В современном мире объемы данных, требующих обработки, растут с каждым днем. Чтобы справиться с этой задачей, программисты исследуют различные способы ускорения обработки данных. Один из самых эффективных способов — использование многопоточности.

Индивидуальный график
Индивидуальный график
Индивидуальный график
Python — один из самых популярных языков программирования, и его богатая библиотека стандартных модулей предоставляет мощные инструменты для работы с многопоточностью. Использование потоков позволяет разделить задачу на несколько независимых частей и выполнять их параллельно. Это особенно полезно при работе с большими объемами данных, где время обработки может быть значительным.
Преимущества многопоточности в Python очевидны: ускорение обработки данных, снижение времени выполнения задачи и повышение общей производительности программы. Однако, при использовании многопоточности необходимо быть осторожным, так как неправильное ее применение может привести к ошибкам и нестабильной работе программы. Поэтому рекомендуется тщательно изучить документацию и использовать синхронизацию и блокировки для предотвращения возможных проблем.
В заключение, использование многопоточности в Python позволяет значительно ускорить обработку данных, что особенно полезно в ситуациях с большими объемами данных. Однако, необходимо быть внимательным и тщательно планировать использование потоков, чтобы избежать возможных ошибок. В целом, многопоточность в Python является мощным инструментом, который помогает программистам эффективно управлять и обрабатывать данные.
Ускорение обработки данных с помощью многопоточности в библиотеке Python
В современном мире обработка больших объемов данных стала неотъемлемой частью многих задач. Быстрая обработка данных является ключевым фактором для эффективной работы приложений и систем. Для достижения оптимальной производительности часто требуется использование многопоточности, особенно в языках программирования, таких как Python.
Python — один из самых популярных языков программирования для работы с данными. Библиотека Python предоставляет различные возможности для ускорения обработки данных с использованием многопоточности. Многопоточность позволяет выполнять несколько задач одновременно, распределяя вычислительные ресурсы на несколько потоков.
Для ускорения обработки данных в Python можно использовать следующие подходы:
- Параллельная обработка данных — разделение задачи на независимые подзадачи, которые могут быть выполнены параллельно. Каждый поток работает с определенной частью данных и выполняет необходимые вычисления. После завершения обработки каждого потока, результаты собираются и объединяются в конечный результат.
- Асинхронная обработка данных — асинхронность позволяет выполнять задачи в фоновом режиме, не блокируя основной поток выполнения. Это особенно полезно при работе с операциями ввода-вывода, такими как чтение и запись файлов или сетевые запросы.
Python предоставляет несколько библиотек для работы с многопоточностью, включая:
- threading — это встроенная библиотека Python для создания и управления потоками. Она предоставляет простой и удобный API для создания и выполнения параллельных задач.
- concurrent.futures — это модуль Python, который предоставляет высокоуровневый интерфейс для выполнения асинхронных задач. Он также поддерживает параллельную обработку данных с использованием пула потоков или пула процессов.
Для эффективного использования многопоточности в Python для ускорения обработки данных рекомендуется учитывать следующие советы:
- Правильно выбирать количество потоков в зависимости от доступных вычислительных ресурсов и характера задачи.
- Избегать гонок данных путем использования механизмов синхронизации, таких как блокировки или очереди.
- Использовать пулы потоков или пулы процессов для повышения производительности и предотвращения перегрузки системы.
- Оптимизировать доступ к данным и минимизировать критические секции, чтобы избежать блокировки и улучшить производительность.
Использование многопоточности в библиотеке Python для ускорения обработки данных может значительно повысить производительность и эффективность вашего кода. Однако, при правильном проектировании и реализации многопоточного приложения необходимо учитывать потенциальные проблемы, связанные с синхронизацией данных и обработкой ошибок.
В итоге, использование многопоточности в библиотеке Python для ускорения обработки данных может быть весьма полезным инструментом при работе с большими объемами данных и выполнении вычислительно интенсивных задач.
