Python — это мощный язык программирования, который прилагает много усилий для обработки и анализа данных. Для эффективной работы с данными, существует модуль scikit-learn, который является одной из популярных библиотек машинного обучения для Python.

Индивидуальный график
Индивидуальный график
Индивидуальный график
Машинное обучение представляет собой процесс создания алгоритмических моделей, которые могут извлекать полезную информацию из данных и делать прогнозы или принимать решения на их основе. Scikit-learn — это мощный инструмент для исследования и обучения моделей машинного обучения.
Использование scikit-learn и Python позволяет проводить обширные исследования и анализ данных. Scikit-learn предоставляет широкий спектр алгоритмических моделей, которые можно применять для задач классификации, регрессии, кластеризации, анализа текста и т.д.
Библиотека scikit-learn также предоставляет удобные инструменты для предварительной обработки данных, включая масштабирование, нормализацию, отбор признаков и многое другое. Безусловно, изучение и использование scikit-learn и Python для анализа данных с машинным обучением открывает перед исследователями множество возможностей и новых горизонтов в научных исследованиях и промышленных приложениях.
Машинное обучение с Python: анализ данных с помощью Scikit-learn
Машинное обучение является одной из ключевых областей исследования в настоящее время.
Оно основано на использовании алгоритмических методов и инструментов для анализа, изучения и моделирования данных.
В этой статье мы рассмотрим библиотеку scikit-learn, разработанную на языке программирования Python, которая предоставляет широкий спектр инструментов для обучения и анализа моделей машинного обучения.
Scikit-learn — одна из самых популярных и широко используемых библиотек для машинного обучения в сообществе Python.
Она обеспечивает удобный и эффективный способ работы с различными алгоритмами и моделями машинного обучения.
Библиотека предоставляет разнообразные инструменты для исследования данных, построения моделей, а также их оценки и оптимизации.
Благодаря богатому набору функций, scikit-learn позволяет легко импортировать и использовать модули для различных задач машинного обучения.
Модуль поддерживает различные алгоритмы, такие как линейная регрессия, логистическая регрессия, метод опорных векторов (SVM), случайные леса и многое другое.
Каждый из этих алгоритмов может быть расширен и настроен для конкретных задач и наборов данных.
Основной задачей scikit-learn является анализ данных.
Библиотека предоставляет набор инструментов для обработки данных, таких как масштабирование, нормализация, преобразование признаков, выборка данных и многое другое.
Кроме того, scikit-learn предоставляет функциональность для оценки и сравнения различных моделей машинного обучения, а также для прогнозирования и классификации новых данных.
Одной из главных преимуществ scikit-learn является его простота использования.
Благодаря интуитивно понятному интерфейсу API, пользователи могут легко импортировать и использовать библиотеку для различных задач машинного обучения.
Дополнительно, scikit-learn предоставляет обширную документацию и учебные примеры, что делает процесс изучения и использования библиотеки удобным и доступным.
В заключение, scikit-learn является мощной библиотекой для машинного обучения с Python, предоставляющей широкий спектр инструментов для анализа данных и построения моделей.
С его помощью можно легко и эффективно исследовать данные, строить и настраивать модели машинного обучения, а также выполнять прогнозирование и классификацию новых данных.
Благодаря многочисленным возможностям и простому интерфейсу, scikit-learn позволяет облегчить процесс анализа данных и создания моделей, делая его доступным для широкого круга пользователей.
Python и Scikit-learn для обработки данных
Машинное обучение — это область исследования, которая изучает алгоритмические и статистические модели, позволяющие компьютерам обучаться и делать прогнозы на основе имеющихся данных. Для работы с данными и создания моделей машинного обучения, предлагает множество библиотек и инструментов, а одной из наиболее популярных является Scikit-learn.
Scikit-learn — это библиотека, написанная на языке программирования Python, которая предоставляет широкий набор инструментов для обработки и анализа данных, а также создания и обучения моделей машинного обучения. Она предоставляет простые и интуитивно понятные интерфейсы для работы с различными типами данных и алгоритмами.
Одним из главных модулей Scikit-learn является модуль preprocessing. Он предоставляет функции и методы для обработки данных перед обучением модели. В этом модуле есть инструменты для шкалирования, нормализации, преобразования и кодирования данных, а также для работы с пропущенными значениями.
Использование модуля preprocessing очень важно для успешного обучения моделей машинного обучения. Например, шкалирование данных может быть необходимо, если входные данные имеют разный масштаб, и это может сказаться на качестве модели. Нормализация данных может быть полезна в случае, когда значения разных признаков могут находиться в различных диапазонах.
