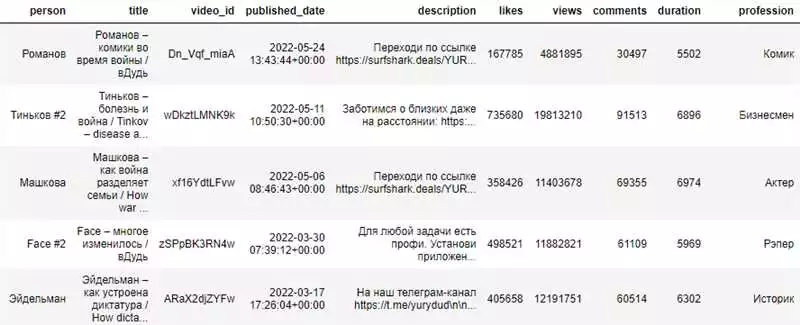
Анализ текстовых данных — это практические методы обработки и извлечения информации из текстов. В современном мире, где огромное количество данных создается каждую секунду, умение анализировать и извлекать ценную информацию из текста является востребованным навыком. Особенно актуальным становится анализ текстовых данных на языке Python.

Индивидуальный график
Индивидуальный график
Индивидуальный график
Python — один из самых популярных языков программирования для работы с данными. Он обладает множеством библиотек и модулей, которые делают работу с текстовыми данными простой и удобной. Одним из основных модулей для анализа текстовых данных на Python является NLTK (Natural Language Toolkit).
NLTK — это библиотека для обработки естественного языка, которая предоставляет разнообразные инструменты и ресурсы для анализа текстовых данных. Она содержит реализацию основных методов обработки текста, таких как токенизация, лемматизация, стемминг, извлечение ключевых слов и многое другое. С помощью NLTK можно проводить различные анализы, такие как анализ тональности текста, классификация текстов по категориям и многое другое.
В данной статье мы рассмотрим основные методы анализа текстовых данных на языке Python с использованием модуля NLTK. Будем изучать различные техники обработки текста, а также применять их на практике для решения реальных задач. После прочтения статьи вы сможете использовать эти методы для анализа и извлечения информации из текстовых данных на языке Python.
Анализ текстовых данных на Python с использованием модуля NLTK
Анализ текстовых данных является важным этапом в области обработки естественного языка. На языке программирования Python вы можете использовать модуль Natural Language Toolkit (NLTK) для проведения анализа текстовых данных.
NLTK предоставляет множество методов и функций для работы с текстовыми данными, включая токенизацию, стемминг, лемматизацию, определение частей речи, извлечение ключевых слов и многое другое.
Ниже приведены некоторые основные методы и примеры использования модуля NLTK.
Токенизация

Токенизация является процессом разделения текста на отдельные слова или токены. Модуль NLTK предоставляет токенизаторы для различных языков.
Пример кода для токенизации текста на английском языке:
import nltk
from nltk.tokenize import word_tokenize
text = "Natural Language Processing (NLP) is a branch of artificial intelligence that helps computers understand, interpret and manipulate human language."
tokens = word_tokenize(text)
Стемминг

Стемминг — это процесс нахождения основы слова путем удаления окончания. NLTK предоставляет стеммеры для различных языков, включая английский и русский.
Пример кода для стемминга на английском языке:
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
stemmed_words = [stemmer.stem(word) for word in tokens]
Лемматизация

