Анализ текста является одной из ключевых технологий в области обработки естественного языка (Natural Language Processing, NLP). Его использование позволяет осуществлять распознавание и анализ текстовых данных с помощью компьютерного исполнения. Одной из популярных библиотек для анализа текста на языке Python является TensorFlow, которая включает в себя мощные инструменты для обработки и классификации текстов.

Индивидуальный график
Индивидуальный график
Индивидуальный график
С помощью TensorFlow можно с легкостью осуществлять анализ текста на различных уровнях. Начиная с обработки и предобработки текста, построения нейросетевых моделей для классификации текста, до выполнения анализа текстового контекста с использованием аппаратных средств. TensorFlow предлагает широкие возможности для анализа текста, что делает его основной инструментой при работе с текстовыми данными в Python.
Применение TensorFlow для анализа текста позволяет автоматизировать и ускорить процесс обработки и классификации текстовых данных. Благодаря нейронным сетям и возможностям TensorFlow, можно достичь высокой точности при классификации текста, а также оптимизировать процесс обучения моделей на больших объемах данных.
Анализ текста на Python: обработка и классификация текстовых данных с применением TensorFlow
Анализ текста является важной задачей для компьютерного обработки естественного языка (NLP). Он позволяет осуществлять обработку и классификацию текстовых данных с использованием нейросетевых технологий. С помощью аппаратными возможностей и программного обеспечения Python и TensorFlow можно легко выполнить анализ текста и использовать его для построения различных приложений и систем.
Анализ текста включает в себя обработку и классификацию текстовых данных. Обработка текста включает в себя различные этапы, такие как токенизация, лемматизация, удаление стоп-слов и т. д. Эти этапы помогают преобразовать текстовые данные в формат, который может быть обработан нейросетями.
Для выполнения анализа текста на Python можно использовать библиотеку TensorFlow. TensorFlow является мощным инструментом для построения и обучения нейронных сетей для обработки и классификации текстовых данных. Он предоставляет широкий набор инструментов для работы с текстовыми данными и возможность использования различных моделей нейросетей.
Осуществление классификации текстовых данных с использованием TensorFlow позволяет решать различные задачи, такие как определение тональности текста, категоризация текстов по темам, распознавание языка и многое другое. TensorFlow предоставляет гибкую и эффективную платформу для обучения и использования моделей нейросетей для классификации текстовых данных.
Для выполнения анализа текста на Python с использованием TensorFlow требуется установка TensorFlow и его зависимостей, а также некоторые базовые знания в области машинного обучения и нейронных сетей. Существуют также различные обучающие материалы и руководства, которые могут помочь в освоении этих технологий.
В результате использования анализа текста на Python с помощью TensorFlow можно получить ряд практических преимуществ, таких как автоматическая обработка и классификация больших объемов текстовых данных, увеличение эффективности работы с текстом, повышение качества и точности классификации текстовых данных.
Таким образом, анализ текста на Python с применением TensorFlow является важной и полезной технологией для обработки и классификации текстовых данных. Его использование позволяет осуществлять автоматическую обработку и классификацию текстовых данных с помощью нейросетевых технологий, что дает возможность построения различных приложений и систем, использующих текстовый анализ.
Обработка текстовых данных на Python
В современном мире большое количество информации представлено в текстовом формате. Для анализа, классификации и обработки текстовых данных широко применяются средства и технологии NLP (Natural Language Processing) – обработка текста естественного языка с использованием компьютерных методов.
Python – это мощный инструмент для выполнения анализа текста и работы с данными в текстовом формате. Благодаря большому количеству библиотек и фреймворков в Python, обработка текстовых данных становится более простой и эффективной.
Основные задачи обработки текстовых данных включают в себя распознавание и анализ текста, классификацию данных, а также построение и использование нейросетевых моделей для обработки текстов. Для выполнения этих задач на Python можно использовать библиотеки TensorFlow, NLTK, spaCy и другие.
Анализ текста – это обработка текстовых данных с целью извлечения полезной информации и установления связей между элементами текста. Используя различные методы анализа, можно выделить ключевые слова, определить частоту их встречаемости, выполнить категоризацию текста и многое другое.
Классификация текстовых данных – это процесс определения категории или метки, к которой относится текст. Например, можно классифицировать тексты на положительные и отрицательные отзывы, на новостные статьи по определенным темам и т. д. Классификация текстовых данных часто используется в задачах машинного обучения и анализе данных.
