Python — один из наиболее популярных языков программирования при создании и разработке моделей машинного обучения. С помощью этого языка и библиотеки Scikit-learn можно легко реализовать построение и обучение модели линейной регрессии.

Индивидуальный график
Индивидуальный график
Индивидуальный график
Scikit-learn — это библиотека, распространяемая на условиях BSD-лицензии, предоставляющая широкие возможности по применению различных алгоритмов машинного обучения. В том числе, Scikit-learn обладает удобными инструментами для формирования и тренировки модели линейной регрессии.
Для использования Scikit-learn и создания модели регрессии на Python необходимо установить данную библиотеку с помощью пакетного менеджера pip. После установки библиотеки можно приступить к программированию и обучению модели линейной регрессии.
Реализация модели линейной регрессии с использованием Scikit-learn начинается с импорта необходимых классов и функций из библиотеки. Затем следует создание экземпляра модели с помощью вызова соответствующего конструктора. После этого можно приступить к загрузке и предварительной обработке данных, а затем к обучению модели с использованием метода fit(). После обучения модели можно применить его при анализе новых данных с помощью метода predict().
Создание модели регрессии на Python с помощью Scikit-learn
Scikit-learn — это библиотека машинного обучения, разработанная на языке программирования Python. Она предоставляет широкий набор инструментов и возможностей для создания, обучения и применения моделей машинного обучения. В данной статье рассмотрим процесс создания модели регрессии с использованием Scikit-learn.
Построение модели регрессии с помощью Scikit-learn включает в себя следующие этапы:
- Импортирование библиотеки Scikit-learn:
- Создание и обучение модели:
- Предсказание значений:
- Оценка качества модели:
from sklearn.linear_model import LinearRegressionmodel = LinearRegression()
model.fit(X, y)
predictions = model.predict(X_test)model.score(X_test, y_test)На этапе конструирования модели регрессии с помощью Scikit-learn мы создаем экземпляр класса LinearRegression. Для обучения модели необходимо предоставить данные, состоящие из независимых переменных X и зависимой переменной y. После создания и обучения модели, мы можем использовать ее для предсказания значений на новых данных.
При обучении модели регрессии, Scikit-learn использует метод наименьших квадратов, который позволяет определить линейную связь между независимыми и зависимой переменными.
При разработке модели регрессии с помощью Scikit-learn на языке программирования Python, программа состоит из следующих шагов:
- Импорт необходимых библиотек:
- Чтение данных из файла или источника данных:
- Формирование независимых и зависимых переменных:
- Разделение данных на обучающую и тестовую выборки:
- Создание и обучение модели:
- Предсказание значений:
- Оценка качества модели:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
data = pd.read_csv('data.csv')X = data[['feature1','feature2']]
y = data['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)model = LinearRegression()
model.fit(X_train, y_train)
predictions = model.predict(X_test)model.score(X_test, y_test)Реализация модели регрессии с использованием Scikit-learn позволяет создать линейную модель, которая может предсказывать значения зависимой переменной на основе заданных независимых переменных. Эта модель может быть использована в различных приложениях, включая прогнозирование продаж, цен на недвижимость и других ситуациях, когда необходимо предсказать непрерывные значения.
Создание модели регрессии на языке программирования Python с помощью библиотеки Scikit-learn является эффективным и удобным способом для решения задач прогнозирования и анализа данных.
Установка и импорт необходимых библиотек
Конструирование модели регрессии – один из ключевых шагов при разработке алгоритмов машинного обучения. Для создания и обучения модели используется язык программирования Python с применением библиотеки scikit-learn. Данная библиотека позволяет удобно и эффективно реализовывать линейную регрессию.
Для начала необходимо установить библиотеку scikit-learn. Для этого можно использовать команду в командной строке:
pip install scikit-learn
После успешной установки можно приступить к импорту необходимых библиотек в проект. Для создания и обучения модели регрессии на Python с использованием библиотеки scikit-learn необходимо импортировать следующие модули:
- from sklearn.linear_model import LinearRegression – модуль для создания модели линейной регрессии
- from sklearn.model_selection import train_test_split – модуль для разделения данных на обучающую и тестовую выборки
- from sklearn.metrics import mean_squared_error – модуль для подсчета среднеквадратичной ошибки модели
Теперь, после импорта необходимых модулей, можно приступить к созданию и обучению модели регрессии на Python с помощью scikit-learn.
