Метод опорных векторов – это мощный инструмент в машинном обучении, который активно применяется для решения различных задач. Одной из таких задач является обнаружение аномалий. Аномалии могут быть некорректными значениями, ошибками или необычными событиями в данных. Использование метода опорных векторов в обнаружении аномалий позволяет обнаруживать и классифицировать подобные аномалии с высокой точностью.

Индивидуальный график
Индивидуальный график
Индивидуальный график
Векторы в методе опорных векторов представляют собой многомерные точки в пространстве данных. Отбор опорных векторов основывается на разделении данных на классы и создании границы между ними. Python, язык программирования с простым синтаксисом и богатыми возможностями, является идеальным средством для применения метода опорных векторов в задаче обнаружения аномалий.
Для решения задачи обнаружения аномалий с использованием метода опорных векторов в Python можно воспользоваться различными библиотеками, такими как scikit-learn, Pandas и NumPy. Scikit-learn предоставляет широкий набор инструментов для работы с данными и реализации различных методов машинного обучения, включая метод опорных векторов. Pandas позволяет удобно работать с таблицами данных, а NumPy предоставляет возможности для работы с вычислениями и матричными операциями.
Применение метода опорных векторов в задаче обнаружения аномалий с помощью Python позволяет получить высокую точность и эффективность в решении данной задачи. Этот метод нашел широкое применение в различных областях, таких как медицина, финансы, интернет-безопасность и многое другое. Благодаря простоте использования Python и возможностям, предоставляемым библиотеками scikit-learn, Pandas и NumPy, реализация метода опорных векторов становится доступной и удобной для всех, кто занимается обнаружением аномалий в своей деятельности.
Метод опорных векторов (SVM) – это один из наиболее широко используемых алгоритмов в машинном обучении для решения задач классификации и регрессии. Однако, помимо этих задач, SVM также можно применять в обнаружении аномалий.
Задача обнаружения аномалий состоит в поиске необычных или нестандартных данных, которые отличаются от остальных и могут являться потенциально опасными или важными для анализа. Обычные методы машинного обучения могут иметь ограниченные возможности в обнаружении аномалий, тогда как SVM может быть эффективным инструментом в решении этой задачи.
Преимущества использования метода опорных векторов в задаче обнаружения аномалий:
- Высокая точность – SVM стремится найти границу, максимально разделяющую нормальные данные и аномалии, что позволяет достичь высокой точности классификации.
- Устойчивость к выбросам – SVM более устойчив к наличию выбросов и шума в данных, по сравнению с другими алгоритмами.
- Гибкость – SVM позволяет использовать различные ядра (kernel) для адаптации алгоритма к разным типам данных и свойствам задачи.
Python является популярным языком программирования для анализа данных и машинного обучения, поэтому опорные вектора можно реализовать с помощью различных библиотек, таких как scikit-learn.
Ниже приведен пример использования метода опорных векторов в обнаружении аномалий с использованием Python:
- Импортируем необходимые библиотеки:
import numpy as np
from sklearn import svm
- Загружаем данные:
X = np.array([[1, 2], [1, 3], [2, 3], [2, 2], [4, 5], [5, 6]])
Y = np.array([-1, -1, -1, -1, 1, 1])
- Инициализируем и обучаем модель SVM:
model = svm.OneClassSVM(nu=0.1, kernel='rbf', gamma=0.1)
model.fit(X)
- Предсказываем аномалии:
predictions = model.predict(X)
anomalies = X[predictions == -1]
В данном примере мы создаем массив данных, состоящий из двумерных точек, и ассоциируем каждую точку с классом (-1 для нормальных данных, 1 для аномалий). Затем мы инициализируем и обучаем модель SVM с помощью класса OneClassSVM из библиотеки scikit-learn. После обучения модели, мы можем использовать ее для предсказания аномалий, находящихся за пределами границы.
Метод опорных векторов предлагает эффективный и гибкий подход к обнаружению аномалий, а использование Python и библиотеки scikit-learn делает его реализацию доступной и удобной.