Используя Python, можно проводить обработку текстовых данных с использованием различных методов и техник. Например, можно проводить стемминг (отсечение окончаний слов) или лемматизацию (приведение слов к их начальной форме). Также можно проводить удаление стоп-слов (часто встречающихся, но не несущих смысловой нагрузки слов) или извлекать имя собственные из текста.
Вместе с тем, Python позволяет использовать аппаратные средства для обработки текстовых данных. С помощью DSP (Digital Signal Processing) и других аналогичных техник можно осуществлять обработку и анализ текста с использованием аппаратных средств, что позволяет повысить скорость выполнения анализа и обработки текстовых данных.
Таким образом, Python является мощным инструментом для обработки текстовых данных. С его помощью можно проводить анализ, обработку и классификацию текста, а также использовать нейросетевые модели для выполнения сложных задач обработки текстов. Благодаря богатым возможностям и большому количеству библиотек, Python становится основным языком для работы с текстовыми данными на современном этапе.
Основные методы обработки текстов
Текстовая обработка является важным этапом анализа текстовых данных с применением TensorFlow. С помощью основных методов обработки текста можно добиться лучшего понимания текстовой информации и эффективно использовать ее для выполнения различных задач, таких как классификация, анализ эмоциональной окраски текста и распознавание сущностей.
Для обработки текста с применением нейросетевых технологий TensorFlow предоставляет набор инструментов и библиотек, которые позволяют выполнять синтаксический анализ текста, его векторизацию и классификацию.
Основные методы обработки текста включают:
- Токенизация – разбиение текста на отдельные слова или токены. Токенизация является первым шагом в анализе текстовых данных.
- Удаление стоп-слов – избавление от часто встречающихся слов, которые не несут смысловой нагрузки.
- Стемминг – приведение слов к их основной форме (стему).
- Лемматизация – приведение слов к их словарной форме (лемме).
- Извлечение признаков – преобразование текста в числовое представление (векторизацию), чтобы его можно было использовать для обучения модели.
- Использование словарей – создание словаря из уникальных слов и их индексации.
- Анализ синтаксиса – извлечение информации о частях речи, грамматической структуре и зависимостях в тексте.
Обработка текста может быть осуществлена с использованием стандартных средств языка Python или с помощью специализированных библиотек, таких как Natural Language Toolkit (NLTK), Spacy, Gensim и других.
TensorFlow позволяет использовать эти инструменты для обработки текста при выполнении классификации, анализа эмоциональной окраски текста, а также при распознавании именованных сущностей.
Одним из важных аспектов обработки текста является использование специализированных аппаратных ускорителей, таких как DSP (Digital Signal Processing), для ускорения выполнения операций с текстовыми данными.
Таким образом, основные методы обработки текста в TensorFlow включают токенизацию, удаление стоп-слов, стемминг, лемматизацию, извлечение признаков, использование словарей и анализ синтаксиса. С помощью этих методов можно успешно обрабатывать текстовые данные и использовать их для решения различных задач обработки и классификации текста.
Преобразование текстовых данных в числовые признаки
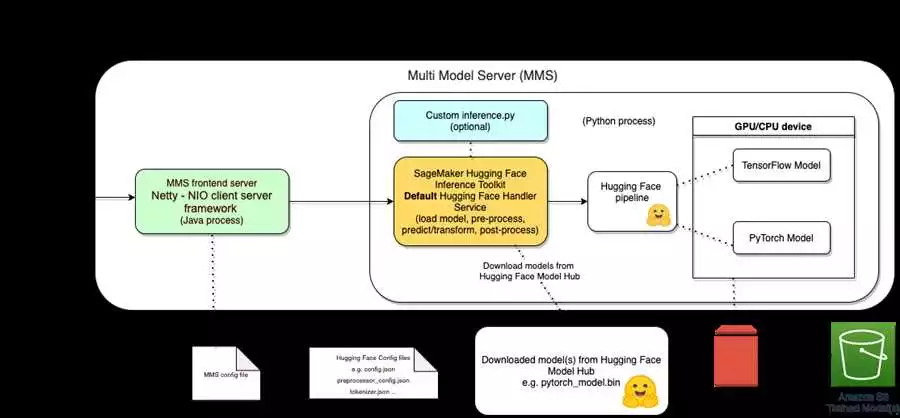
Анализ текста с использованием нейросетевых технологий и анализ данных является ключевым инструментом в области обработки естественного языка (Natural Language Processing, NLP). Применение аппаратных средств совместно с компьютерным программным обеспечением позволяет осуществлять распознавание и классификацию текстовых данных.