Лемматизация — это процесс приведения слова к его нормальной форме или лемме. NLTK также предоставляет лемматизаторы для различных языков.
Пример кода для лемматизации на английском языке:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatized_words = [lemmatizer.lemmatize(word) for word in tokens]
Определение частей речи
Определение частей речи (POS-tagging) — это процесс определения грамматической категории каждого слова в предложении. NLTK предоставляет метод для определения частей речи.
Пример кода для определения частей речи на английском языке:
from nltk import pos_tag
pos_tags = pos_tag(tokens)
Извлечение ключевых слов
Извлечение ключевых слов позволяет найти наиболее значимые слова в тексте. NLTK предоставляет методы для извлечения ключевых слов.
Пример кода для извлечения ключевых слов на английском языке:
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
stop_words = set(stopwords.words("english"))
filtered_text = [word for word in tokens if word.casefold() not in stop_words]
Это лишь некоторые практические примеры анализа текстовых данных с использованием модуля NLTK на языке программирования Python. NLTK также предоставляет функции для проведения морфологического анализа, синтаксического анализа и многое другое.
Более подробную информацию и примеры кода вы можете найти в документации модуля NLTK: https://www.nltk.org.
Модули и пакеты в Python для работы с данными
Python — это один из самых популярных языков программирования, который активно используется для анализа данных. Одним из основных модулей, используемых для работы с текстовыми данными, является модуль NLTK (Natural Language Toolkit).
Модуль NLTK предоставляет множество методов и функций для работы с текстовыми данными на языке Python. Он включает в себя различные инструменты для предобработки текста, токенизации, лемматизации, стемминга и многое другое. Ниже приведены некоторые примеры основных методов, доступных в модуле NLTK:
- Токенизация — процесс разделения текста на отдельные слова или токены. В модуле NLTK есть несколько методов для токенизации текста, таких как
word_tokenize()иsent_tokenize(). - Лемматизация — процесс приведения слова к его нормальной форме (лемме). Модуль NLTK предоставляет метод
WordNetLemmatizer()для лемматизации слов. - Стемминг — процесс обрезания слова до его основы. В модуле NLTK есть несколько стеммеров, таких как
PorterStemmer()иSnowballStemmer(). - Частотный анализ — процесс определения частоты использования слов или фраз в тексте. Модуль NLTK предоставляет метод
FreqDist()для подсчета частоты использования слов.
Практические примеры использования модуля NLTK для анализа текстовых данных на Python могут быть разнообразны. Например, можно использовать модуль NLTK для анализа тональности текста, построения графиков частотности слов, определения ключевых слов и многое другое.
В Python также существует множество других модулей и пакетов для работы с данными, помимо модуля NLTK. Например, модуль pandas предоставляет мощные средства для работы с табличными данными, модуль numpy — для работы с массивами и матрицами, а модуль matplotlib — для визуализации данных.
Все эти модули и пакеты вместе предоставляют широкие возможности для анализа и работы с данными на языке Python.
Модуль NLTK для анализа текстовых данных

Модуль NLTK (Natural Language Toolkit) является одним из наиболее популярных инструментов для работы с текстовыми данными на Python. Он предоставляет широкий набор методов и функций для анализа и обработки текста, а также реализует различные практические алгоритмы для работы с данными.
С помощью модуля NLTK можно проводить различные операции с текстовыми данными, такие как токенизация (разделение текста на отдельные слова или предложения), лемматизация (приведение слова к его нормальной форме), определение частей речи, извлечение ключевых слов и многое другое.
Приведем примеры некоторых практических методов, которые можно использовать с помощью модуля NLTK:
- Токенизация текста: разделение текста на отдельные слова или предложения.
- Стемминг: приведение слова к его основной форме путем отсечения окончаний.
- Лемматизация: приведение слова к его нормальной форме с помощью словарных данных.
- Определение частей речи: определение, к какой части речи относится каждое слово.
- Извлечение ключевых слов: нахождение наиболее важных слов или терминов в тексте.
- Анализ частотности: определение частоты встречаемости слов или терминов в тексте.
Все эти методы могут применяться для анализа текстовых данных в различных областях, таких как компьютерная лингвистика, обработка естественного языка, машинное обучение и другие.
Пример использования модуля NLTK для анализа текстовых данных:
- Установите модуль NLTK с помощью команды
pip install nltk. - Импортируйте модуль в свой скрипт или интерактивную сессию Python.
- Загрузите необходимые данные и модели с помощью методов
nltk.download(). - Примените методы модуля NLTK для анализа и обработки текстовых данных.
- Изучите результаты анализа и осуществите дальнейшие операции с данными.
Таким образом, модуль NLTK является мощным инструментом для анализа и обработки текстовых данных на языке Python. Он предоставляет множество методов и функций, которые позволяют проводить различные операции с текстом. Благодаря этому, модуль NLTK может быть полезным инструментом в различных прикладных задачах и исследованиях, связанных с анализом и обработкой текстовых данных.
Основные возможности модуля NLTK