Установка Python и Scikit-learn
На сегодняшний день Python является самым популярным языком программирования с открытым исходным кодом. С помощью этого языка можно реализовать множество задач, в том числе и создание и обучение моделей машинного обучения.
Для разработки моделей машинного обучения с применением библиотеки Scikit-learn необходимо установить Python и саму библиотеку. В данном разделе мы рассмотрим процесс установки.
- Сначала необходимо скачать и установить Python. Перейдите на официальный сайт Python (https://www.python.org) и скачайте последнюю версию Python для вашей операционной системы.
- Запустите установщик Python и следуйте инструкциям по установке. Не забудьте поставить галочку «Add Python to PATH» (Добавить Python в PATH), что позволит использовать Python из командной строки.
- После завершения установки проверьте, что Python правильно установлен, введя команду
python --versionв командной строке. Если версия Python отобразилась, значит установка прошла успешно. - Теперь вы можете установить библиотеку Scikit-learn. Для этого воспользуйтесь инструментом установки пакетов в Python — pip. Введите команду
pip install scikit-learnдля установки последней версии библиотеки. - После установки Scikit-learn, проверьте, что она успешно установлена, введя команду
pythonв командной строке, а затемimport sklearn. Если не возникло ошибок, значит Scikit-learn была успешно установлена.
Теперь вы готовы к созданию и обучению модели регрессии на Python с помощью библиотеки Scikit-learn. Дальнейшее формирование модели, построение обучающей выборки, тренировка и использование модели будет осуществляться с помощью данной библиотеки и языка программирования Python.
Импорт необходимых библиотек

Для формирования, создания и конструирования модели линейной регрессии на языке Python существует множество библиотек. Одна из наиболее популярных и мощных библиотек для обучения моделей регрессии — это scikit-learn.
Scikit-learn — это библиотека, разработанная для построения и использования различных моделей машинного обучения, включая модели регрессии. С ее помощью можно легко создавать программы на языке Python, основанные на применении и тренировке моделей регрессии.
Для использования scikit-learn для обучения моделей регрессии необходимо импортировать соответствующие библиотеки. Для этого можно воспользоваться следующим кодом:
import sklearn
from sklearn.linear_model import LinearRegression
В данном примере мы используем модуль «linear_model» из библиотеки scikit-learn, который содержит класс LinearRegression для создания и обучения моделей линейной регрессии.
После импорта необходимых библиотек мы можем начать разработку и создание нашей модели регрессии с помощью scikit-learn.
Подготовка данных для обучения модели
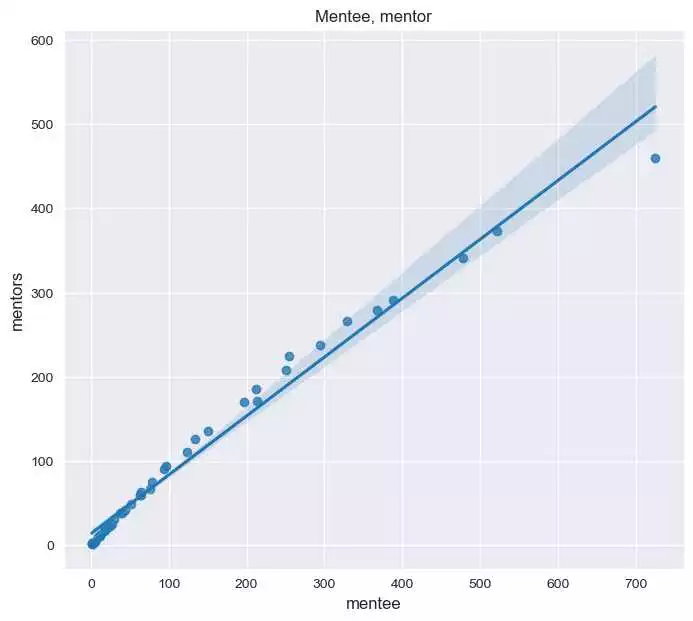
При построении модели регрессии на Python с применением библиотеки scikit-learn необходимо правильно подготовить данные для обучения. Это включает в себя изготовление, формирование и реализацию тренировочного набора данных, которые будут использоваться для создания модели. В этом разделе мы рассмотрим основные этапы подготовки данных для обучения модели регрессии с помощью программирования на языке Python.
