Scikit-learn — одна из самых популярных библиотек для машинного обучения на языке Python. Она предоставляет широкий спектр инструментов и алгоритмов для анализа данных, обработки и использования моделей машинного обучения. Однако, при работе с большими объемами данных и сложными задачами, процесс обучения моделей может занимать много времени, что затрудняет их реализацию в рабочем окружении.

Индивидуальный график
Индивидуальный график
Индивидуальный график
В статье мы рассмотрим различные способы ускорения процесса обучения моделей с использованием библиотеки Scikit-learn. Благодаря оптимизации кода и использованию параллельных вычислений, можно существенно сократить время выполнения алгоритмов и улучшить эффективность работы.
Одним из способов ускорения процесса машинного обучения является распределение задач на несколько ядер процессора через параллельное программирование. Scikit-learn позволяет использовать несколько ядер процессора для обработки данных одновременно, что позволяет значительно увеличить скорость обучения моделей.
Еще одним методом ускорения процесса обучения моделей в библиотеке Scikit-learn является использование специальных алгоритмов и техник укорачивания исходных данных. Некоторые задачи машинного обучения могут быть решены не с использованием всей доступной информации, а только с ее частью. Это позволяет значительно снизить время выполнения алгоритмов и улучшить производительность моделей.
В дополнение к вышеизложенному, в статье будут рассмотрены такие способы ускорения процесса обучения моделей как улучшение алгоритмов и оптимизация кода, а также использование параллельного выполнения операций и эффективного распределения данных. Эти рекомендации и советы помогут вам значительно ускорить процесс машинного обучения и повысить эффективность вашей работы с помощью библиотеки Scikit-learn.
Ускорение процесса машинного обучения на Python с помощью библиотеки Scikit-learn: рекомендации и советы
Scikit-learn — это мощная библиотека для машинного обучения на языке программирования Python. Однако, при работе с большими наборами данных или сложными моделями, процесс обучения может быть довольно медленным. В данной статье будут представлены рекомендации и советы по ускорению машинного обучения с помощью Scikit-learn.
- Выбор эффективных алгоритмов и моделей: При выборе алгоритмов и моделей для решения задач машинного обучения, необходимо учесть их эффективность и скорость работы. Некоторые алгоритмы могут быть более подходящими для конкретных задач и иметь меньшую вычислительную сложность.
- Оптимизация данных: Перед началом процесса обучения модели, рекомендуется провести оптимизацию данных. Это может включать в себя удаление выбросов, нормализацию и масштабирование данных, а также заполнение пропущенных значений. Оптимизация данных поможет улучшить качество модели и сократить время обучения.
- Использование распределенных вычислений: Для обработки больших объемов данных и ускорения процесса обучения можно использовать распределенные вычисления. Это позволяет параллельно обрабатывать данные на нескольких компьютерах или устройствах, что существенно повышает производительность.
- Увеличение производительности с помощью языка программирования Python: Python является интерпретируемым языком, что может ухудшать производительность при работе с большими объемами данных. Для ускорения процесса обучения рекомендуется использовать компилируемые языки программирования, такие как C++ или Java.
- Укорачивание времени обработки данных: При подготовке данных для обучения модели, можно использовать различные методы для укорачивания времени их обработки. Например, можно сократить размерность данных с помощью метода главных компонент (PCA), использовать случайные выборки данных для обучения или применить алгоритмы сэмплирования данных.
- Применение параллельной обработки: Scikit-learn предоставляет возможность использовать параллельную обработку данных, что позволяет ускорить процесс обучения моделей. Для этого можно использовать параметр «n_jobs», который указывает количество потоков для параллельной обработки.
- Снижение времени выполнения алгоритмов: Некоторые алгоритмы машинного обучения имеют достаточно высокую вычислительную сложность, что замедляет процесс обучения. В таких случаях рекомендуется использовать алгоритмы снижения размерности данных, такие как алгоритмы PCA или алгоритмы выбора признаков (feature selection).
В результате применения данных рекомендаций и советов, можно значительно ускорить процесс машинного обучения на Python с помощью библиотеки Scikit-learn. Это позволит сократить время работы и увеличить производительность моделей.
Использование этих рекомендаций и советов в реализации проектов машинного обучения с помощью библиотеки Scikit-learn позволит существенно повысить эффективность и скорость работы моделей.