Модуль NLTK (Natural Language Toolkit) — это библиотека для обработки естественного языка, разработанная на языке Python. NLTK предоставляет различные инструменты и ресурсы для анализа текстовых данных.
Основные возможности модуля NLTK включают:
- Токенизация: NLTK предоставляет инструменты для разделения текста на отдельные токены (слова, символы, предложения и т.д.). Это удобно для последующей обработки и анализа текстовых данных.
- Морфологический анализ: NLTK позволяет проводить морфологический анализ текста, включая лемматизацию (приведение слова к его базовой форме) и определение частей речи.
- Синтаксический анализ: NLTK может анализировать и определить синтаксическую структуру предложений, включая определение зависимостей между словами.
- Выделение ключевых слов: NLTK предоставляет инструменты для автоматического выделения ключевых слов в тексте. Это может быть полезно для краткого описания содержания текста или для анализа ключевых тем.
- Анализ сентимента: NLTK может проводить анализ тональности текста, помогая определить, является ли текст положительным, отрицательным или нейтральным.
- Классификация текстов: NLTK позволяет создавать модели классификации для автоматического определения категории или настроения текста на основе его содержания.
Примеры практического использования модуля NLTK для анализа текстовых данных на языке Python:
- Анализ тональности отзывов к фильмам для определения популярности фильма.
- Классификация новостных статей по тематике (политика, спорт, развлечения и т.д.).
- Выделение ключевых слов и тем в больших текстовых корпусах для обобщения содержания или проведения исследований.
- Анализ морфологии и синтаксиса в лингвистических исследованиях.
| Модуль NLTK | Официальный сайт |
|---|---|
| NLTK | https://www.nltk.org/ |
Вывод: модуль NLTK является мощным инструментом для анализа текстовых данных на языке Python. Он предоставляет широкий набор инструментов и ресурсов, которые могут быть использованы для различных практических задач анализа текстов. С его помощью можно проводить токенизацию, морфологический и синтаксический анализ, анализ сентимента, классификацию текстов и многое другое.
Исследование текстовых данных на языке Python с использованием NLTK
Анализ текстовых данных является важной задачей в сфере компьютерной лингвистики и обработки естественного языка. Возможность эффективно обрабатывать и анализировать тексты позволяет получать ценные исследовательские и прикладные результаты.
Основным инструментом для работы с текстовыми данными на языке Python является библиотека Natural Language Toolkit (NLTK). NLTK предоставляет практические инструменты и ресурсы для работы с текстовыми данными, такие как токенизация, стемминг, лемматизация, разметка частей речи, извлечение синтаксических связей и многое другое.
Посмотрим на несколько примеров использования NLTK для анализа текстовых данных на языке Python.
Токенизация
Токенизация — это процесс разделения текста на отдельные слова или токены. В NLTK это можно сделать с помощью класса Tokenizer:
from nltk.tokenize import word_tokenize
text = "Исследование текстовых данных на языке Python с использованием NLTK"
tokens = word_tokenize(text)
print(tokens)
Результат:
['Исследование', 'текстовых', 'данных', 'на', 'языке', 'Python', 'с', 'использованием', 'NLTK']
Стемминг
Стемминг — это процесс нахождения основы слова путем удаления окончаний. В NLTK для стемминга можно использовать класс PorterStemmer:
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
words = ["исследование", "текстовых", "данных", "языке", "Python"]
stemmed_words = [stemmer.stem(word) for word in words]
print(stemmed_words)
Результат:
['исследован', 'текстовых', 'данных', 'язык', 'Python']
Лемматизация
Лемматизация — это процесс приведения слова к его нормальной форме или лемме. В NLTK для лемматизации можно использовать класс WordNetLemmatizer:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
words = ["исследование", "текстовых", "данных", "языке", "Python"]
lemmatized_words = [lemmatizer.lemmatize(word) for word in words]
print(lemmatized_words)
Результат:
['исследование', 'текстовый', 'данный', 'язык', 'Python']
Разметка частей речи