- Импорт библиотеки scikit-learn
- Загрузка данных
- Выбор признаков
- Разделение на тренировочный и тестовый наборы данных
- Нормализация данных
- Обучение модели
Первым шагом необходимо импортировать библиотеку scikit-learn, которая предоставляет возможности для создания и обучения моделей регрессии. Для этого используется следующий код:
from sklearn import linear_modelСледующим шагом является загрузка данных, на основе которых будет проводиться обучение модели. Данные могут быть загружены из различных источников, например из файла CSV или базы данных. Для загрузки данных из файла CSV можно использовать следующий код:
import pandas as pd
data = pd.read_csv("data.csv")
После загрузки данных необходимо выбрать признаки или переменные, которые будут использоваться для обучения модели. Признаки должны быть числовыми и могут быть выбраны на основе предварительного анализа данных или экспертного мнения. Например, в задаче прогнозирования цены на недвижимость в качестве признаков могут быть выбраны площадь дома, количество спален и расстояние до ближайшего города.
Для оценки качества модели необходимо разделить данные на тренировочный и тестовый наборы. Тренировочный набор будет использоваться для обучения модели, а тестовый набор — для проверки ее точности на новых данных. Для разделения данных можно использовать следующий код:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
Для обеспечения более стабильных результатов рекомендуется нормализовать данные. Нормализация позволяет привести все признаки к одному масштабу и избежать проблем с весами признаков в модели. Нормализация может быть выполнена с помощью следующего кода:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
Последним шагом является создание и обучение модели регрессии. Для этого используется код:
model = linear_model.LinearRegression()
model.fit(X_train_scaled, y_train)
Теперь вы готовы к созданию и обучению модели регрессии на языке Python с помощью библиотеки scikit-learn. Помните, что подготовка данных является важным этапом в процессе построения модели регрессии, и правильно подготовленные данные могут значительно повлиять на точность и надежность модели.
Загрузка и изучение данных
Создание и обучение модели регрессии является одной из важных задач в анализе данных. Для этого необходимо иметь набор данных, на котором модель будет обучаться.
Для конструирования модели регрессии с помощью языка программирования Python и применения библиотеки scikit-learn необходимо загрузить данные. Этот шаг является первым и одним из самых важных при составлении модели.
Изготовление модели регрессии с помощью Python и применением библиотеки scikit-learn возможно только при наличии данных. Поэтому составление набора данных является неотъемлемой частью процесса разработки модели.
Для загрузки данных в Python существует множество методов. При выборе способа загрузки данных необходимо учитывать их формат и размер. Часто данные представлены в виде таблицы, для работы с которой удобно использовать библиотеки pandas.
После загрузки данных и их предварительного анализа можно переходить к тренировке модели регрессии с помощью библиотеки scikit-learn. Обучение модели происходит на основе имеющихся данных, что позволяет модели изучить зависимости между входными и выходными данными и запомнить их для дальнейшего использования.
Построение модели регрессии с использованием языка программирования Python и библиотеки scikit-learn осуществляется путем создания экземпляра класса LinearRegression и передачи ему обучающих данных.
Формирование модели регрессии с помощью scikit-learn включает в себя следующие шаги:
- Загрузка данных
- Анализ данных
- Тренировка модели
- Построение модели
При реализации модели линейной регрессии с использованием языка программирования Python и библиотеки scikit-learn необходимо соблюдать определенные этапы обучения модели, а именно: загрузка данных, анализ данных, тренировка модели и построение модели.
Таким образом, загрузка и изучение данных являются важными шагами при создании и обучении модели регрессии с помощью языка программирования Python и библиотеки scikit-learn.