Определение и принцип работы метода опорных векторов
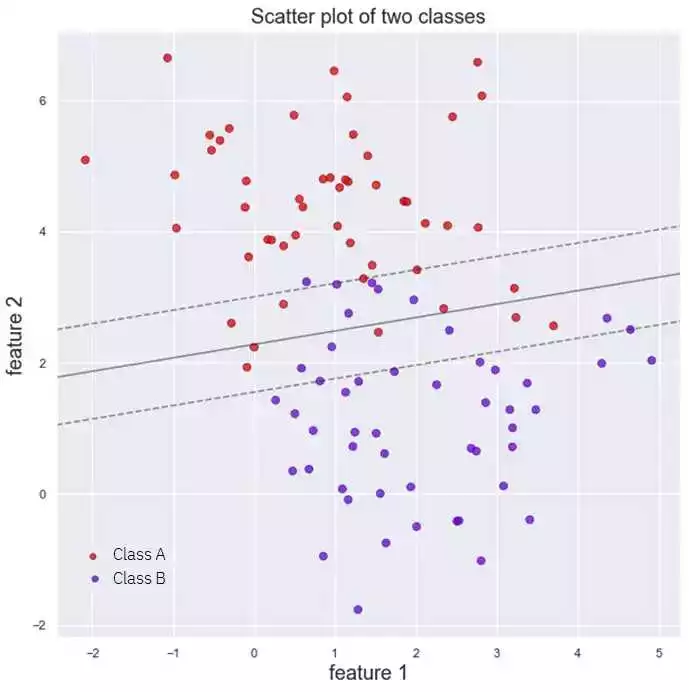
Метод опорных векторов (Support Vector Machines, SVM) – это алгоритм машинного обучения, который широко применяется в задаче обнаружения аномалий и многих других задачах классификации и регрессии. В основе метода лежит идея нахождения оптимальной гиперплоскости, которая максимально разделяет объекты разных классов в пространстве высокой размерности.
Основная идея метода заключается в том, чтобы найти оптимальную гиперплоскость, которая максимально отделяет два класса друг от друга. Для этого используется понятие опорных векторов – это объекты, ближайшие к разделяющей гиперплоскости.
В задаче обнаружения аномалий метод опорных векторов используется для нахождения объектов, которые существенно отличаются от обычных или нормальных данных. Эта задача является одной из важных задач машинного обучения и может быть решена с помощью SVM и алгоритма One-class SVM.
Принцип работы метода опорных векторов заключается в построении гиперплоскости, которая максимизирует расстояние между опорными векторами разных классов. При этом, гиперплоскость должна быть также близкой к объектам каждого класса. Таким образом, SVM находит оптимальную гиперплоскость, которая обеспечивает максимальную разделимость классов и минимальную ошибку классификации.
Python является одним из самых популярных языков программирования в области машинного обучения, и для решения задачи обнаружения аномалий с использованием метода опорных векторов широко используются его библиотеки, такие как scikit-learn, pandas и numpy.
Преимущества и недостатки метода опорных векторов
Метод опорных векторов (SVM) — это один из наиболее популярных методов машинного обучения, широко используемый для решения задач обнаружения аномалий. Векторы, использование которых касается предсказываемых классов, необходимы для обучения модели. Применение метода опорных векторов в обнаружении аномалий с использованием Python может иметь следующие преимущества и недостатки:
Преимущества:
- Высокая точность: SVM обеспечивает высокую точность предсказания, особенно при работе с линейно разделимыми данными.
- Эффективность: SVM показывает хорошую производительность даже на выборках с большим количеством атрибутов.
- Масштабируемость: SVM способен обрабатывать как небольшие, так и очень большие наборы данных.
- Работа с выбросами: SVM устойчив к выбросам и может обнаруживать аномалии, которые находятся далеко от разделяющей гиперплоскости.
- Поддержка различных ядер: SVM позволяет выбирать различные ядра, которые позволяют лучше аппроксимировать данные.
Недостатки:

- Чувствительность к шуму: SVM может быть чувствительным к шуму и выбросам, что может привести к плохой производительности на данных с высокой степенью неоднородности.
- Неэффективность при большом количестве образцов: SVM может быть неэффективным при работе с наборами данных, содержащими большое количество образцов.
- Требовательность к вычислительным ресурсам: SVM требует значительных вычислительных ресурсов, особенно при использовании ядерных функций высокой степени.
- Необходимость правильной настройки параметров: SVM требует грамотной настройки параметров для достижения хороших результатов.
Таким образом, использование метода опорных векторов в обнаружении аномалий с использованием Python имеет свои преимущества и недостатки. При правильной настройке и использовании метод может быть эффективным инструментом для обнаружения аномалий в различных приложениях.
