Python — это мощный и популярный язык программирования, который может быть использован для различных задач, включая обработку, анализ и визуализацию данных. Scikit-learn — это библиотека машинного обучения, написанная на языке программирования Python, и предоставляет множество инструментов для категоризации, классификации, прогнозирования и группировки данных.

Индивидуальный график
Индивидуальный график
Индивидуальный график
Используя Python и Scikit-learn, вы можете применять разнообразные методы классификации и прогнозирования на своих данных. Классификация — это процесс разделения данных на категории или группы на основе определенных свойств или характеристик. Прогнозирование — это процесс предсказания значений или результатов на основе имеющихся данных и моделей, построенных на основе этих данных.
В этом руководстве для начинающих мы покажем вам, как использовать Python и Scikit-learn для классификации и прогнозирования данных. Вы узнаете, как разделить данные на тренировочный и тестовый наборы, как создать и обучить модель машинного обучения, и как использовать эту модель для классификации или предсказания значений.
Не важно, являетесь ли вы профессионалом в области анализа данных или новичком, вам будет полезно ознакомиться с использованием Python и Scikit-learn для классификации и прогнозирования данных, так как эти инструменты могут быть применены к самым разным типам данных и задачам.
Python и Scikit-learn: вводное руководство
Python и библиотека Scikit-learn предоставляют мощные инструменты для работы с данными, прогнозирования и классификации. С их помощью можно эффективно обрабатывать различные типы информации и получать полезные результаты.
Для начала, вам потребуется установить Python и Scikit-learn на своем компьютере. После этого вы можете приступить к применению этих инструментов для классификации и прогнозирования данных.
Процесс классификации данных включает в себя разделение информации на категории. Для этого можно использовать алгоритмы машинного обучения, предоставляемые Scikit-learn. Python обеспечивает удобный и гибкий способ применения этих алгоритмов.
Scikit-learn предоставляет широкий выбор алгоритмов классификации, например, метод ближайших соседей (KNN), наивный байесовский классификатор (Naive Bayes), решающие деревья и другие. Вы можете выбрать подходящий алгоритм в зависимости от ваших данных и требований.
Чтобы применять алгоритмы Scikit-learn, вам необходимо иметь данные, которые можно использовать для обучения и тестирования модели. Множество данных обычно разделяется на тренировочное и тестовое подмножества. Тренировочное подмножество используется для обучения модели, а тестовое — для проверки ее точности.
После того, как вы разделили данные, вы можете приступить к категоризации. Scikit-learn предоставляет инструменты для преобразования данных в числовые значения, которые алгоритмы обработки могут использовать. Например, вы можете преобразовать категориальные значения в числа с помощью метода кодирования меток.
Для применения алгоритмов классификации с помощью Python и Scikit-learn вам нужно будет использовать удобный интерфейс библиотеки, чтобы загрузить данные, выбрать алгоритм и проверить результаты. Модель классификации может быть обучена и применена для предсказания новых данных.
В заключение, Python и Scikit-learn предлагают мощные инструменты для классификации и прогнозирования данных. Используя их, вы можете обрабатывать информацию, разделять ее на категории и получать полезные результаты. Применение этих инструментов может быть осуществлено через разделение данных, категоризацию и использование алгоритмов классификации.
Python: язык программирования для анализа данных

Python — это один из наиболее популярных и гибких языков программирования, которые широко применяются для анализа данных. Он предлагает богатый инструментарий для классификации, применения предсказаний, категоризации и группировки данных.
Python является очень популярным выбором для работы с данными, потому что он обладает простым и понятным синтаксисом, а также предлагает множество инструментов и библиотек для анализа данных. Одна из наиболее популярных библиотек Python для анализа данных называется Scikit-learn.
Scikit-learn — это библиотека машинного обучения, написанная на Python, которая предлагает широкий спектр алгоритмов для классификации, прогнозирования и группировки данных. Она служит отличным инструментом для анализа данных и создания моделей машинного обучения.
Используя Python и Scikit-learn, вы можете применять различные алгоритмы классификации и прогнозирования для обработки и анализа информации. Например, вы можете использовать алгоритмы обучения с учителем, такие как логистическая регрессия или алгоритмы деревьев решений для классификации данных по категориям или прогнозирования значений.
