При анализе данных на Python с использованием библиотеки Pandas можно применять различные методы и техники для получения ценной информации из данных. Библиотека Pandas предоставляет удобные инструменты для работы с табличными данными, позволяя легко загружать, сортировать, фильтровать и анализировать информацию. Благодаря своей гибкости и эффективности, Pandas стал одним из наиболее популярных инструментов для анализа данных на языке Python.

Индивидуальный график
Индивидуальный график
Индивидуальный график
В этой статье мы рассмотрим основные методы и техники анализа данных на Python с использованием библиотеки Pandas. Мы узнаем, как загружать данные из различных источников, как осуществлять фильтрацию и сортировку данных, а также как выполнять различные операции с данными, такие как группировка, агрегация и преобразование. Мы также рассмотрим возможности визуализации данных с использованием Pandas.
Основной целью этой статьи является предоставить читателю практическое руководство по основным принципам и приемам работы с данными на Python с использованием библиотеки Pandas. Мы будем использовать реальные примеры и показывать практические советы, чтобы помочь вам успешно применять Pandas для анализа данных и находить интересующую вас информацию.
Методы анализа данных на Python с использованием библиотеки Pandas
Pandas — это мощная библиотека на языке Python, которая предоставляет удобные инструменты для анализа данных. Она позволяет легко работать с различными типами данных, включая табличные данные и временные ряды. Библиотека Pandas обладает множеством методов и функций для манипуляций с данными, фильтрации, агрегации и визуализации.
Python — один из лидирующих языков программирования для анализа данных, и библиотека Pandas является неотъемлемой частью экосистемы Python для анализа данных. Она предоставляет удобный способ работы с данными, позволяет проводить различные манипуляции с ними и делать выводы на основе полученных результатов.
Методы анализа данных на Python с использованием библиотеки Pandas включают в себя множество функций и инструментов для работы с данными. Некоторые из них:
- Загрузка данных: библиотека Pandas позволяет легко загружать данные из различных источников, таких как CSV-файлы, Excel-файлы, базы данных и т.д.
- Очистка данных: Pandas предоставляет функции для обработки отсутствующих значений, дубликатов и других аномалий в данных.
- Фильтрация данных: с помощью Pandas можно выбирать нужные данные на основе определенных критериев, фильтровать данные по условиям.
- Агрегация данных: библиотека позволяет выполнять различные агрегационные функции, такие как сумма, среднее значение, минимум, максимум и т.д.
- Объединение данных: Pandas предоставляет возможность объединять данные из разных источников, соединять таблицы по ключевым полям.
- Визуализация данных: библиотека также содержит инструменты для визуализации данных, которые позволяют создавать графики, диаграммы и другие визуальные представления данных.
Использование библиотеки Pandas в анализе данных на языке Python позволяет экономить время и усилия при выполнении различных операций с данными. Богатый набор методов и функций позволяет работать со сложными операциями манипуляций и анализа данных, при этом обеспечивая удобство и эффективность.
Методы анализа данных на Python с использованием библиотеки Pandas: руководство по основным приемам и техникам
Библиотека Pandas является одной из наиболее популярных библиотек Python для анализа данных. Она предоставляет удобные средства для работы с таблицами и временными рядами, позволяя быстро и эффективно проводить анализ данных.
С помощью Pandas можно применять различные методы анализа данных. Ниже представлены некоторые из них:
- Чтение данных: Pandas позволяет импортировать данные из различных источников, таких как CSV-файлы, Excel-файлы, базы данных и другие. Для этого используются функции, такие как read_csv() и read_excel().
- Просмотр данных: Pandas предоставляет методы для просмотра и изучения данных, такие как head() и tail(). Они позволяют получить первые или последние несколько строк таблицы.
- Оценка статистических показателей: При помощи Pandas можно вычислять различные статистические показатели, такие как среднее значение, медиану, стандартное отклонение и др. Это можно сделать с помощью метода describe().
- Фильтрация данных: Pandas предоставляет возможность фильтровать данные по заданным условиям, например, с помощью метода query() или операторов сравнения, таких как == или >.
- Группировка данных: Pandas позволяет группировать данные по заданным критериям и применять к ним агрегирующие функции, такие как сумма, среднее, максимум и другие. Для этого используется метод groupby().
- Визуализация данных: Pandas позволяет создавать графики и диаграммы для визуализации данных. Для этого используются методы и функции библиотеки Matplotlib, интегрированные в Pandas.
Развитие методов анализа данных на Python с использованием библиотеки Pandas позволяет исследователям, аналитикам и разработчикам эффективно выполнять различные задачи: от обработки и очистки данных до создания сложных моделей и прогнозирования будущих тенденций.
В целом, использование Pandas в сочетании с Python позволяет проводить широкий спектр операций по анализу данных с высокой производительностью и гибкостью.