Применение многопоточности в библиотеке Python

Многопоточность — это способность программы выполнять несколько потоков одновременно и параллельно. В библиотеке Python существует множество возможностей для использования многопоточности, что позволяет ускорить обработку данных и повысить производительность программы. Рассмотрим некоторые из них.
- Модуль threading — этот модуль позволяет создавать и управлять потоками выполнения в Python. С его помощью можно создавать новые потоки, запускать их и останавливать. Простое использование этого модуля позволяет повысить скорость обработки данных путем распараллеливания задач.
- Модуль concurrent.futures — данный модуль предоставляет высокоуровневый интерфейс для параллельного выполнения задач. Он предоставляет класс ThreadPoolExecutor для создания пула потоков и использования их для выполнения функций или методов классов. Такой подход очень удобен, так как не требует работы с нативными потоками Python.
- Модуль multiprocessing — данный модуль предоставляет возможность запускать несколько процессов, каждый из которых работает в отдельном потоке. Это позволяет эффективно использовать несколько ядер процессора и ускорить обработку данных.
Использование многопоточности для ускорения обработки данных в библиотеке Python является важным приемом разработки программ. Однако следует учитывать, что многопоточность может приводить к проблемам синхронизации доступа к общим данным и возникновению гонок данных. Поэтому при использовании многопоточности необходимо следовать рекомендациям по безопасному управлению потоками и синхронизации доступа к общим ресурсам.
| Преимущества | Недостатки |
|---|---|
|
|
В заключение, использование многопоточности в библиотеке Python является мощным инструментом для ускорения обработки данных. С помощью различных модулей и классов, таких как threading, concurrent.futures и multiprocessing, можно достичь параллельного выполнения задач и повысить производительность программы.
Увеличение скорости обработки данных
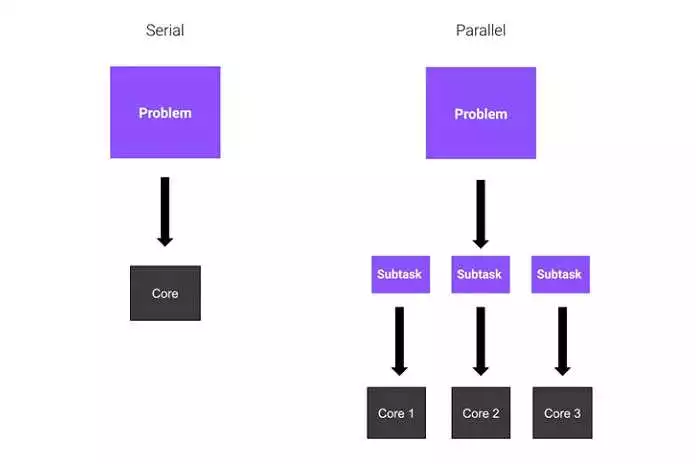
Обработка данных является важной задачей для многих проектов. В Python существует множество инструментов и библиотек, которые позволяют ускорить процесс обработки данных и повысить эффективность работы.
Одним из самых эффективных способов ускорения обработки данных в Python является использование многопоточности. Многопоточность позволяет выполнять несколько задач параллельно, что увеличивает производительность программы.
Python предоставляет все необходимые средства для работы с многопоточностью. Например, модуль threading позволяет создавать и управлять потоками исполнения, а модуль concurrent.futures предоставляет удобный интерфейс для распределения задач между потоками.
Использование многопоточности для обработки данных может быть особенно полезно в случаях, когда обработка данных занимает много времени или требует большого количества вычислительных ресурсов. В таких случаях, разделение задач на несколько потоков может значительно увеличить скорость обработки данных.
Однако, при использовании многопоточности необходимо учитывать некоторые особенности. Например, не все задачи могут быть распараллелены эффективно, так как некоторые операции могут быть зависимыми или требовать блокировки ресурсов. Кроме того, использование большого количества потоков может привести к проблемам синхронизации и возникновению гонок данных.