Подготовка данных для обучения
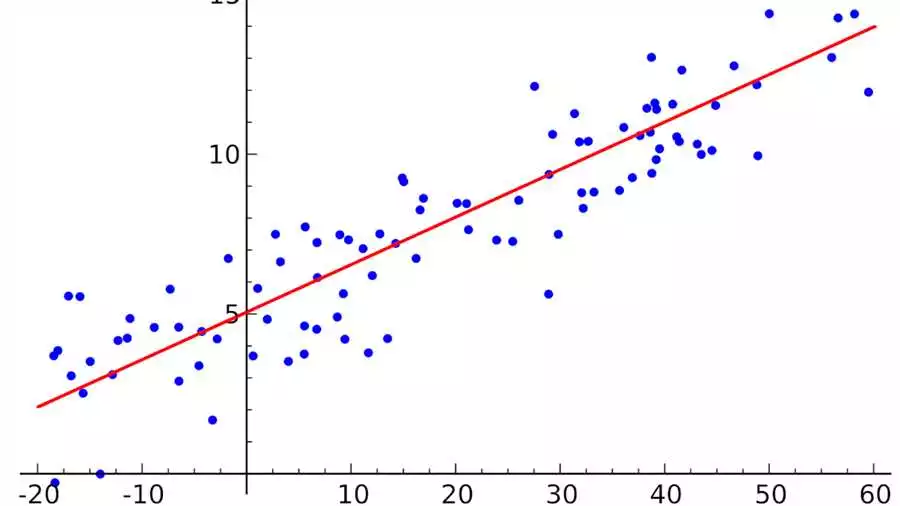
При создании и обучении модели регрессии на Python с помощью библиотеки Scikit-learn, одним из важных этапов является подготовка данных для обучения. Этот этап включает в себя различные процессы, такие как создание, обучение и построение модели.
Изготовление модели регрессии включает в себя использование языка программирования Python с помощью библиотеки Scikit-learn. Scikit-learn предоставляет удобный интерфейс и широкий набор функций для конструирования и формирования моделей регрессии.
Для применения модели регрессии с помощью Python и библиотеки Scikit-learn необходимы надлежащие данные. Перед тренировкой модели необходимо реализовать ряд шагов по обработке данных и выполнить предварительную подготовку данных.
Основными этапами подготовки данных для обучения модели регрессии являются:
- Импорт необходимых библиотек
- Загрузка и предварительный анализ данных
- Обработка пропущенных значений
- Преобразование категориальных признаков в числовые
- Масштабирование данных
- Разделение данных на обучающую и тестовую выборки
При создании и обучении модели регрессии с использованием Python и библиотеки Scikit-learn необходимо учесть, что качество модели зависит от качества и правильности подготовки данных. Поэтому подготовка данных — один из важных этапов в разработке и применении модели регрессии.
Обучение и оценка модели регрессии

Регрессия — это один из методов машинного обучения, который используется для предсказания непрерывного значения на основе входных данных. С помощью Scikit-learn, библиотеки машинного обучения на языке программирования Python, мы можем создавать и обучать модели регрессии.
Процесс создания и обучения модели регрессии с использованием Scikit-learn состоит из нескольких шагов. В первую очередь, необходимо подготовить данные и разделить их на обучающую и тестовую выборки. Затем можно выбрать тип модели регрессии, например, линейной регрессии, и создать экземпляр этой модели.
Далее следует тренировка модели, или обучение, которое заключается в передаче обучающих данных модели. С помощью метода fit() модели передаются значения признаков и соответствующие значения целевой переменной. В результате этой операции модель настраивается на данные и может быть использована для предсказания значений.
Оценка модели регрессии включает в себя различные метрики, которые позволяют оценить качество модели. Например, среднеквадратичное отклонение (MSE) и коэффициент детерминации (R-квадрат) являются распространенными метриками, используемыми для оценки моделей регрессии.
Scikit-learn предоставляет удобные функции для оценки модели, такие как mean_squared_error() и r2_score(). Эти функции могут быть использованы для вычисления метрик качества модели на тестовой выборке. Чем ближе значения метрик к нулю (MSE) или единице (R-квадрат), тем лучше модель.
В заключение, создание и обучение модели регрессии с использованием Scikit-learn на языке Python является важным этапом в разработке программ, основанных на машинном обучении. Формирование и обучение модели регрессии позволяет предсказывать значения непрерывной переменной на основе заданных признаков, а оценка модели позволяет оценить ее качество и точность.