Еще одной полезной возможностью Python является возможность группировки данных. Вы можете группировать данные по различным признакам, например, по категориям или временным промежуткам. Это позволяет получить более полное представление о данных и выявить интересные закономерности.
В целом, Python является мощным языком программирования для анализа данных. Его гибкость и богатый инструментарий, вместе с библиотекой Scikit-learn, делают его отличным выбором для работы с различными задачами классификации, прогнозирования и группировки данных.
Scikit-learn: библиотека машинного обучения

Scikit-learn — это популярная библиотека машинного обучения, которая предоставляет широкий спектр инструментов для категоризации, группировки и предсказания данных. Благодаря своей простоте использования и мощным возможностям, scikit-learn стал популярным инструментом для анализа данных и прогнозирования.
Scikit-learn позволяет использовать Python для обработки и анализа данных, а также для построения и применения моделей машинного обучения. Это отличный выбор для тех, кто хочет применять современные методы машинного обучения без необходимости писать сложный код.
Одна из ключевых возможностей scikit-learn — разделение данных на обучающую и тестовую выборки для обучения и проверки модели. Это позволяет оценить качество модели и предсказать ее производительность на новых данных. Scikit-learn также предоставляет множество методов для обработки данных, включая масштабирование, нормализацию и препроцессинг.
Для применения scikit-learn необходимо импортировать соответствующие модули и классы, такие как train_test_split для разделения данных, classification для классификации или regression для прогнозирования. После этого можно создать экземпляр модели и применить ее к данным для обучения и предсказания.
Scikit-learn предоставляет множество встроенных алгоритмов и моделей, таких как линейная регрессия, логистическая регрессия, случайные леса и многое другое. Благодаря этим возможностям можно успешно решать разнообразные задачи, включая прогнозирование цен на недвижимость, классификацию электронных писем и анализ текстовых данных.
Использование scikit-learn позволяет эффективно применять методы машинного обучения для анализа данных и предсказания. Благодаря простоте использования и обширным возможностям библиотеки, Python и scikit-learn являются популярным выбором для начинающих и опытных специалистов в области data science и машинного обучения.
Основы классификации данных с помощью Python и Scikit-learn

Классификация данных является важной задачей в области машинного обучения. Она позволяет категоризировать или разделить данные на группы с целью предсказания их принадлежности к определенным классам или категориям. Для выполнения таких задач можно использовать Python и библиотеку Scikit-learn.
Python — это популярный язык программирования, который обладает мощными возможностями в области анализа данных и машинного обучения. Он широко применяется для обработки информации и разработки алгоритмов в различных областях, включая классификацию данных.
Библиотека Scikit-learn предлагает широкий набор инструментов и алгоритмов, которые могут быть применены для классификации и предсказания данных. Она предоставляет гибкую и простую в использовании платформу для обучения моделей и обработки данных.
Основной этап классификации данных заключается в подготовке данных для обучения модели. Это включает в себя предварительную обработку и очистку данных, а также выбор подходящих алгоритмов и моделей для обучения.
После подготовки данных можно приступить к обучению модели. Для этого используются различные алгоритмы, такие как логистическая регрессия, метод ближайших соседей, наивный байесовский классификатор и другие. Scikit-learn предоставляет реализацию этих алгоритмов, которые можно легко применить с помощью Python.
После обучения модели можно использовать ее для группировки и классификации новых данных. Это позволяет делать прогнозирование, основанное на полученных знаниях и обученной модели. Например, на основе обученной модели можно предсказать категорию товара или спрогнозировать вероятность события.
Итак, в основе классификации данных с помощью Python и Scikit-learn лежит категоризация и разделение данных с целью предсказания. Процесс включает подготовку данных, выбор и обучение модели, а также применение модели для прогнозирования. Использование этих инструментов позволяет обрабатывать и анализировать информацию с высокой эффективностью и точностью.
Подготовка данных для классификации

Прежде чем применять алгоритмы классификации с использованием Python и библиотеки scikit-learn, необходимо провести несколько шагов по подготовке данных.