Основные методы и подходы
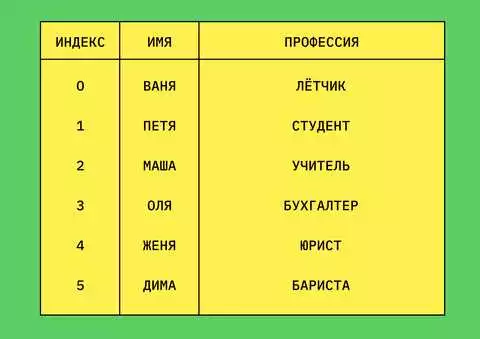
Для анализа данных на языке Python существует множество библиотек, одной из самых популярных из них является библиотека Pandas. Она предоставляет широкий набор методов и инструментов для работы с данными.
Основные методы библиотеки Pandas позволяют выполнить различные операции анализа данных, такие как фильтрация, сортировка, группировка, агрегирование и т.д. Все эти методы позволяют проводить различные операции с данными без необходимости написания большого количества кода.
Один из основных подходов к анализу данных с использованием библиотеки Pandas — это работа с DataFrame. DataFrame — это двумерная таблица, состоящая из строк и столбцов. При работе с DataFrame можно выполнять множество операций, таких как сортировка, фильтрация, группировка и агрегирование данных.
- Методы фильтрации позволяют выбирать только те строки, которые удовлетворяют заданным условиям.
- Методы сортировки позволяют упорядочивать данные по указанным столбцам.
- Методы группировки позволяют объединять данные по указанным столбцам и выполнять агрегацию данных.
- Методы агрегации позволяют считать различные статистические показатели для групп данных, такие как среднее значение, максимальное значение и т.д.
Кроме того, библиотека Pandas предоставляет возможность работать с пропущенными данными и выполнять внешние операции над DataFrame. Поддержка пропущенных данных позволяет более гибко работать с данными и избегать ошибок при анализе.
В целом, использование методов и подходов библиотеки Pandas в языке Python позволяет упростить и ускорить процесс анализа данных и сделать его более удобным и понятным.
Преобразование и очистка данных
В процессе анализа данных на Python с использованием библиотеки Pandas необходимо проводить преобразование и очистку данных, чтобы получить более точные и надежные результаты.
Методы преобразования данных включают изменение типов данных, объединение таблиц, добавление новых колонок и удаление лишних. Методы очистки данных включают удаление дубликатов, заполнение пропущенных значений, удаление выбросов и обработку ошибочных данных.
Одним из основных методов преобразования данных является изменение типов данных. Например, если в столбце содержатся числовые данные, но они записаны в виде строк, то можно преобразовать их в числовой тип данных. Для этого можно использовать функцию astype():
df['column_name'] = df['column_name'].astype(int)
df['column_name'] = df['column_name'].astype(float)
Другим важным методом преобразования данных является объединение таблиц. Если у нас есть несколько таблиц, которые содержат информацию об одном и том же объекте, то мы можем объединить их в одну таблицу. Для этого можно использовать функцию merge():
merged_df = pd.merge(df1, df2, on='column_name')
Также мы можем добавить новую колонку в существующую таблицу. Например, мы можем добавить колонку, которая содержит сумму значений из двух других колонок. Для этого можно использовать оператор сложения:
df['new_column'] = df['column1'] + df['column2']
Очистка данных также играет важную роль в анализе данных. Она позволяет избавиться от лишних, некорректных или пропущенных значений, которые могут исказить результаты анализа. Одним из методов очистки данных является удаление дубликатов. Для этого можно использовать функцию drop_duplicates():
df = df.drop_duplicates()
Еще одним методом очистки данных является заполнение пропущенных значений. Например, если у нас есть столбец, в котором некоторые ячейки содержат пропущенные значения, то мы можем заполнить их определенным значением. Для этого можно использовать функцию fillna():
df['column_name'] = df['column_name'].fillna(value)
Также мы можем удалить выбросы из данных. Выбросы — это значения, которые сильно отличаются от остальных значений и могут исказить результаты анализа. Для этого можно использовать функцию clip(), которая удаляет значения, выходящие за пределы заданного интервала:
df['column_name'] = df['column_name'].clip(lower, upper)
И, наконец, мы можем обработать ошибочные данные. Например, если у нас есть столбец, в котором некоторые значения содержат ошибочные данные, то мы можем заменить их на правильные. Для этого можно использовать функцию replace():
df['column_name'] = df['column_name'].replace(wrong_value, correct_value)
Преобразование и очистка данных являются неотъемлемой частью анализа данных на Python с использованием библиотеки Pandas. Они позволяют улучшить качество данных и получить более точные и достоверные результаты.
Агрегирование и группировка данных
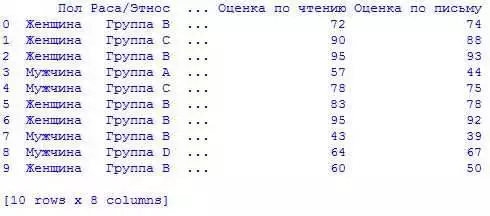
Библиотека pandas является мощным инструментом для анализа данных на языке программирования Python с использованием различных методов и техник. Одной из ключевых возможностей pandas является агрегирование и группировка данных, которые позволяют проводить анализ данных в удобной и эффективной форме.