Еще один важный модуль Scikit-learn — это модуль model_selection, который предоставляет инструменты для выбора модели. Он содержит функции и классы для разделения данных на обучающую и тестовую выборки, подбора параметров модели, оценки качества модели и многое другое.
Используя модуль model_selection, можно провести анализ исследования моделей и выбрать лучшую из них, основываясь на различных метриках и оценках. Это очень важный этап в машинном обучении, так как именно выбор модели и ее параметров сильно влияют на качество предсказания модели.
В целом, Scikit-learn предоставляет мощный и удобный инструментарий для обработки данных и создания моделей машинного обучения. Благодаря своей простоте и гибкости, она позволяет исследователям и разработчикам эффективно изучать и анализировать данные, создавать и обучать модели, и делать предсказания на основе этих моделей.
Python как основной язык для анализа данных
Существует множество языков программирования, предназначенных для работы с данными. Однако, Python становится все более популярным как основной язык для машинного обучения и анализа данных. Поддержка различных библиотек и алгоритмические возможности языка делают его отличным выбором для проведения исследований и изучения данных.
Одной из самых популярных библиотек для анализа данных с помощью Python является библиотека scikit-learn. Она предоставляет обширный набор инструментов для обработки и анализа данных, включая модели машинного обучения, методы препроцессинга и визуализации. Это позволяет исследователям и аналитикам создавать и использовать различные модели для анализа своих данных.
Для работы с данными в Python используется модуль pandas, который обеспечивает удобную работу с табличными данными. Это включает в себя функции для чтения и записи данных, фильтрации, группировки и сортировки. Благодаря pandas и scikit-learn, анализ данных становится более эффективным и удобным.
Одним из основных преимуществ Python в анализе данных является широкий спектр доступных библиотек и модулей. Для обучения моделей машинного обучения доступны различные библиотеки, такие как TensorFlow и Keras. Это позволяет исследователям и аналитикам выбирать наиболее подходящую библиотеку для своих нужд и создавать высокопроизводительные модели.
Python также предлагает много инструментов для обработки данных. Благодаря наличию библиотек, таких как NumPy и SciPy, исследователи могут выполнять математические операции и статистический анализ данных. Это позволяет эффективно обрабатывать и предварительно обрабатывать данные перед применением моделей машинного обучения.
Библиотека scikit-learn облегчает процесс обучения моделей машинного обучения в Python. С ее помощью можно создавать, обучать и оценивать различные модели, такие как линейная регрессия, SVM, решающее дерево и многое другое. Это позволяет исследователям эффективно работать с данными и получать высокое качество результатов.
В целом, Python является мощным и гибким языком программирования для анализа данных. Его внушительный набор библиотек и инструментов делает его идеальным выбором для работы с данными. Благодаря широкому спектру возможностей и простоте использования, Python продолжает оставаться основным языком для машинного обучения и анализа данных.
Scikit-learn: мощная библиотека для машинного обучения

Scikit-learn — это библиотека для обработки и анализа данных с помощью машинного обучения. Она является одним из наиболее популярных инструментов для изучения и использования алгоритмических моделей.
Scikit-learn является модулем Python, который предоставляет широкий набор функций и инструментов для работы с данными, включая различные алгоритмы машинного обучения и методы их анализа. Благодаря этому модулю, исследователь может использовать богатый набор алгоритмов и методов для обработки и анализа данных, а также создания и оценки моделей.
Scikit-learn предоставляет множество моделей для машинного обучения, включая алгоритмы классификации, регрессии, кластеризации и методы понижения размерности данных. Это позволяет исследователям и инженерам использовать различные подходы и техники для решения задач анализа данных.
Одним из главных преимуществ Scikit-learn является его простота использования. Библиотека предоставляет простой и понятный интерфейс для работы с данными и моделями машинного обучения. Это делает процесс изучения и использования Scikit-learn более эффективным и удобным.
Библиотека Scikit-learn также обладает широким набором инструментов для предобработки данных, включая методы для обработки пропущенных значений, масштабирования данных, кодирования категориальных переменных и многое другое. Это позволяет исследователям обрабатывать данные до их использования в моделях машинного обучения и повышает качество работы моделей.
В заключение, Scikit-learn — мощная и популярная библиотека, предоставляющая широкий набор моделей и инструментов для машинного обучения. Ее простота использования, богатый функционал и высокая производительность делают Scikit-learn предпочтительным выбором для исследования и анализа данных с помощью Python.
