Осуществление анализа и обработка данных являются важными задачами в программировании. В современном мире огромное количество информации находится в неструктурированных данных, таких как текстовые документы, веб-страницы, логи и т.д. Извлекать информацию из таких данных можно с использованием различных методов и инструментов.

Индивидуальный график
Индивидуальный график
Индивидуальный график
В языке программирования Python есть мощный модуль для работы с данными — Pandas. Эта библиотека предоставляет удобные функции для обработки и анализа данных, включая возможность извлечения информации из неструктурированных данных. С помощью Pandas можно легко считывать, объединять, фильтровать и анализировать данные.
Извлечение информации из неструктурированных данных с использованием Pandas происходит следующим образом: сначала данные считываются в структуры данных, которые предоставляет Pandas, например, в DataFrame. Затем с помощью функций и методов этой библиотеки можно осуществлять изъятие нужной информации.
Особенно полезным инструментом для извлечения информации из неструктурированных данных на Python является модуль BeautifulSoup. С его помощью можно парсить HTML-страницы и извлекать нужные данные из них. Pandas позволяет считывать данные, полученные с помощью BeautifulSoup, и выполнять дополнительную обработку.
Извлечение информации из неструктурированных данных на Python с помощью Pandas
Извлечение информации — одна из основных задач обработки данных в программировании. В реальном мире, информация может быть представлена в различных форматах и структурах. Однако, иногда возникает необходимость извлечь информацию из данных, не имеющих явной структуры или формата. Использование языка программирования Python и библиотеки Pandas позволяет осуществлять изъятие информации из неструктурированных данных с легкостью.
Python — универсальный язык программирования с широким спектром возможностей. Он имеет мощные инструменты для обработки данных и удобный синтаксис, что делает его популярным инструментом для анализа данных и извлечения информации.
Pandas — это мощная библиотека для анализа и обработки данных в языке программирования Python. Она предоставляет высокоуровневые структуры данных и функции для совместной работы с ними. Pandas упрощает извлечение информации из различных форматов данных, включая неструктурированные данные.
Используя библиотеку Pandas, мы можем осуществлять извлечение информации из неструктурированных данных с помощью нескольких методов и функций:
- Установка Pandas и импорт модуля
- Загрузка данных
- Работа с данными
1. Установка Pandas и импорт модуля
Для начала, необходимо установить библиотеку Pandas. Для этого можно использовать команду установки pip:
pip install pandasПосле установки, импортируем модуль Pandas:
import pandas as pd2. Загрузка данных
Следующий шаг — загрузка неструктурированных данных в структуру Pandas. Pandas поддерживает несколько форматов данных, таких как CSV, JSON, Excel, HTML и многих других.
3. Работа с данными
После загрузки данных в структуру Pandas, мы можем использовать различные методы и функции для извлечения нужной информации. Например, методы для фильтрации данных, группировки, сортировки, агрегации и многое другое.
Использование библиотеки Pandas позволяет с легкостью осуществлять извлечение информации из неструктурированных данных в языке программирования Python. Благодаря широкому набору функций и инструментов, Pandas является мощным инструментом для работы с данными и обработки информации.
Роль Pandas в обработке данных на Python
Pandas – это библиотека для обработки данных на языке программирования Python. Одной из важных задач обработки данных является извлечение информации из неструктурированных данных. Благодаря своим функциям и возможностям, Pandas предоставляет удобные инструменты для осуществления извлечения данных из различных источников без использования специальных модулей или сторонних инструментов.
Основной инструмент, предоставляемый библиотекой Pandas для извлечения данных, это объекты Series и DataFrame. Они представляют собой структуры данных, позволяющие удобно и эффективно хранить и манипулировать данными. С помощью Pandas можно осуществлять изъятие информации из таких структур данных, а также анализировать и обрабатывать неструктурированные данные.
Для извлечения информации из неструктурированных данных с помощью Pandas необходимо выполнить следующие шаги:
- Загрузить данные в объект DataFrame.
- Извлечь необходимые данные из структуры данных.
- Обработать и проанализировать извлеченную информацию с использованием функций и методов Pandas.
В Pandas доступны различные методы и функции для извлечения данных из структуры DataFrame. Например, можно использовать методы loc() и iloc() для выбора определенных строк и столбцов.
Также с помощью Pandas можно извлекать данные из неструктурированных источников, таких как файлы CSV, Excel, базы данных и других. Модули Pandas предоставляют инструменты для чтения и записи данных из различных источников, что делает процесс извлечения информации удобным и эффективным.
Таким образом, библиотека Pandas играет значительную роль в обработке данных на языке программирования Python. Она предоставляет удобные инструменты для извлечения и обработки неструктурированных данных, что позволяет проводить анализ и осуществлять извлечение нужной информации с высокой эффективностью.
Извлечение данных
Извлечение данных или изъятие информации из неструктурированных данных является одной из основных задач в области анализа данных и программирования в Python. Для осуществления извлечения данных, которые не имеют стройной структуры, можно использовать библиотеку Pandas.