Разметка частей речи — это процесс определения части речи каждого слова в предложении. В NLTK для разметки частей речи можно использовать класс pos_tag:
from nltk import pos_tag
from nltk.tokenize import word_tokenize
text = "Исследование текстовых данных на языке Python с использованием NLTK"
tokens = word_tokenize(text)
tags = pos_tag(tokens)
print(tags)
Результат:
[('Исследование', 'NN'), ('текстовых', 'JJ'), ('данных', 'NN'), ('на', 'IN'), ('языке', 'NN'), ('Python', 'NNP'), ('с', 'IN'), ('использованием', 'NN'), ('NLTK', 'NNP')]
В данной статье были рассмотрены основные инструменты библиотеки NLTK для анализа текстовых данных на языке Python. NLTK предоставляет широкий набор возможностей, которые позволяют эффективно проводить анализ и обработку текстовых данных в различных сферах, таких как лингвистика, машинное обучение, информационный поиск и другие.
Практические примеры использования NLTK
Модуль nltk (Natural Language Toolkit) является одной из наиболее популярных библиотек для работы с текстовыми данными в языке программирования Python. Он предоставляет широкий набор основных методов и функций для анализа естественного языка.
Вот несколько практических примеров использования nltk для анализа текстовых данных:
-
Токенизация текста
Одним из основных методов nltk является токенизация, которая разделяет текст на отдельные слова или токены. Например, можно использовать метод nltk.word_tokenize() для разделения предложения на отдельные слова:
import nltk
nltk.word_tokenize("Привет, мир!")
# Output: ['Привет', ',', 'мир', '!']
-
Удаление стоп-слов
Часто в текстах встречаются так называемые стоп-слова, которые не несут смысловой нагрузки и могут быть исключены из анализа. NLTK предоставляет список стоп-слов для многих языков, включая русский. Например, можно использовать метод nltk.corpus.stopwords.words(‘russian’) для получения списка стоп-слов на русском языке:
import nltk
russian_stopwords = nltk.corpus.stopwords.words('russian')
-
Лемматизация текста
Лемматизация — это процесс приведения слова к его нормальной форме, по основе которой можно определить его семантическое значение. NLTK предоставляет метод nltk.WordNetLemmatizer() для лемматизации слов. Например, можно использовать следующий код для лемматизации слова:
import nltk
lemmatizer = nltk.WordNetLemmatizer()
lemmatizer.lemmatize('бежала', pos='v')
# Output: 'бежать'
-
Анализ частей речи
Определение частей речи в тексте может быть полезным для понимания контекста и смысла слов. NLTK предоставляет метод nltk.pos_tag() для маркировки слов с их частями речи. Например, можно использовать следующий код для анализа частей речи в предложении:
import nltk
nltk.pos_tag(['Я', 'люблю', 'программирование'])
# Output: [('Я', 'PRP'), ('люблю', 'VBP'), ('программирование', 'NN')]
-
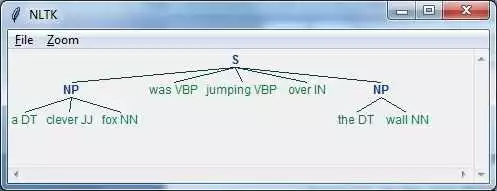
Шаблонное сопоставление
NLTK также предоставляет возможности для шаблонного сопоставления текста с использованием регулярных выражений. Метод nltk.RegexpParser() позволяет создавать грамматические правила и искать соответствия в тексте. Например, можно использовать следующий код для поиска соответствий в предложении:
import nltk
grammar = nltk.CFG.fromstring("""
S -> NP VP
...
""")
parser = nltk.RegexpParser(grammar)
sentence = [('Я', 'PRP'), ('люблю', 'VBP'), ('программирование', 'NN')]
result = parser.parse(sentence)
Это лишь некоторые из примеров использования nltk для анализа текстовых данных. Благодаря своим мощным функциям и широкой поддержке научного сообщества, nltk является незаменимым инструментом для работы с данными естественного языка в Python.