Анализ данных с помощью Scikit-learn
Машинное обучение становится все более популярным в наше время, и многие исследователи и разработчики используют его для обработки и анализа данных. Один из наиболее распространенных инструментов для работы с машинным обучением — это Scikit-learn.
Scikit-learn — это библиотека машинного обучения для Python, которая предоставляет широкий спектр инструментов для исследования, обработки и построения моделей на основе данных. Она была разработана для обеспечения простоты использования и эффективности работы.
Одной из ключевых особенностей Scikit-learn является широкий выбор алгоритмических моделей машинного обучения, доступных через модуль «модели». Этот модуль предлагает обучение с учителем и без учителя модели, такие как линейная регрессия, логистическая регрессия, случайные леса, метод опорных векторов и многие другие.
Для работы с данными Scikit-learn предоставляет модуль «обработка данных», который содержит функционал для предварительной обработки данных, такой как масштабирование, кодирование категориальных признаков и заполнение пропущенных значений.
В реализации моделей машинного обучения Scikit-learn использует модуль «машинное обучение», который содержит алгоритмы для обучения моделей на основе данных, такие как алгоритмы K-средних, случайный лес, градиентный бустинг и другие.
Для удобного анализа данных Scikit-learn предоставляет функции для разделения данных на обучающую и тестовую выборки, вычисления метрик качества моделей, оценки важности признаков и многое другое.
В целом, Scikit-learn — это мощная и гибкая библиотека для машинного обучения и анализа данных на языке Python. Ее преимущества включают широкий выбор моделей, удобный интерфейс для работы с данными и эффективные алгоритмы. Это делает Scikit-learn идеальным инструментом для исследования и анализа данных.
Предобработка данных с использованием Scikit-learn
Предобработка данных – это важная часть машинного обучения, которая включает в себя обработку и подготовку данных перед использованием их в моделях. Scikit-learn – это одна из популярных библиотек для машинного обучения на языке Python, которая предоставляет широкий набор инструментов для работы с данными.
Исследование и анализ данных часто начинается с использования модуля scikit-learn. Этот модуль предоставляет удобные функции и классы для чтения исходных данных, их предобработки и визуализации.
Одним из ключевых алгоритмических модулей в библиотеке scikit-learn является модуль preprocessing. С его помощью можно выполнять различные операции по предобработке данных:
- Подготовка данных: удаление дубликатов, выбросов и пропущенных значений.
- Масштабирование данных: приведение численных признаков к одному масштабу.
- Кодирование категориальных признаков: преобразование категориальных данных в числовые для использования моделями.
- Разбиение данных на обучающую и тестовую выборки: необходимо для оценки и проверки моделей на новых наборах данных.
Кроме модуля preprocessing, библиотека scikit-learn также предоставляет другие полезные инструменты для предобработки данных. Например, модуль feature_extraction позволяет извлекать признаки из текстовых данных, а модуль impute содержит методы для заполнения пропущенных значений.
Предобработка данных является неотъемлемой частью процесса машинного обучения. Неправильная обработка данных может привести к низкому качеству модели или некорректным результатам. Поэтому, изучение и использование модулей предобработки данных в библиотеке scikit-learn является важным навыком для успешной работы с моделями машинного обучения.
Разведочный анализ данных с помощью Scikit-learn

Scikit-learn — это библиотека машинного обучения для Python, которая предоставляет широкий набор инструментов и модулей для анализа данных. Она позволяет исследователям и аналитикам использовать различные алгоритмические модели для обучения и анализа данных.
С помощью модуля Scikit-learn можно проводить исследование, анализ и обучение моделей на основе данных. Библиотека предоставляет полезные инструменты для работы с различными типами данных, включая таблицы, тексты, изображения и другие.
Одним из ключевых преимуществ использования Scikit-learn является его простота в использовании. Библиотека предоставляет простой и понятный интерфейс для обучения моделей и работы с данными. Несмотря на свою простоту, Scikit-learn предлагает мощные возможности для выполнения сложных операций анализа данных.
Scikit-learn предоставляет широкий набор моделей для машинного обучения, таких как классификация, регрессия, кластеризация и др. Эти модели основаны на различных алгоритмах и методах машинного обучения. Разведочный анализ данных с помощью Scikit-learn позволяет исследовать структуру данных, выявлять скрытые закономерности и определять наиболее важные признаки.