Преимущества использования библиотеки Scikit-learn

Scikit-learn — это библиотека машинного обучения, написанная на языке программирования Python. Она позволяет значительно ускорить процесс разработки и реализации алгоритмов машинного обучения, а также повысить эффективность обработки данных.
Одно из главных преимуществ использования Scikit-learn — это улучшение скорости выполнения задач машинного обучения. Благодаря оптимизации и распределению процедур обучения, библиотека позволяет снизить время реализации моделей и ускорить работу с данными.
С помощью Scikit-learn также возможно укорачивание процесса программирования за счет использования готовых алгоритмов и функций обработки данных. Библиотека предоставляет широкий набор встроенных методов и инструментов, что упрощает разработку сложных моделей и алгоритмов.
Одним из главных преимуществ использования Scikit-learn является ускорение процесса обучения модели. Библиотека предоставляет оптимизированные алгоритмы обучения, которые значительно сокращают время обучения и увеличивают производительность моделей.
Применение Scikit-learn также позволяет увеличить эффективность работы с данными. Библиотека предоставляет удобные инструменты для предобработки данных, включая масштабирование, нормализацию и обработку пропущенных значений. Это позволяет с легкостью подготовить и очистить данные перед обучением модели.
Scikit-learn также предоставляет удобный интерфейс для работы с различными типами моделей и алгоритмов машинного обучения. Библиотека поддерживает широкий набор методов классификации, регрессии, кластеризации и многих других задач. Это позволяет упростить работу с различными типами данных и реализовать сложные модели с минимальными усилиями.
В заключение, использование библиотеки Scikit-learn на языке программирования Python позволяет получить ряд значительных преимуществ, таких как ускорение процесса обучения, оптимизация производительности моделей и обработка данных с помощью простых и удобных инструментов.
Обширный выбор алгоритмов машинного обучения

Работы по машинному обучению обычно требуют значительного объема вычислений и обработки данных. С помощью библиотеки Scikit-learn на языке программирования Python можно существенно ускорить процесс выполнения этих задач и повысить эффективность работы.
Scikit-learn предоставляет обширный выбор алгоритмов машинного обучения для реализации и оптимизации моделей обучения. Благодаря использованию этой библиотеки, процесс обучения моделей становится гораздо более эффективным.
Одно из главных преимуществ использования Scikit-learn заключается в возможности ускорения процедуры обучения моделей с помощью сокращения времени выполнения задач. Библиотека позволяет улучшить производительность и скорость обработки данных путем повышения рабочего распределения и снижения времени реализации.
Кроме того, использование Scikit-learn позволяет увеличить эффективность работы с данными и ускорить процесс обработки данных. Библиотека предлагает различные алгоритмы машинного обучения, которые могут быть использованы для решения различных задач обработки данных.
Возможности Scikit-learn позволяют усилить процесс машинного обучения через применение различных алгоритмов, что приводит к улучшению качества моделей. Библиотека предлагает широкий выбор алгоритмов, таких как линейная регрессия, SVM, случайный лес и др., которые могут быть использованы в зависимости от требований проекта.
| Преимущества использования Scikit-learn: |
|
В итоге, использование Scikit-learn позволяет ускорить процесс машинного обучения на Python и сделать его более эффективным. Библиотека предлагает большой выбор алгоритмов машинного обучения, которые могут быть использованы для различных задач обработки данных.
Простота использования и интеграция в Python

Библиотека Scikit-learn предоставляет множество возможностей для повышения эффективности и ускорения процесса машинного обучения на языке Python. Она упрощает и ускоряет разработку и реализацию алгоритмов машинного обучения, а также оптимизирует процедуры выполнения задач благодаря своей гибкости и простоте использования.
Scikit-learn позволяет использовать различные модели и алгоритмы машинного обучения для улучшения производительности и скорости работы. Благодаря применению библиотеки Scikit-learn, процесс обучения моделей машинного обучения становится более эффективным и быстрым.
Одним из главных преимуществ использования Scikit-learn является его интеграция с Python. Библиотека полностью реализована на языке Python и улучшает процедуру обработки и распределение работы между различными ядрами процессора. Это обеспечивает значительное ускорение процесса обучения моделей машинного обучения.
Scikit-learn также позволяет использовать параллельное выполнение задач через простое и интуитивное использование мультипоточности и многопоточности на языке Python. Это позволяет снизить время выполнения задачи за счет укорачивания рабочего времени и повышения производительности процессора.