Применение метода опорных векторов в задаче обнаружения аномалий
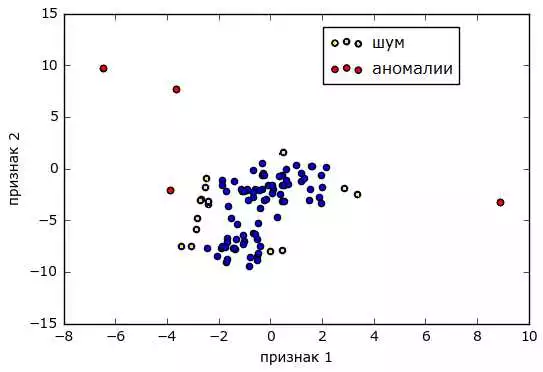
Метод опорных векторов (SVM) является одним из наиболее эффективных алгоритмов машинного обучения, который находит широкое применение в различных задачах, включая обнаружение аномалий.
Обнаружение аномалий — это задача, которая заключается в поиске необычных или аномальных данных в наборе данных. Такие аномалии могут указывать на нарушения или проблемы в системе, и обнаружение их является важной задачей для многих областей, таких как финансы, медицина, кибербезопасность и др.
Использование метода опорных векторов в задаче обнаружения аномалий позволяет эффективно разделять данные на два класса: нормальные точки и аномалии. Алгоритм находит гиперплоскость в пространстве признаков, которая наилучшим образом разделяет эти два класса, минимизируя ошибку классификации.
Для применения метода в Python, существуют различные библиотеки, такие как sklearn, которые предоставляют инструменты для построения моделей SVM и обнаружения аномалий.
Для начала работы с SVM необходимо подготовить данные, определить признаки, на основе которых будет производиться анализ и обнаружение аномалий. Затем необходимо выбрать подходящую функцию ядра, такую как линейное, полиномиальное, радиальное основное (RBF) и др., которая поможет построить оптимальную гиперплоскость разделения.
После обучения модели SVM можно использовать для классификации новых данных и выявления аномалий. Предсказания модели будут указывать, принадлежит ли точка к классу нормальных данных или является аномалией.
Результаты обнаружения аномалий могут быть представлены в различных форматах, например, в виде списка точек аномалий или графического представления с отмеченными аномальными точками.
Применение метода опорных векторов в задаче обнаружения аномалий с использованием Python позволяет эффективно решать данную задачу. Однако важно учитывать, что выбор правильной функции ядра и настройка параметров модели может существенно влиять на качество результатов.
Использование метода опорных векторов в задаче обнаружения аномалий является востребованным и актуальным направлением исследований, в котором активно применяются методы машинного обучения. Этот метод позволяет обнаруживать скрытые аномалии и улучшать безопасность и эффективность различных систем и процессов.
Цель и задачи обнаружения аномалий
Метод опорных векторов (Support Vector Machine, SVM) является одним из наиболее популярных методов машинного обучения, который может быть использован для обнаружения аномалий в данных. Аномалии представляют собой отклонения от нормального поведения или структуры данных и могут быть признаком нарушений, ошибок или важных событий. Целью обнаружения аномалий является выявление и идентификация таких отклонений с помощью алгоритмов машинного обучения.
Задачи обнаружения аномалий включают:
- Построение модели для выявления аномалий: основная задача состоит в разработке и обучении модели, которая будет классифицировать данные на нормальные и аномальные. Для этого используется метод опорных векторов, который строит границы классификации, основываясь на максимальном зазоре между различными классами данных.
- Обработка данных: перед обучением модели необходимо предварительно обработать и подготовить данные. Это может включать в себя удаление выбросов, заполнение пропущенных значений и нормализацию данных.
- Выбор параметров модели: для достижения оптимальных результатов обнаружения аномалий необходимо подобрать наилучшие параметры модели, такие как ядро SVM, параметр регуляризации и т.д. Это может быть выполнено с использованием методов перекрестной проверки и оптимизации гиперпараметров.
- Оценка эффективности модели: после обучения модели необходимо провести оценку ее эффективности. Это может быть выполнено путем сравнения предсказанных классификаций с реальными метками данных или с использованием метрик, таких как точность, полнота и F-мера.
Используя метод опорных векторов и язык программирования Python, можно эффективно реализовать обнаружение аномалий. Python предоставляет богатый набор библиотек и инструментов для работы с данными, разработки моделей машинного обучения и оценки их эффективности.