Для выполнения разведочного анализа данных с использованием Scikit-learn, необходимо выполнить следующие шаги:
- Загрузить данные в структуру Scikit-learn
- Изучить структуру данных с помощью методов и операций Scikit-learn
- Построить графики и визуализации для визуального анализа данных
- Анализировать и интерпретировать результаты анализа данных
Scikit-learn предоставляет мощные инструменты для выполнения каждого из этих шагов. Например, с помощью модуля Scikit-learn можно легко загрузить данные из различных форматов файлов, таких как CSV, JSON, XML, и других.
После загрузки данных в структуру Scikit-learn, можно использовать различные методы и операции для анализа данных. Например, можно вычислить статистические характеристики, такие как среднее значение, стандартное отклонение и корреляция между признаками.
Кроме того, Scikit-learn предоставляет возможности для визуализации данных. Можно построить графики и диаграммы для визуального анализа данных, например, гистограммы, диаграммы рассеяния и box-plot. Это позволяет исследовать распределение данных, выявлять аномалии и визуально сравнивать различные признаки.
Разведочный анализ данных с помощью Scikit-learn — это важная часть процесса машинного обучения. Он помогает исследователям и аналитикам понять структуру данных, выявить важные признаки и принять информированные решения на основе анализа данных.
Прогнозирование и классификация с помощью Scikit-learn
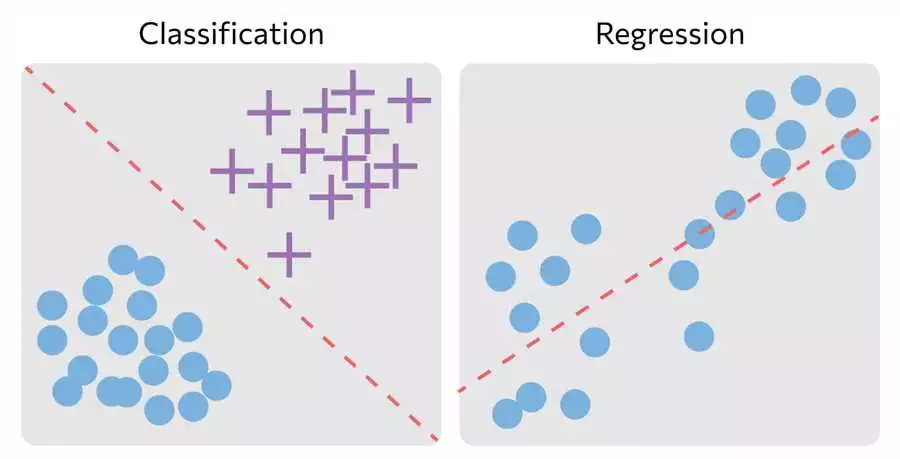
Scikit-learn — это библиотека для машинного обучения в Python, которая предоставляет широкий набор инструментов для обработки и анализа данных, а также для создания, обучения и оценки моделей машинного обучения.
Одним из главных алгоритмических модулей в scikit-learn является модуль для прогнозирования и классификации. Он предоставляет широкий выбор алгоритмов, которые можно использовать для создания моделей, способных предсказывать значения и классифицировать данные.
Библиотека scikit-learn предоставляет различные модели машинного обучения, такие как линейная регрессия, логистическая регрессия, случайный лес, метод k-ближайших соседей и многие другие. Вы можете выбрать и настроить модели в зависимости от ваших потребностей и типа данных, с которыми вы работаете.
Для использования scikit-learn вам необходимо изучить модуль, а также основные методы и функции, которые он предлагает. Это позволит вам более эффективно работать с данными и моделями машинного обучения и проводить исследование и анализ данных.
Одной из важных возможностей scikit-learn является его способность обрабатывать различные типы данных. Это позволяет вам работать с таблицами данных, изображениями, текстами и другими форматами данных. Вы можете использовать различные методы и алгоритмы для обучения моделей на этих данных и проведения прогнозов или классификации.
Еще одним преимуществом библиотеки scikit-learn является ее простота использования. Вы можете быстро начать использовать библиотеку, даже если у вас нет опыта работы с машинным обучением. Scikit-learn предлагает простой и интуитивно понятный интерфейс, который позволяет вам создавать модели и работать с данными без необходимости писать сложный код.
Вывод: scikit-learn — это мощная библиотека для машинного обучения на языке python, которая предлагает широкий набор инструментов для анализа и обработки данных, создания и обучения моделей машинного обучения. Использование scikit-learn позволяет проводить исследование и анализ данных, а также строить и оценивать модели для прогнозирования и классификации данных.