Библиотека Scikit-learn также предоставляет возможности для улучшения процесса обучения моделей машинного обучения через использование различных методов и техник. Она обладает встроенными функциями для увеличения скорости обучения и ускорения процесса машинного обучения, что позволяет сократить время, необходимое для обучения моделей.
В заключение, использование библиотеки Scikit-learn в Python упрощает и ускоряет процесс машинного обучения. Она позволяет снизить время выполнения задач благодаря эффективности и ускорению алгоритмов, а также использованию параллельных вычислений. Scikit-learn обеспечивает интеграцию с Python, что делает его мощным инструментом для работы с моделями машинного обучения на языке Python.
Высокая производительность и оптимизация
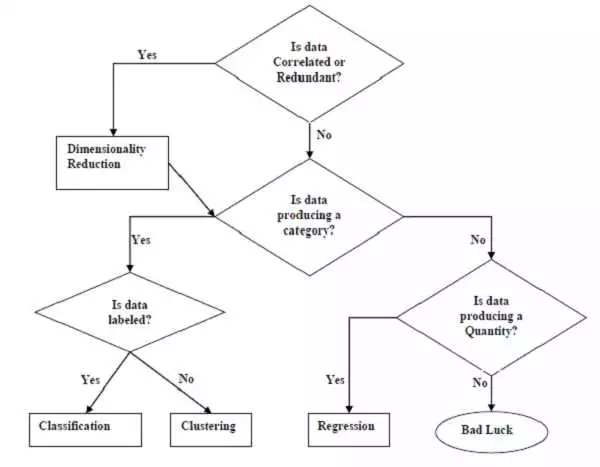
При работе с машинным обучением на языке программирования Python, обработка больших объемов данных может стать долгой и ресурсоемкой процедурой. Однако с помощью библиотеки Scikit-learn существуют методы ускорения выполнения задач обучения и работы с данными.
Оптимизация процесса машинного обучения может быть достигнута с помощью использования различных алгоритмов и методов распределения задач на множество ядер процессора. Это позволяет улучшить скорость работы моделей и сократить время обучения.
Scikit-learn предоставляет возможность использования параллельных вычислений через библиотеку Joblib. С ее помощью можно распараллелить процесс обучения моделей, что приведет к увеличению производительности и существенному сокращению времени обработки данных.
Для ускорения процесса обучения моделей в Scikit-learn можно использовать различные методы оптимизации параметров модели, например, использование SGD-оптимизаторов или методов случайного поиска гиперпараметров.
Повышение производительности также может быть достигнуто за счет улучшения эффективности алгоритмов и оптимизации кода. В Scikit-learn реализованы многие оптимизированные алгоритмы машинного обучения, что позволяет достичь ускорения выполнения задач.
Ускорение процесса машинного обучения также возможно с помощью использования более эффективных алгоритмов, например, алгоритмов градиентного бустинга или случайного леса. Эти алгоритмы позволяют достичь высокой скорости работы моделей и дать хороший результат, особенно при работе с большими объемами данных.
Разгон процесса машинного обучения на Python также можно достичь с помощью использования различных техник оптимизации кода, например, векторизации вычислений или использования более эффективных структур данных. Такие методы позволяют снизить время обработки данных и повысить производительность программы.
Оптимизация процесса машинного обучения в библиотеке Scikit-learn может быть достигнута также с помощью использования параллельной обработки данных. Для этого можно воспользоваться модулем Joblib, который предоставляет инструменты для распределенного выполнения задач и ускорения обработки данных.
Таким образом, с помощью библиотеки Scikit-learn и использования различных методов оптимизации и улучшения производительности можно достичь высокой скорости работы при обучении моделей и обработке данных.
Основные рекомендации для ускорения процесса машинного обучения на Python
Ускорение процесса машинного обучения на Python является важным аспектом программирования в области искусственного интеллекта и анализа данных. С этой целью рекомендуется использование различных техник и инструментов, которые позволяют повысить эффективность и производительность выполнения алгоритмов машинного обучения.
-
Использование библиотеки scikit-learn:
Библиотека scikit-learn является одной из основных библиотек для реализации алгоритмов машинного обучения на языке программирования Python. Ее использование позволяет сократить время разработки и реализации моделей машинного обучения благодаря большому количеству готовых и оптимизированных методов и функций.
-
Оптимизация процедуры обучения:
При обучении моделей машинного обучения часто требуется большое количество времени на обработку и анализ данных. Для ускорения процесса можно применять различные техники оптимизации, такие как использование распределенных вычислений, снижение размерности данных и предварительная обработка данных.