Методы агрегирования данных в pandas позволяют применять различные функции к группам данных и получать итоговые результаты. Например, можно вычислить сумму, среднее значение или максимальное значение для каждой группы данных.
Для группировки данных в pandas используется функция groupby(). Она позволяет объединить данные по заданным критериям и создать группы. Далее можно применять методы агрегирования к этим группам и получать статистические характеристики для каждой группы.
Примером использования агрегирования и группировки данных может служить анализ данных о продажах товаров. Данные могут быть представлены в виде таблицы с разными столбцами, такими как название товара, количество проданных единиц, цена продажи и дата продажи. С использованием методов pandas можно сгруппировать данные по дате продажи и вычислить общую сумму продаж за каждый день.
Для вывода результатов агрегирования и группировки данных в pandas можно использовать различные методы, например, методы sum(), mean(), max() и другие. Результаты можно представить в виде новой таблицы или отобразить в графическом виде с помощью библиотеки matplotlib.
Использование методов агрегирования и группировки данных в pandas позволяет проводить различные аналитические задачи, такие как вычисление статистических характеристик, исследование зависимостей и паттернов в данных, а также создание отчетов и визуализацию результатов анализа.
В итоге, библиотека pandas с использованием методов агрегирования и группировки данных предоставляет удобный и мощный инструмент для анализа данных на языке программирования Python.
Техники анализа данных
При анализе данных с использованием библиотеки Pandas в Python существуют различные методы и приемы, которые могут помочь в проведении эффективного и качественного анализа данных. В этом разделе рассмотрим некоторые из них.
1. Основные методы анализа данных с Pandas
- Методы для загрузки и сохранения данных: read_csv(), to_csv(), read_excel(), to_excel() и т.д.
- Методы для базового анализа данных: head(), tail(), info(), describe(), shape() и т.д.
- Методы для выборки и фильтрации данных: loc[], iloc[], query(), isin() и т.д.
- Методы для группировки и агрегирования данных: groupby(), sum(), mean(), count(), agg() и т.д.
- Методы для создания новых переменных и преобразования данных: assign(), apply(), map(), replace() и т.д.
2. Техники визуализации данных

- Использование библиотеки Matplotlib для создания графиков и диаграмм.
- Использование библиотеки Seaborn для создания стильных и информативных графиков.
- Использование библиотеки Plotly для создания интерактивных графиков и диаграмм.
3. Техники работы с пропущенными данными
- Определение и обработка пропущенных значений с помощью методов Pandas: isnull(), dropna(), fillna() и т.д.
- Анализ пропущенных данных и выбор оптимального подхода к их обработке.
4. Техники объединения исходных данных
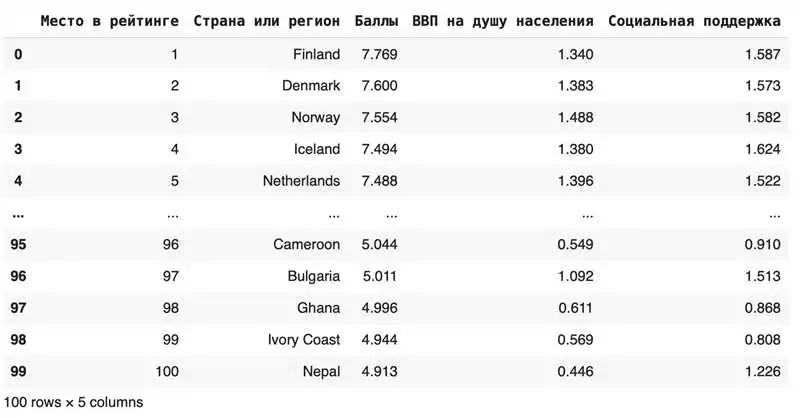
- Объединение таблиц по столбцам или строкам с использованием методов merge(), join() и concat().
- Работа с несколькими источниками данных и их эффективное объединение для получения одной таблицы.
5. Техники работы с большими объемами данных
- Использование эффективных методов Pandas для работы с большими файлами данных.
- Организация работы со сложными вычислениями и обработкой данных в памяти с ограниченными ресурсами.
- Разделение данных на более мелкие подмножества для ускорения анализа и снижения нагрузки на систему.
6. Техники машинного обучения с Pandas

- Приведение данных к формату, подходящему для применения методов машинного обучения.
- Выбор и подготовка признаков для обучения моделей машинного обучения.
- Обучение и оценка моделей машинного обучения на основе данных с помощью библиотеки Scikit-learn.
Это лишь некоторые из методов и техник, которые могут быть применены для анализа данных с использованием библиотеки Pandas в Python. Каждая задача анализа данных требует своего подхода и комбинации различных методов, поэтому рекомендуется изучить дополнительные материалы и примеры для получения полного набора информации.