Python является одним из наиболее популярных языков программирования для извлечения и обработки данных. Благодаря своей простоте и гибкости, Python стал основным языком для анализа данных и извлечения информации.
Python предоставляет разнообразные инструменты и библиотеки для извлечения данных. Одной из таких библиотек является Pandas. Эта библиотека предоставляет инструменты и функции для анализа и обработки данных, включая извлечение информации из неструктурированных данных.
Извлечение данных с использованием Pandas в Python позволяет обрабатывать различные типы данных, включая текстовые, числовые и временные ряды. Библиотека Pandas предлагает интуитивно понятные методы и функции для извлечения и обработки данных, что делает процесс извлечения информации более эффективным и удобным.
Процесс извлечения данных с помощью Pandas включает в себя несколько шагов. Сначала необходимо загрузить неструктурированные данные в Python. Затем можно использовать различные методы и функции библиотеки Pandas для обработки и извлечения нужной информации.
Извлечение данных может включать в себя различные операции, такие как фильтрация, сортировка, группировка, агрегирование и другие. Pandas предоставляет мощные инструменты для выполнения этих операций и обработки данных в удобной форме.
Благодаря своему богатому функционалу и простоте использования, Pandas стал незаменимым инструментом для извлечения данных из неструктурированных и структурированных источников. Она предоставляет широкий спектр возможностей для обработки и анализа данных, что делает процесс извлечения информации более эффективным и гибким.
Вывод: Извлечение данных или изъятие информации из неструктурированных данных является важной задачей в анализе данных. Программирование на Python с использованием библиотеки Pandas облегчает процесс извлечения данных и обработки информации. Благодаря своей гибкости и мощным инструментам, Pandas позволяет удобно и эффективно обрабатывать данные и извлекать нужную информацию.
Чтение неструктурированных данных в Pandas

Извлечение и осуществление анализа информации на языке программирования Python часто требует обработки неструктурированных данных. Для изъятия и обработки данных из различных источников на языке Python можно использовать мощную библиотеку Pandas.
Pandas предлагает обширный набор инструментов для извлечения, обработки и анализа данных, в том числе и для работы с неструктурированными данными. Использование модуля Pandas позволяет преобразовать данные из различных форматов и источников в удобную для анализа структуру данных.
Для проведения анализа и извлечения информации из неструктурированных данных на языке Python с помощью Pandas, необходимо использовать модуль pandas и его функционал. В основе библиотеки Pandas лежит такая структура данных, как Dataframe, которая позволяет эффективно хранить и обрабатывать табличные данные.
Для чтения неструктурированных данных в Pandas можно использовать различные методы, в зависимости от вида данных. Например, для чтения данных из файлов csv можно воспользоваться методом read_csv(). Для чтения данных из баз данных можно использовать метод read_sql(), а для чтения данных из Excel-файлов — метод read_excel().
Преимущество использования Pandas для извлечения информации из неструктурированных данных заключается в том, что эта библиотека предоставляет мощные инструменты для обработки и анализа данных. С помощью Pandas можно быстро и удобно провести предварительную обработку данных, удалить дубликаты, заполнить пропущенные значения, произвести агрегацию и многое другое.
Таким образом, использование библиотеки Pandas для извлечения информации из неструктурированных данных на языке Python позволяет значительно упростить и ускорить процесс анализа данных.
Извлечение информации из текстовых файлов
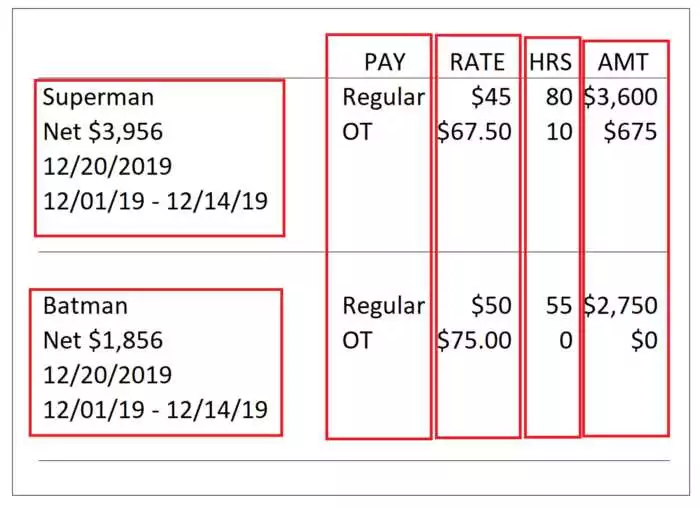
Извлечение информации из неструктурированных данных является важной задачей в области анализа данных. В Python существует множество инструментов для работы с такими данными, и одним из самых популярных является библиотека Pandas.
Pandas предоставляет удобные средства для обработки и анализа данных в структурированном формате. Однако, для извлечения информации из неструктурированных текстовых файлов, таких как логи, отчеты и прочие документы, необходимы дополнительные инструменты.