-
Улучшение работы алгоритмов:
Для увеличения скорости выполнения алгоритмов машинного обучения можно использовать различные методы улучшения эффективности, такие как укорачивание итераций алгоритмов, сокращение числа признаков, оптимизация гиперпараметров и использование параллельных вычислений.
-
Повышение производительности аппаратного обеспечения:
Для ускорения процесса машинного обучения на Python можно использовать более мощное аппаратное обеспечение, такое как многоядерные процессоры, графические процессоры (GPU) и облачные вычисления. Это позволяет распараллелить вычисления и повысить общую производительность системы.
В итоге, ускорение процесса машинного обучения на Python с помощью библиотеки scikit-learn достигается благодаря оптимизации процедуры обучения, улучшению работы алгоритмов, повышению производительности аппаратного обеспечения и использованию эффективных методов и техник. Это позволяет снизить время обучения моделей, улучшить качество результатов и повысить эффективность работы системы.
Правильный выбор алгоритмов и параметров моделей

При работе с библиотекой Scikit-learn в Python для ускорения процесса машинного обучения рекомендуется правильно выбирать алгоритмы и параметры моделей. Это позволяет достичь повышения производительности и ускорения работы программы при обработке данных.
Оптимизация работы моделей на основе использования подходящих алгоритмов является важным шагом в процедуре машинного обучения. Укорачивание времени выполнения происходит благодаря использованию эффективных алгоритмов и параметров, что позволяет увеличить скорость обработки данных и сократить время работы модели.
Для улучшения скорости работы моделей в библиотеке Scikit-learn рекомендуется использование распределения задач параллельной обработки данных с помощью языка программирования Python. Это позволяет распределить процесс обучения модели на несколько ядер процессора, что приводит к ускорению выполнения программы.
Важным аспектом для повышения производительности является выбор оптимального набора алгоритмов и параметров моделей. Ускорение процесса обучения модели может быть достигнуто путем оптимизации использования ресурсов и снижения затрат времени на выполнение алгоритмов.
Библиотека Scikit-learn позволяет применение различных алгоритмов машинного обучения с использованием разных параметров, что позволяет ускорить процесс обучения и повысить производительность модели. При правильном выборе алгоритмов и параметров моделей можно добиться сокращения времени обучения и ускорения работы модели.
Оптимальный выбор алгоритмов и параметров моделей может быть осуществлен с помощью применения различных методов и техник обучения. Использование кросс-валидации, перебора параметров с помощью сетки и других подходов может помочь определить оптимальный набор алгоритмов и параметров для конкретной задачи.
Таким образом, правильный выбор алгоритмов и параметров моделей является важным условием для ускорения процесса машинного обучения на Python с помощью библиотеки Scikit-learn. Это позволяет улучшить скорость работы моделей, сократить время обучения и повысить производительность обработки данных.
Оптимизация работы с данными и их предобработка

Оптимизация работы с данными и их предобработка являются важными шагами в процессе машинного обучения. Снижение времени обработки данных и ускорение выполнения задач обеспечивают более эффективное и производительное использование алгоритмов и моделей машинного обучения.
Для ускорения работы с данными и их предобработки широко используется библиотека Scikit-learn, написанная на языке программирования Python. Scikit-learn предоставляет множество функций и методов для оптимизации и улучшения процесса обработки данных.
Применение Scikit-learn позволяет увеличить скорость выполнения процедур предобработки и укоротить рабочее время благодаря использованию готовых методов и алгоритмов, реализованных в библиотеке. С помощью Scikit-learn можно эффективно работать с данными, применяя различные методы и подходы для их обработки и анализа.
Одним из способов оптимизации работы с данными и их предобработки является использование распределённых вычислительных методов, которые ускоряют процесс обработки данных. Благодаря применению распределённых методов можно увеличить производительность и сократить время выполнения задач обработки данных.
Другими методами оптимизации работы с данными являются использование параллельных вычислений и многопоточности. Применение этих методов позволяет ускорить процесс обработки большого объема данных и увеличить эффективность работы машинного обучения.
Также важным аспектом оптимизации работы с данными является укорачивание процедур предобработки данных. Удаление или сокращение неинформативных признаков позволяет улучшить процесс обработки данных и повысить качество и точность моделей машинного обучения.