1. Сбор данных: Соберите нужную информацию, которая потребуется для классификации. Это может быть набор структурированных данных, таких как таблицы, или текстовая информация.
2. Разделение данных: Разделите собранные данные на две части: обучающую выборку и тестовую выборку. Обучающая выборка будет использоваться для обучения модели, а тестовая выборка — для проверки и оценки ее качества.
3. Категоризация данных: Если данные содержат переменные с категориальными значениями (например, «красный», «желтый», «синий»), то необходимо преобразовать их в числовой формат. Для этого можно использовать методы кодирования, такие как «one-hot encoding» или «label encoding».
4. Группировка данных: Иногда данные могут быть сгруппированы по каким-то общим признакам. Например, при анализе покупательского поведения можно сгруппировать покупателей по географическому расположению или по типу товара, который они покупают. Группировка данных может помочь выделить закономерности и понять, какие признаки влияют на классификацию.
5. Предобработка данных: Иногда данные могут содержать пропущенные значения или выбросы. В таком случае необходимо произвести предобработку данных, чтобы убрать выбросы или заполнить пропущенные значения. Это может быть сделано с помощью различных методов, таких как удаление строк или столбцов с пропущенными значениями, заполнение пропущенных значений средним или медианным значением и т.д.
После проведения этих этапов, данные будут готовы для использования в алгоритмах классификации. С использованием Python и библиотеки scikit-learn можно применять различные алгоритмы классификации, такие как наивный байесовский классификатор, метод опорных векторов или случайный лес.
Обзор и очистка данных

Для успешного применения алгоритмов машинного обучения в задачах предсказания и прогнозирования данных необходимо сперва провести обзор и очистку данных. Библиотека scikit-learn предоставляет мощные инструменты для этих целей.
Основные шаги в процессе обзора и очистки данных включают:
- Изучение информации о данных
- Разделение данных на группы
- Классификация и категоризация данных
Изучение информации о данных позволяет понять структуру и особенности набора данных. Необходимо ознакомиться с описанием каждого атрибута и его типом данных. Это поможет понять, с какими проблемами столкнуться при обработке данных.
После изучения информации о данных можно перейти к разделению данных на группы. Группировка данных позволяет выделить подмножество данных с определенными характеристиками для дальнейшего анализа и обработки.
Классификация и категоризация данных являются важными этапами обработки данных. Они позволяют выделить основные категории и классы данных для дальнейшего применения алгоритмов машинного обучения. Python вместе с библиотекой scikit-learn предоставляет удобные инструменты для классификации и категоризации данных.
Масштабирование данных
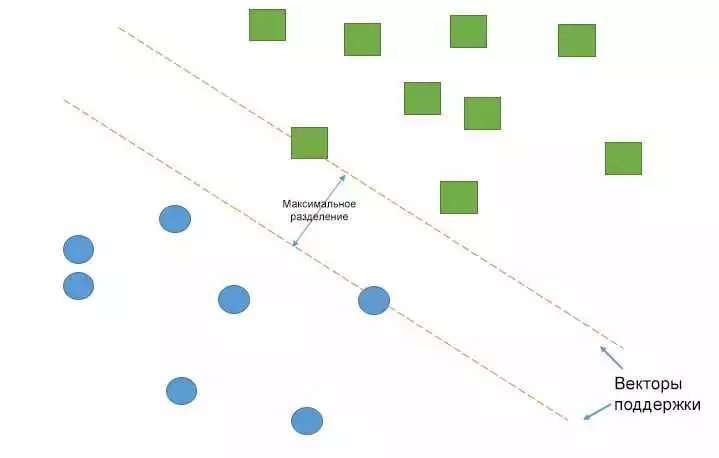
Масштабирование данных является важным шагом в применении алгоритмов классификации и прогнозирования данных. Категоризация, группировка и разделение данных являются важными этапами для предсказания и классификации информации. Одним из инструментов, позволяющих применять эти методы, является библиотека scikit-learn.
Scikit-learn предоставляет возможность применять различные методы масштабирования данных. Например, метод MinMaxScaler масштабирует данные с использованием минимума и максимума значений. Этот метод приводит значения к диапазону от 0 до 1, сохраняя отношения между значениями.
