. Метод SVM позволяет находить оптимальные границы, учитывая неравномерность данных.
Возможные подходы для обработки несбалансированных данных с использованием метода опорных векторов включают, например, изменение весов классов, апсэмплинг (увеличение примеров меньшего класса), даунсэмплинг (уменьшение примеров большего класса), комбинирование различных методов и т. д.
Таким образом, понимание и учет специфики несбалансированных данных является важным шагом при использовании метода опорных векторов для обработки данных. Правильная обработка несбалансированных данных может помочь достичь более точных и справедливых результатов анализа.
Что такое несбалансированные данные
Несбалансированные данные — это тип данных, в котором количество примеров одного класса существенно превышает количество примеров другого класса. Несбалансированность возникает, когда векторы данных, относящиеся к одному классу, преобладают над векторами другого класса.
Как правило, задачи машинного обучения требуют наличия равномерно распределенных данных, чтобы модель обучения могла правильно классифицировать новые входные данные. Однако при наличии несбалансированных данных возникают проблемы с точностью классификации. Модель обучения, обученная на таких данных, часто выдает результаты, смещенные в сторону преобладающего класса, игнорируя менее представленный класс.
Метод опорных векторов (SVM) является одним из популярных методов для классификации. Как обрабатывать несбалансированные данные с помощью метода опорных векторов? Давайте рассмотрим несколько подходов:
- Resampling (выборка данных): это метод, при котором менее представленный класс увеличивается путем добавления новых примеров этого класса или уменьшается путем удаления примеров преобладающего класса.
- Использование взвешенных классов: данный подход предполагает введение весов для каждого класса. Меньше представленному классу присваивается больший вес, чтобы компенсировать его недостаток в данных.
- Применение алгоритмов обучения с учителем: некоторые алгоритмы обучения с учителем имеют встроенные возможности для работы с несбалансированными данными. Эти алгоритмы учитывают структуру классов и используют соответствующие метрики для оценки точности классификации.
В зависимости от задачи и опыта, вы можете выбрать соответствующий подход для обработки несбалансированных данных при использовании метода опорных векторов.
Проблемы, возникающие при работе с несбалансированными данными

При работе с несбалансированными данными с помощью метода опорных векторов (SVM) в Python могут возникать следующие проблемы:
- Неравномерное распределение классов: Несбалансированные данные характеризуются значительным смещением в распределении классов. Одному классу может принадлежать большинство объектов, в то время как другой класс может быть представлен лишь небольшой частью данных. Это может создать проблемы при обучении модели, так как алгоритм может быть предвзят в пользу класса с большим количеством данных, не уделяя достаточное внимание классу с меньшим количеством данных.
- Низкая точность модели: Когда один класс представлен незначительным количеством данных, модель может иметь тенденцию присваивать большинству объектов этого класса предсказанный класс с большим количеством данных. Это может привести к низкой точности предсказания для класса с меньшим количеством данных.
- Неустойчивость модели: Несбалансированные данные могут создавать неустойчивость модели, так как алгоритм может быть склонен создавать сильные предсказания для объектов класса с большим количеством данных, но плохо справляться с объектами класса с меньшим количеством данных.
- Проблемы с оценкой производительности: При работе с несбалансированными данными классификационная модель, даже при имеющей низкую точность предсказания на классе с меньшим количеством данных, может все равно продемонстрировать высокую общую точность, из-за правильной классификации большинства объектов класса с большим количеством данных. Поэтому, оценка производительности модели на несбалансированных данных должна учитывать и другие метрики, такие как полнота (recall), F-мера и матрица ошибок.
Метод опорных векторов для обработки несбалансированных данных
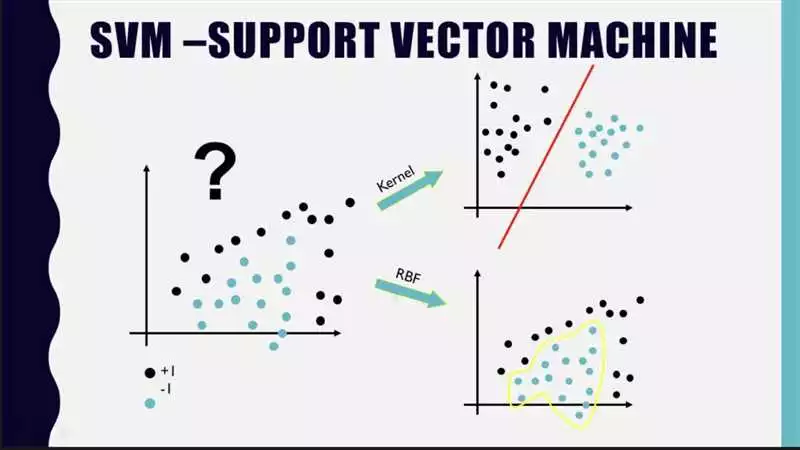
Метод опорных векторов (SVM) – это мощный алгоритм машинного обучения, который может быть использован для обработки несбалансированных данных. Несбалансированные данные означают, что количество экземпляров одного класса значительно превышает количество экземпляров другого класса.
Как обрабатывать несбалансированные данные с помощью метода опорных векторов? Вот несколько шагов:
- Сбор и предобработка данных. Имеется несбалансированные данные, которые нужно обработать. Необходимо провести сбор данных и выполнить предобработку, чтобы избежать возможных проблем в дальнейшем.
- Разделение данных на обучающую и тестовую выборки. Для обучения модели необходимо разделить данные на обучающую и тестовую выборки. Разделение данных поможет оценить качество модели на новых данных.
- Балансировка данных. В случае несбалансированных данных, классы могут быть сильно перекошены. Для балансировки данных можно использовать различные методы, такие как случайное сэмплирование или алгоритмы, основанные на извлечении признаков.
- Настройка гиперпараметров. Гиперпараметры модели SVM могут быть настроены для оптимальной производительности. Это может включать в себя выбор правильного значения параметра регуляризации C, выбор ядра и настройку других параметров модели.
- Обучение модели. После настройки гиперпараметров можно приступать к обучению модели SVM на обучающей выборке.
- Оценка модели. После обучения модели необходимо оценить ее качество на тестовой выборке. Это поможет определить, насколько хорошо модель обрабатывает несбалансированные данные.
Метод опорных векторов – это один из наиболее эффективных методов для обработки несбалансированных данных. Он может быть адаптирован и настроен для различных типов данных и задач. Использование метода опорных векторов для обработки несбалансированных данных требует тщательной предобработки и настройки, но может привести к высокой точности и эффективности классификации.