Использование методов и функций библиотеки Scikit-learn для оптимизации работы с данными и их предобработки существенно улучшает производительность и эффективность процесса машинного обучения. Благодаря использованию Scikit-learn можно достичь снижения времени обработки данных, ускорения выполнения задач и улучшения производительности моделей машинного обучения.
В итоге, использование библиотеки Scikit-learn с применением различных методов и подходов для оптимизации работы с данными и их предобработки является важным шагом для достижения высокой эффективности в процессе машинного обучения.
Распараллеливание вычислений и использование ресурсов

Улучшение производительности выполняемых задач в машинном обучении с использованием библиотеки Scikit-learn осуществляется благодаря ускорению выполнения алгоритмов с помощью распараллеливания вычислений и оптимизации использования ресурсов.
Scikit-learn – это библиотека для обучения с учителем и обучения без учителя на языке программирования Python. Она предоставляет широкий набор алгоритмов и функций для реализации различных задач машинного обучения. Однако, выполнение вычислительно сложных задач, особенно с большими объемами данных, может занимать значительное время.
Для ускорения работы алгоритмов машинного обучения с использованием Scikit-learn можно применить распараллеливание вычислений. Это позволяет выполнить вычисления параллельно на нескольких ядрах процессора, сократив время выполнения задачи. Также, распараллеливание позволяет эффективнее использовать доступные ресурсы и увеличить производительность работы с большими объемами данных.
Scikit-learn предоставляет инструменты для распараллеливания работы алгоритмов. Например, для распараллеливания обработки данных можно использовать функции из модуля joblib. С помощью них можно ускорить выполнение и повысить эффективность работы с моделями машинного обучения.
Другим методом ускорения процесса машинного обучения с использованием Scikit-learn является использование ресурсов рабочего процесса. Здесь можно выделить укорачивание времени обработки данных, увеличение скорости обучения моделей и снижение временных затрат на выполнение алгоритмов.
Использование ресурсов рабочего процесса достигается через оптимизацию выполнения задач машинного обучения. Например, можно использовать распределенное выполнение, при котором задачи разделяются на несколько частей и выполняются одновременно на разных ресурсах. Также, можно применять оптимизацию алгоритмов и параметров моделей для улучшения их эффективности и ускорения работы.
Таким образом, благодаря использованию распараллеливания вычислений и оптимизации использования ресурсов в процессе машинного обучения с помощью библиотеки Scikit-learn, можно значительно увеличить скорость работы алгоритмов и сократить временные затраты на обработку данных. Это помогает повысить эффективность обучения моделей и обеспечить более быстрое и точное решение задач.
Советы по улучшению процедуры машинного обучения на языке программирования Python

Процесс машинного обучения на языке программирования Python может быть улучшен и оптимизирован благодаря использованию различных советов и методов. Ниже приведены несколько рекомендаций для повышения эффективности и производительности процедуры машинного обучения.
- Использование библиотеки scikit-learn: Для выполнения задач машинного обучения рекомендуется использовать библиотеку scikit-learn. Она предоставляет широкий набор инструментов и алгоритмов для обучения моделей, обработки данных и валидации результатов.
- Оптимизация данных: Перед началом процесса обучения моделей рекомендуется произвести оптимизацию данных. Это может включать в себя удаление дубликатов, обработку пропущенных значений и шума, масштабирование признаков или преобразование категориальных переменных.
- Повышение скорости обработки данных: Для ускорения работы с данными можно использовать различные методы, такие как распределенная обработка с помощью библиотеки Dask или использование многопоточности с помощью библиотеки multiprocessing.
- Улучшение алгоритмов: Реализация более эффективных алгоритмов может значительно ускорить процесс обучения моделей. Для этого можно использовать методы оптимизации, такие как градиентный спуск или случайный лес, а также учитывать особенности задачи машинного обучения при выборе алгоритма.
- Укорачивание времени выполнения: Время выполнения процедуры машинного обучения можно сократить путем уменьшения объема данных или регулирования параметров моделей. Например, можно использовать случайное подмножество данных для обучения и валидации моделей, а также установить оптимальные значения параметров модели.
- Использование распределенных вычислений: Для обработки больших объемов данных и ускорения процесса машинного обучения можно воспользоваться распределенными вычислениями. Например, можно использовать библиотеки Apache Spark или Dask для распределенной обработки данных и параллельного выполнения алгоритмов.
Внедрение этих советов и методов поможет улучшить процедуру машинного обучения на языке программирования Python и достичь более высокой эффективности и скорости работы моделей.