В Python можно использовать модуль csv для работы с текстовыми файлами. Однако, данный модуль ориентирован на работу с таблицами и не предоставляет удобных средств для извлечения информации без явного указания структуры данных.
Для осуществления извлечения информации из неструктурированных данных с помощью Pandas, возможно использование модуля BeautifulSoup. Этот модуль позволяет проводить обработку HTML и XML документов, извлекать нужные данные с использованием синтаксиса, похожего на язык запросов SQL.
Программирование извлечения информации из текстовых файлов может быть упрощено с помощью использования Pandas. Библиотека позволяет прочитать данные из файлов в табличном формате и выполнить необходимые манипуляции.
Извлечение информации из текстовых файлов с использованием Pandas может быть полезным для анализа данных, создания отчетов и поиска интересующей информации среди больших объемов неструктурированных данных.
Работа с различными форматами данных
При осуществлении извлечения информации из неструктурированных данных на языке программирования Python часто возникает необходимость работать с различными форматами данных. Для обработки и анализа данных с использованием библиотеки Pandas можно извлекать информацию из различных источников без особых усилий.
Модуль Pandas предоставляет удобный инструментарий для работы с различными структурами данных, такими как таблицы и временные ряды. С его помощью можно легко извлекать, обрабатывать и анализировать данные.
На языке Python с использованием Pandas можно осуществлять извлечение информации из неструктурированных данных различных форматов, таких как CSV, Excel, JSON и других. Модуль Pandas предоставляет удобные функции и методы для работы с этими форматами данных.
Для извлечения информации из файлов в формате CSV можно использовать метод read_csv(). Этот метод позволяет считывать данные из CSV-файлов и преобразовывать их в таблицу Pandas, что упрощает дальнейшую обработку и анализ данных.
Аналогично для работы с файлами в формате Excel в модуле Pandas есть метод read_excel(). Он позволяет считывать данные из Excel-файлов и преобразовывать их в таблицу Pandas.
Для работы с форматом данных JSON можно использовать функцию pd.read_json(). Она позволяет считывать данные из JSON-файлов и преобразовывать их в таблицу Pandas.
Также модуль Pandas предоставляет возможности для работы с другими форматами данных, такими как XML, SQL, HDF5 и другие.
В итоге, благодаря разнообразным функциям и методам библиотеки Pandas, извлечение информации из неструктурированных данных различных форматов на языке Python становится гораздо проще и удобнее.
Обработка данных без структуры
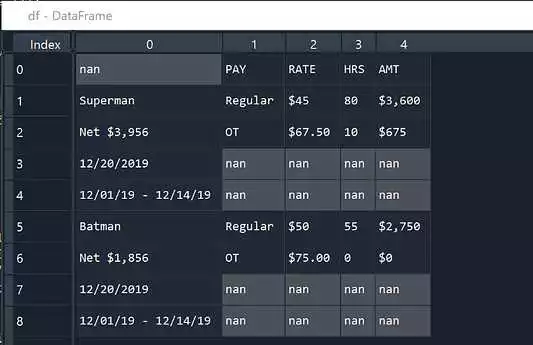
Извлечение информации из неструктурированных данных является одной из важных задач в анализе данных. Для осуществления данной задачи на языке программирования Python существует модуль pandas, который предоставляет удобные инструменты для извлечения и обработки данных.
Неструктурированные данные представляют собой информацию, которая не имеет явной структуры и организации. Примерами неструктурированных данных могут быть тексты, логи, веб-страницы и т.д. Одной из задач обработки таких данных является извлечение полезной информации для последующего анализа.
Библиотека pandas предоставляет возможность извлекать и обрабатывать данные из неструктурированных и полуструктурированных источников с помощью своего функционала. Для извлечения данных из таких источников обычно используются методы из модуля pandas, такие как read_csv, read_excel, read_html и другие.
Осуществление извлечения данных без структуры с помощью pandas происходит следующим образом:
- Подключение необходимых модулей и библиотек, включая pandas.
- Загрузка неструктурированных данных в структуры данных pandas.
- Обработка данных с использованием методов pandas.
- Извлечение полезной информации из обработанных данных.
С помощью библиотеки pandas можно легко извлекать данные из неструктурированных источников различных форматов, таких как csv, excel, html и многих других. Затем можно производить необходимую обработку полученных данных, например, фильтрацию, группировку, сортировку и т.д. После обработки можно извлечь нужную информацию для анализа или принятия решений.
Использование библиотеки pandas для извлечения информации из неструктурированных данных позволяет существенно упростить процесс обработки и анализа данных. Благодаря богатому функционалу и простоте использования, pandas стал одним из наиболее популярных инструментов для работы с данными в языке программирования Python.
Как автоматизировать скучную работу в Pandas? | Аналитик данных | karpov.courses

Урок 4. Обработка и анализ данных на Python. Объединение датафреймов в Pandas

Uncover Hidden Insights with Python | Word Frequency Analysis ???????? #Python #viral #CodingProjects