Другим методом масштабирования является StandardScaler. Он масштабирует данные путем вычитания среднего значения и деления на стандартное отклонение. Этот метод обеспечивает нулевое среднее значение и единичное стандартное отклонение для каждого признака.
Также стоит упомянуть метод RobustScaler, который масштабирует данные с использованием медианы и интерквартильного размаха. Этот метод позволяет работать с выбросами, сохраняя структуру данных.
Масштабирование данных является важным шагом для обеспечения корректной работы алгоритмов классификации и прогнозирования данных. Использование методов масштабирования в библиотеке scikit-learn позволяет улучшить качество предсказаний и классификаций.
Ниже приведена таблица с примерами методов масштабирования данных в библиотеке scikit-learn:
| Метод масштабирования | Описание |
|---|---|
| MinMaxScaler | Масштабирование данных от 0 до 1 |
| StandardScaler | Масштабирование данных с нулевым средним и единичным стандартным отклонением |
| RobustScaler | Масштабирование данных с использованием медианы и интерквартильного размаха |
Применение этих методов масштабирования данных вместе с алгоритмами классификации и прогнозирования позволяет улучшить точность предсказаний и классификаций.
Выбор и обучение модели классификации
При решении задачи классификации данных с помощью Python и scikit-learn, выбор и обучение модели являются важными этапами.
Scikit-learn — это библиотека машинного обучения, которая охватывает широкий спектр алгоритмов для классификации и прогнозирования данных. Она предоставляет удобные инструменты для работы с данными, разделение выборки на тренировочную и тестовую части, обучение модели и оценку ее качества.
Перед применением scikit-learn для классификации данных, необходимо выполнить следующие шаги:
- Импортирование модулей: подключение необходимых модулей из scikit-learn и Python для работы с данными, моделями и метриками качества.
- Загрузка данных: получение данных, которые будут использоваться для обучения модели. Данные могут быть представлены в виде таблицы с признаками и метками классов.
- Предобработка данных: обработка данных для удаления выбросов, заполнения пропущенных значений, нормализации или стандартизации признаков.
- Разделение данных: разделение данных на тренировочную и тестовую выборки. Тренировочная выборка используется для обучения модели, а тестовая выборка — для оценки ее качества.
- Выбор и обучение модели: выбор подходящей модели классификации и ее обучение на тренировочных данных.
- Оценка качества модели: оценка качества обученной модели с помощью метрик, таких как точность, полнота, F-мера и матрица ошибок.
После обучения модели на тренировочных данных, она может быть применена к новым наблюдениям для предсказания их классов или категорий. Это позволяет использовать обученную модель для прогнозирования и классификации новых данных, основываясь на полученной информации.
Использование Python и scikit-learn для классификации данных позволяет проводить различные задачи, такие как прогнозирование клиентских предпочтений, обнаружение мошенничества, категоризация товаров и многое другое.
Таким образом, правильный выбор и удачное обучение модели классификации с использованием scikit-learn и Python позволяют эффективно решать задачи прогнозирования и категоризации данных.
Подбор подходящей модели

Одним из ключевых шагов в анализе данных является выбор подходящей модели для классификации и прогнозирования. В этом процессе библиотека scikit-learn, разработанная на языке python, может быть очень полезной.
С помощью scikit-learn можно использовать различные алгоритмы для группировки, классификации и прогнозирования данных. Важно правильно выбрать модель, которая лучше всего соответствует вашим потребностям и доступной информации.
При выборе модели важно учитывать тип данных, который вы хотите классифицировать или прогнозировать. Если у вас есть данные с определенными категориями или метками, то подходящие модели для этого могут быть основаны на методах категоризации и классификации.
Когда у вас есть данные без явных категорий или меток, важно выбирать модели, которые могут предсказывать будущие значения или прогнозировать тренды. Для этого можно использовать модели, основанные на методах прогнозирования.
Библиотека scikit-learn предоставляет широкий набор инструментов для классификации, категоризации и прогнозирования. Она предлагает несколько алгоритмов, таких как логистическая регрессия, метод опорных векторов, случайный лес и другие. Каждый алгоритм имеет свои уникальные особенности и преимущества, поэтому важно экспериментировать с разными моделями и выбрать наиболее подходящую для ваших данных и целей.