TensorFlow — это мощная библиотека для машинного обучения, которая может быть использована для построения нейронных сетей для анализа текста. С помощью TensorFlow можно выполнить преобразование текстового ввода в числовые признаки, которые можно использовать для классификации данных.
Основным способом преобразования текста в числовые признаки является векторизация. Векторизация текста — это процесс представления текстовых данных с использованием числовых векторов. Одним из наиболее популярных методов векторизации текста является метод «мешка слов» (Bag of Words).
Метод «мешка слов» предполагает, что признаки в тексте являются независимыми и учитывает только наличие слов в документе, без учета их порядка или контекста. Для построения вектора признаков с использованием метода «мешка слов» сначала составляется словарь всех уникальных слов, найденных в тексте. Затем каждый документ (или предложение) представляется в виде вектора, где каждый элемент соответствует количеству вхождений соответствующего слова из словаря в данном документе.
Вместо подсчета количества вхождений слов можно использовать другие методы векторизации, такие как TF-IDF (Term Frequency-Inverse Document Frequency). TF-IDF учитывает не только наличие слова в документе, но и его важность в контексте всего корпуса текстов. Он присваивает более высокий вес словам, которые часто встречаются в данном документе, но редко встречаются в других документах.
Также существуют методы представления текста в виде эмбеддингов, которые позволяют захватить семантическую информацию в тексте. Например, эмбеддинги представляют слова в виде векторов фиксированной длины, где схожие слова имеют более близкие векторы. Одним из популярных методов эмбеддинга текста является Word2Vec.
Преобразование текстовых данных в числовые признаки с использованием TensorFlow и других библиотек позволяет осуществлять классификацию данных на основе текстовых их описаний. Например, можно построить модель для классификации отзывов на положительные и отрицательные на основе их текста. Это открывает возможности использования анализа текста в различных областях, таких как маркетинг, медицина, финансы и многих других.
Извлечение признаков из текста

Извлечение признаков из текста – это процесс обработки и анализа текстовых данных с помощью нейросетевых алгоритмов. Осуществление такой обработки и анализа текста средствами компьютерного технологии позволяет выполнение таких задач, как распознавание, классификация и анализ текста.
Для извлечения признаков из текста часто используются средства обработки естественного языка (Natural Language Processing, NLP). Такие средства позволяют выполнять анализ текста на основе его значения и смысла.
Одним из самых популярных инструментов для извлечения признаков из текста является фреймворк TensorFlow, который позволяет строить и обучать нейронные сети для решения задач обработки и анализа текста. TensorFlow предлагает широкие возможности в использовании текстового анализа с применением различных модулей, а также предоставляет готовые реализации для анализа и классификации текста.
Использование аппаратных средств для выполнения анализа текста позволяет повысить производительность и эффективность обработки текстовых данных. Распознавание и классификация текста с применением аппаратных ресурсов позволяет ускорить процесс обработки информации и улучшить точность результатов.
В Python существует множество инструментов и библиотек для работы с текстовыми данными. Одним из самых популярных инструментов для анализа текста является библиотека PyTorch, которая предоставляет мощные инструменты для обработки и классификации текстовых данных.
Таким образом, извлечение признаков из текста является важным этапом в анализе текстовых данных. С использованием нейросетевых алгоритмов, аппаратных средств и с помощью специализированных инструментов, таких как TensorFlow и PyTorch, можно успешно выполнять обработку, анализ и классификацию текста.
Классификация текстовых данных на Python с использованием TensorFlow

С помощью TensorFlow, популярной библиотеки машинного обучения, можно эффективно осуществлять классификацию текстовых данных на языке Python. Эта технология оказывается полезной во многих сферах, требующих анализа и обработки текстов.
Технология TensorFlow предоставляет нейросетевые средства для построения и выполнения компьютерного анализа текста. С ее помощью можно эффективно распознавать и анализировать текстовые данные, а также осуществлять классификацию текстов при помощи нейронных сетей.
Основной задачей классификации текстовых данных является определение категории или класса, к которым может относиться входной текст. С использованием TensorFlow можно легко реализовать алгоритмы классификации, обучив нейронную сеть на большом наборе текстовых данных.
Для начала работы с классификацией текстовых данных на Python с использованием TensorFlow необходимо установить библиотеку TensorFlow и иметь некоторые базовые знания в области обработки текстов и машинного обучения. Для этого достаточно выполнить простые инструкции по установке и ознакомиться с документацией TensorFlow
После установки TensorFlow и ознакомления с его основными функциями можно приступить к реализации классификации текстовых данных с помощью нейросетевых алгоритмов. Для этого необходимо подготовить данные, состоящие из обучающих и тестовых наборов текстовых данных.