Для достижения максимальной эффективности при использовании многопоточности для обработки данных в Python, рекомендуется следующие практики:
- Анализировать задачи и идентифицировать те, которые могут быть распараллелены.
- Использовать правильные средства для работы с многопоточностью, такие как модуль threading или concurrent.futures.
- Управлять количеством потоков, чтобы избежать проблем синхронизации и гонок данных.
- Избегать блокировок ресурсов и использовать атомарные операции, когда это возможно.
В итоге, использование многопоточности для обработки данных в Python может существенно увеличить скорость работы программы и повысить ее эффективность. Однако, необходимо учитывать особенности каждой задачи и следовать определенным практикам, чтобы добиться наилучших результатов.
Использование потоков в Python

Ускорение обработки данных с помощью многопоточности становится все более актуальным в современном мире. Python предоставляет удобные средства для использования многопоточности и повышения эффективности обработки данных.
Многопоточность в Python позволяет выполнять несколько операций одновременно, разделяя задачи между потоками. Это идеальный подход для обработки данных, когда есть несколько независимых задач, которые можно выполнять параллельно.
Для использования многопоточности в Python можно воспользоваться модулем threading. С помощью этого модуля можно создать потоки, запускать их, передавать данные между потоками и контролировать их выполнение.
Один из способов использования потоков в Python — разделение задач на независимые части и выполнение их параллельно. Например, если требуется обработать большой массив данных, можно разделить этот массив на несколько частей и обрабатывать каждую часть в отдельном потоке.
Другой способ использования потоков в Python — создание потоков для разных задач и их выполнение одновременно. Например, если требуется обработать разные файлы или запросы, можно создать отдельные потоки для обработки каждого из них.
Использование потоков в Python позволяет сократить время обработки данных и повысить эффективность работы программы. Однако, при использовании многопоточности следует быть осторожным и учитывать возможные проблемы, связанные с синхронизацией доступа к данным и конфликтами между потоками.
В заключение, использование многопоточности в Python — это мощный инструмент для ускорения обработки данных. Правильное использование потоков позволяет распараллеливать задачи, повышая общую производительность программы. Поэтому, при работе с большими объемами данных или задачами, требующими параллельной обработки, стоит обратить внимание на возможности многопоточности в Python.
Применение параллельного программирования

Для ускорения обработки данных в Python, часто используется многопоточность. Это позволяет распараллелить выполнение различных задач и повысить общую производительность программы.
Применение параллельного программирования в обработке данных может быть особенно полезно в следующих случаях:
- Обработка больших объемов данных, которые занимают много времени.
- Вычислительно сложные операции или алгоритмы, которые могут быть разбиты на независимые куски.
- Работа с внешними ресурсами, такими как базы данных или сетевые запросы, которые могут занимать длительное время ожидания.
Python предоставляет множество инструментов для работы с многопоточностью. Например, модуль threading позволяет создавать и управлять потоками выполнения. Этот модуль предоставляет простой и удобный интерфейс для создания и запуска потоков, а также управления ими.
Возможности многопоточности в Python могут быть использованы для распараллеливания выполнения различных задач обработки данных. Например, при обработке больших файлов можно разделить их на несколько частей и обрабатывать каждую часть в отдельном потоке. Это может значительно сократить общее время выполнения программы.
Однако при использовании многопоточности в Python следует учитывать некоторые особенности. Например, возникают проблемы синхронизации доступа к общим ресурсам, таким как переменные или файлы. Для решения этих проблем можно использовать механизмы блокировок или семафоров, которые предоставляются модулем threading.
Таким образом, применение параллельного программирования в Python позволяет значительно ускорить обработку данных и повысить общую производительность программы. Однако необходимо учитывать особенности работы с многопоточностью и применять соответствующие механизмы синхронизации для обеспечения корректной работы программы.