При выборе модели необходимо также учитывать размер и структуру ваших данных. Некоторые модели могут быть более эффективными для больших наборов данных, в то время как другие модели могут быть лучше подходить для данных с определенной структурой.
Когда вы начинаете применять scikit-learn для классификации и прогнозирования данных, важно иметь четкое представление о типах моделей, доступных в библиотеке, и их применении для различных типов данных. Также рекомендуется изучить документацию scikit-learn и примеры кода, чтобы лучше понять, как использовать модели для ваших конкретных задач.
В итоге, выбор подходящей модели для классификации и прогнозирования данных с использованием scikit-learn является искусством и наукоём. Необходимо учитывать множество факторов, таких как тип данных, доступная информация, цели и ограничения проекта, чтобы выбрать наиболее эффективную модель для достижения желаемых результатов.
Обучение модели и оценка ее качества
Прогнозирование и классификация данных — это важные задачи в науке о данных. В Python существует множество библиотек для работы с данными, и одной из самых популярных является scikit-learn. Эта библиотека предоставляет множество инструментов для обработки и анализа данных, включая различные алгоритмы машинного обучения.
Для применения scikit-learn нужно импортировать соответствующий модуль и загрузить данные, с которыми вы хотите работать. Эти данные могут быть структурированными или неструктурированными, но должны быть в формате, понятном scikit-learn.
После загрузки данных можно приступать к разделению и обработке. Разделение включает разделение данных на обучающую и тестовую выборку. Обучающая выборка используется для обучения модели, а тестовая выборка для оценки ее качества.
После обучения модели на обучающей выборке можно применять ее для предсказания значений на новых данных. Это позволяет использовать модель для группировки объектов или классификации новых данных.
Оценка качества модели включает использование различных метрик, таких как точность, полнота, F-мера и других. Эти метрики позволяют оценить, насколько хорошо модель справляется с задачей предсказания.
На практике применять scikit-learn для обучения моделей и оценки их качества довольно просто. Библиотека предоставляет удобные методы и функции для работы с данными, а также документацию и примеры кода, которые помогут вам обучить модель и оценить ее качество.
Прогнозирование данных с помощью Python и Scikit-learn

Прогнозирование и классификация данных — важные задачи в области анализа данных. Python и библиотека Scikit-learn позволяют легко решать эти задачи с использованием мощных алгоритмов и инструментов.
Данные — это ценная информация, которую можно использовать для предсказания будущих событий или деятельности. Однако, данные могут быть сложно интерпретировать и анализировать, особенно когда они неструктурированы или имеют множество переменных.
Категоризация и классификация данных позволяет разделить и группировать информацию на основе заданных параметров или характеристик. Это помогает сделать выводы и прогнозировать будущие события или поведение.
Python является одним из самых популярных языков программирования для анализа данных. Он предоставляет широкий спектр инструментов и библиотек для работы с данными, включая Scikit-learn.
Scikit-learn — это библиотека машинного обучения для Python. Она содержит множество алгоритмов и инструментов для классификации, регрессии, кластеризации и других задач анализа данных.
Основной принцип работы Scikit-learn — обучение модели на основе уже существующих данных и использование этой модели для предсказания или классификации новых данных. Это позволяет прогнозировать будущие события и сделать выводы на основе известных исторических данных.
Процесс прогнозирования данных с помощью Python и Scikit-learn включает несколько шагов:
- Подготовка и предобработка данных. Этот шаг включает очистку данных, заполнение пропущенных значений, масштабирование и кодирование категориальных переменных.
- Выбор и настройка модели. В этом шаге выбирается алгоритм машинного обучения, настраиваются параметры модели и проводится обучение.
- Оценка модели. После обучения модели необходимо оценить ее качество, используя различные метрики и методы, такие как кросс-валидация.
- Прогнозирование новых данных. После оценки модели можно использовать ее для прогнозирования и классификации новых данных.
Прогнозирование данных с использованием Python и Scikit-learn является мощным инструментом для предсказания будущих событий или деятельности. Применение правильных методов и алгоритмов позволит получить точные результаты и сделать достоверные выводы.