Затем следует выполнить предварительную обработку текстовых данных, включающую в себя удаление лишних символов, приведение текста к нижнему регистру, токенизацию и лемматизацию. Эти шаги помогут упростить дальнейший анализ текстовых данных.
После предварительной обработки данных можно приступить к созданию и обучению нейронной сети. TensorFlow предоставляет удобные средства для построения нейронных сетей с использованием различных архитектур, включая сверточные нейронные сети и рекуррентные нейронные сети.
После обучения нейронной сети на обучающих данных можно провести тестирование на тестовом наборе данных и оценить качество классификации. TensorFlow позволяет проводить эксперименты с различными параметрами и архитектурами нейронных сетей для достижения наилучших результатов.
Использование TensorFlow для классификации текстовых данных на Python с помощью нейронных сетей позволяет с высокой точностью определять категории или классы текстов. Эта технология находит применение в различных областях, таких как анализ социальных сетей, обработка и анализ естественного языка (NLP), распознавание речи и многое другое.
В итоге, классификация текстовых данных с использованием TensorFlow на языке Python является эффективным и мощным инструментом для обработки и анализа текстовых данных. С его помощью можно легко создавать и обучать нейронные сети для классификации текстов и получать точные и надежные результаты.
Основные принципы классификации текста
Для анализа текста с использованием средств технологии nlp (Natural Language Processing) и компьютерного анализа данных можно применять различные методы и подходы. Одним из наиболее эффективных инструментов для анализа текстовых данных с использованием Python является библиотека TensorFlow.
Основной принцип классификации текста заключается в распознавании и группировке текстов по определенным категориям или темам. Для этого используются методы машинного обучения, такие как нейросетевые алгоритмы, реализованные на основе TensorFlow.
Процесс анализа текста на Python начинается с обработки и предварительной подготовки текстовых данных. Это включает в себя удаление лишних символов, токенизацию (разделение текста на отдельные слова или токены) и лемматизацию (приведение слов в единую форму).
Для классификации текста с использованием TensorFlow можно использовать различные модели, такие как рекуррентные нейронные сети (RNN) или сверточные нейронные сети (CNN). Они позволяют построить модель, которая будет принимать на вход текст и выдавать предсказание о его классе или категории.
Осуществление анализа текстовых данных с помощью TensorFlow требует выполнения следующих шагов:
- Сбор и подготовка тренировочного набора текстовых данных.
- Разделение данных на тренировочную и тестовую выборку.
- Построение модели нейросети с помощью TensorFlow.
- Тренировка модели на тренировочной выборке.
- Проверка точности модели на тестовой выборке.
- Оценка результатов и внесение необходимых корректировок.
С использованием TensorFlow также можно выполнять анализ текста с применением аппаратных средств, например, с использованием Digital Signal Processing (DSP). Это позволяет ускорить процесс обработки и классификации текстовых данных.
Таким образом, основные принципы классификации текста заключаются в обработке и подготовке данных, построении и обучении модели нейросети с использованием TensorFlow, а также оценке результатов и корректировке модели для повышения точности классификации.
Обучение модели на текстовых данных с помощью TensorFlow
TensorFlow – это открытая платформа с открытым исходным кодом для машинного обучения и глубокого обучения. Она предоставляет удобные инструменты для разработки и обучения моделей на различных типах данных, в том числе и на текстовых данных.
Применение и использование текстового анализа с помощью TensorFlow позволяет эффективно обрабатывать и классифицировать большие объемы текста, осуществлять распознавание и анализ текста, а также строить модели и проводить исследования в области обработки естественного языка (NLP).
Для выполнения анализа и классификации текстовых данных с использованием TensorFlow необходимо иметь некоторые предварительные знания в программировании на языке Python. Python является одним из наиболее популярных языков программирования для реализации машинного обучения и нейросетевых алгоритмов.
Осуществление анализа и классификации текстовых данных средствами TensorFlow включает в себя:
- Обработку текстовых данных с использованием аппаратными средствами, такими как центральный процессор (CPU) или графический процессор (GPU).
- Построение модели для анализа текста с помощью TensorFlow.
- Обучение модели на текстовых данных.
- Проверку и оценку результатов обучения модели.
- Применение обученной модели для анализа новых текстовых данных.
Для успешного выполнения этих шагов необходимо уметь использовать различные библиотеки Python, такие как Numpy, Pandas и Scikit-learn. