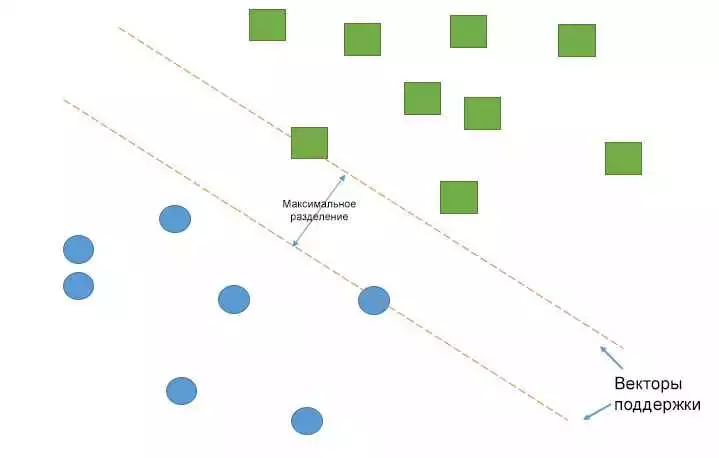
Метод опорных векторов — один из самых популярных алгоритмов машинного обучения, используемых для классификации данных. С его помощью можно разделить наборы данных на два или более класса, находя оптимальную границу между ними. Этот метод основан на принципе максимального зазора, который позволяет найти наиболее разделимые точки в пространстве.

Индивидуальный график
Индивидуальный график
Индивидуальный график
Для использования метода опорных векторов в Python необходимо иметь базовые знания о программировании и машинном обучении. Вначале необходимо импортировать соответствующие библиотеки, такие как scikit-learn, которая предоставляет все необходимые функции и классы для работы с методом опорных векторов. Затем необходимо подготовить данные, обучить модель и произвести классификацию новых наборов данных.
Процесс классификации данных с использованием метода опорных векторов включает в себя несколько шагов. Вначале необходимо проанализировать и предобработать данные, чтобы они были пригодны для работы. Затем следует разделить набор данных на обучающую и тестовую выборки, чтобы проверить качество модели. Далее необходимо выбрать подходящий тип модели опорных векторов и задать параметры алгоритма. Получившуюся модель следует обучить на обучающей выборке и проверить ее точность на тестовой выборке.
В результате классификации данных с использованием метода опорных векторов мы получаем модель, способную классифицировать новые наборы данных. Этот метод широко применяется в различных областях, таких как финансы, медицина, маркетинг и многие другие. Изучение и использование этого метода позволяет получить надежные результаты и повысить качество анализа данных.
Как использовать метод опорных векторов для классификации данных в Python: руководство для начинающих
Метод опорных векторов — один из популярных алгоритмов машинного обучения, используемый для классификации данных. Он основан на поиске оптимального гиперплоскости, разделяющей данные разных классов.
В Python для использования метода опорных векторов существует библиотека scikit-learn. Эта библиотека предоставляет удобный механизм для работы с различными алгоритмами машинного обучения, включая метод опорных векторов.
Для начала необходимо установить библиотеку scikit-learn. Это можно сделать с помощью утилиты pip:
pip install scikit-learnПосле установки библиотеки можно приступить к работе с методом опорных векторов. Вначале необходимо импортировать соответствующий класс:
from sklearn.svm import SVCЗатем можно создать объект классификатора и задать его параметры:
classifier = SVC(kernel='linear', C=1)В данном примере мы используем линейное ядро и параметр C равный 1. Значения этих параметров можно подобрать опытным путем в зависимости от конкретной задачи.
После создания классификатора необходимо обучить его на обучающих данных. Для этого нужно вызвать метод fit и передать ему обучающие данные и соответствующие метки классов:
classifier.fit(X_train, y_train)Где X_train — тренировочные данные, а y_train — метки классов для тренировочных данных. Для получения предсказаний на новых данных можно использовать метод predict:
predictions = classifier.predict(X_test)Где X_test — тестовые данные, для которых требуется получить предсказания. Результатом работы метода будет список предсказанных меток классов.
Также можно оценить качество работы классификатора, используя различные метрики, такие как точность, полноту и F-меру. Библиотека scikit-learn предоставляет удобные функции для вычисления этих метрик:
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
accuracy = accuracy_score(y_test, predictions)
precision = precision_score(y_test, predictions)
recall = recall_score(y_test, predictions)
f1 = f1_score(y_test, predictions)
Оценки можно использовать для сравнения различных вариантов параметров или моделей.
Использование метода опорных векторов для классификации данных в Python может быть очень полезным инструментом в задачах анализа данных и машинного обучения. Он позволяет достичь хорошей точности и обладает большой гибкостью в выборе параметров и ядра.
Важно помнить, что выбор оптимальных параметров и предобработка данных может существенно влиять на результат работы алгоритма. Экспериментируйте с различными подходами и оценивайте результаты, чтобы достичь наилучших результатов.
Понятие метода опорных векторов
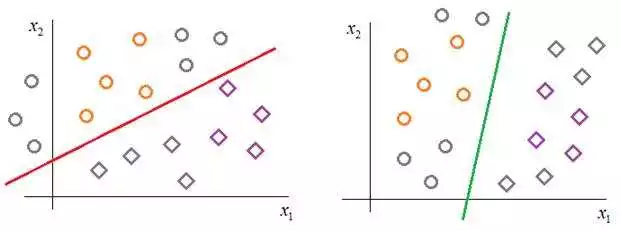
Метод опорных векторов (Support Vector Machines, SVM) — один из наиболее популярных алгоритмов машинного обучения для задач классификации. В основе метода лежит идея поиска гиперплоскости, которая максимально разделяет данные разных классов.
Python предлагает мощные библиотеки для работы с методом опорных векторов, такие как scikit-learn. Они позволяют использовать метод SVM для классификации данных в Python.
Как работает метод опорных векторов?
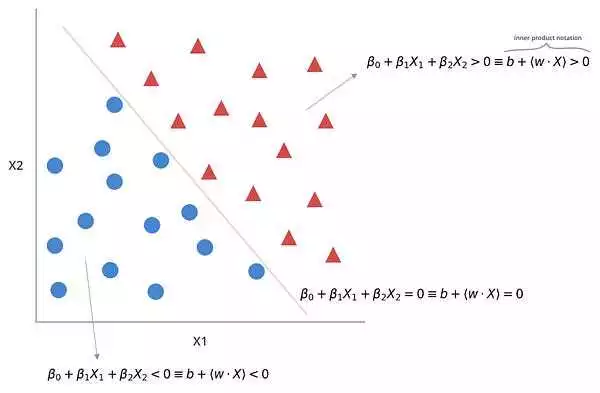
Метод опорных векторов начинает с построения гиперплоскости, которая разделяет данные разных классов. Гиперплоскость строится таким образом, чтобы максимизировать расстояние между точками обучающего набора данных и самой гиперплоскостью. Этот процесс называется оптимизацией разделяющей гиперплоскости.
Однако существуют случаи, когда данные не могут быть линейно разделены в пространстве. В таких ситуациях метод опорных векторов использует технику, называемую ядром, которая позволяет преобразовать данные в пространство большей размерности, где они могут быть линейно разделены.
Используя метод опорных векторов, можно классифицировать данные в Python, определяя класс объектов на основе их признаков и тренировочного набора данных. Для этого необходимо импортировать библиотеку scikit-learn и использовать ее функции и методы для обучения модели и прогнозирования классов новых данных.
Метод опорных векторов является мощным и эффективным инструментом для классификации данных в Python. Он широко используется во многих областях, таких как компьютерное зрение, биомедицина, финансовые рынки и другие.
Принцип работы метода опорных векторов
Метод опорных векторов (Support Vector Machine, SVM) — это алгоритм машинного обучения, который используется для классификации данных. Суть метода заключается в построении гиперплоскости, которая разделяет данные разных классов. Гиперплоскость выбирается таким образом, чтобы она имела наибольшее возможное расстояние (зазор) до ближайших точек каждого класса, называемых опорными векторами.
Метод опорных векторов можно использовать для решения как задачи бинарной классификации, так и многоклассовой классификации. При бинарной классификации гиперплоскость разделяет данные на два класса, в то время как при многоклассовой классификации она разделяет данные на несколько классов.
Процесс работы метода опорных векторов можно описать следующим образом:
- Подготовка данных: данные должны быть представлены в виде числовых векторов или матриц. Если данные не числовые, их следует преобразовать в числовой формат, например, с помощью метода кодирования категорий.
- Выбор ядра: ядро определяет форму гиперплоскости, которая будет разделять данные. Ядро может быть линейным, полиномиальным, радиальным базисным функциям (RBF) и др.
- Обучение модели: в этом шаге модель SVM обучается на обучающей выборке данных. Алгоритм оптимизирует параметры модели для получения наилучшего разделения классов.
- Тестирование модели: после обучения модели следует протестировать ее на отложенной выборке данных, чтобы оценить ее точность и качество классификации.
Метод опорных векторов является одним из наиболее эффективных и широко используемых алгоритмов классификации данных. Он показывает хорошие результаты даже на сложных и нелинейно разделимых данных.
Возможность использования метода опорных векторов для классификации данных делает его важным инструментом в области машинного обучения и анализа данных.
Применение метода опорных векторов в Python
Метод опорных векторов (Support Vector Machines, SVM) — это один из наиболее популярных и мощных алгоритмов машинного обучения, который широко используется для классификации данных. В Python можно использовать метод опорных векторов для решения различных задач классификации.
Как использовать метод опорных векторов в Python для классификации данных:
- Импорт библиотек и загрузка данных: Начните с импорта необходимых библиотек, таких как
pandasиscikit-learn. Затем загрузите данные, с которыми вы будете работать. - Подготовка данных: Перед применением метода опорных векторов необходимо подготовить данные. Это включает в себя разделение данных на обучающую и тестовую выборки, а также преобразование данных в формат, который может быть использован методом опорных векторов.
- Обучение модели: После подготовки данных можно перейти к обучению модели методом опорных векторов. В Python это можно сделать с помощью класса
SVCиз библиотекиscikit-learn. - Оценка модели: После обучения модели необходимо оценить ее производительность. Это может быть сделано путем использования различных метрик, таких как точность (accuracy), полнота (recall) и точность (precision).
- Применение модели: После успешной обучения и оценки модели можно использовать ее для классификации новых данных. Просто передайте новые данные в модель и получите предсказания.
Приведенные выше шаги представляют основную процедуру применения метода опорных векторов для классификации данных в Python. Однако, метод опорных векторов имеет множество параметров, которые можно настроить для достижения лучших результатов. Это может включать выбор типа ядра, настройку параметра регуляризации и выбор функции потерь. Также, возможно использование различных методов оптимизации и алгоритмов решения задачи оптимизации.
В заключение, метод опорных векторов является мощным инструментом для классификации данных в Python. Он может быть применен к самым различным задачам классификации и обеспечить высокую точность предсказаний. Через понимание основных шагов применения метода опорных векторов, вы сможете эффективно использовать этот метод для своих собственных задач классификации данных в Python.
Установка и импорт библиотек
Для использования метода опорных векторов (Support Vector Machine, SVM) для классификации данных в Python, необходимо установить и импортировать соответствующие библиотеки.
Для начала, убедитесь, что на вашем компьютере установлен Python. Вы можете скачать и установить последнюю версию Python с официального веб-сайта https://www.python.org/downloads/.
После установки Python, можно приступить к установке необходимых библиотек для работы с методом опорных векторов. Для этого воспользуйтесь менеджером пакетов в Python — pip. Откройте командную строку или терминал и выполните следующую команду:
pip install scikit-learn
Эта команда установит библиотеку scikit-learn, которая включает в себя реализацию метода опорных векторов.
После успешной установки библиотеки scikit-learn, вы можете импортировать необходимые модули для работы с методом опорных векторов в своем коде Python. Для этого введите следующие строки кода в начале вашего скрипта:
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
В приведенном коде мы импортируем класс SVC (Support Vector Classification) из модуля sklearn.svm для работы с методом опорных векторов для классификации данных. Также мы импортируем функцию accuracy_score из модуля sklearn.metrics, которая позволяет вычислить точность классификации.
Теперь вы готовы использовать метод опорных векторов для классификации данных в Python с помощью библиотеки scikit-learn!
Установка Python и библиотеки scikit-learn

Для использования метода опорных векторов для классификации данных в Python необходимо установить язык программирования Python и библиотеку scikit-learn. В этом разделе мы рассмотрим, как выполнить установку и настройку.
Установка Python
Python можно установить с официального сайта python.org. Следуйте инструкциям на сайте для выбора правильной версии Python для вашей операционной системы и загрузите установщик.
После того, как установщик Python будет загружен, запустите его и следуйте инструкциям на экране. По умолчанию, Python будет установлен в папку C:\Python\, однако вы можете выбрать другую директорию при установке.
Установка библиотеки scikit-learn

После установки Python вам потребуется установить библиотеку scikit-learn. Для установки scikit-learn воспользуйтесь менеджером пакетов pip. В командной строке выполните следующую команду:
«`
pip install scikit-learn
«`
После выполнения этой команды pip загрузит и установит самую свежую версию библиотеки scikit-learn из репозитория Python Package Index (PyPI).
Проверка установки
Чтобы убедиться, что Python и scikit-learn успешно установлены на вашем компьютере, выполните следующие шаги:
- Откройте командную строку или терминал
- Введите команду `python` и нажмите Enter
- Получите приглашение к вводу `>>>`. Это означает, что Python был успешно установлен
- Введите следующие команды:
«`
import sklearn
print(sklearn.__version__)
«`
Если на экране появится номер версии scikit-learn, это означает, что библиотека успешно установлена и готова к использованию.
Теперь, когда Python и библиотека scikit-learn установлены на вашем компьютере, вы готовы использовать метод опорных векторов для классификации данных в Python.
Импорт библиотек и подготовка данных
Перед использованием метода опорных векторов для классификации данных в Python необходимо импортировать несколько библиотек:
- scikit-learn: библиотека машинного обучения, которая предоставляет набор инструментов для работы с данными и моделями машинного обучения.
- pandas: библиотека для анализа и обработки данных.
- numpy: библиотека для работы с многомерными массивами данных.
- matplotlib: библиотека для создания графиков и визуализации данных.
После импорта библиотек следует подготовка данных для использования метода опорных векторов:
- Загрузка данных: данные для классификации должны быть загружены и подготовлены для обучения модели. Для этого можно использовать функции библиотеки pandas, такие как
read_csv()для чтения данных из файла CSV. - Разделение данных: обычно данные разделяются на обучающую и тестовую выборки. Обучающая выборка используется для обучения модели, а тестовая выборка для проверки точности классификации. Библиотека scikit-learn предоставляет функцию
train_test_split()для разделения данных на обучающую и тестовую выборки. - Масштабирование данных: перед использованием метода опорных векторов, данные могут быть масштабированы для обеспечения более эффективной работы модели. Например, можно использовать функцию
StandardScaler()из библиотеки scikit-learn для стандартизации данных.
После выполнения этих шагов, данные готовы для использования метода опорных векторов для классификации.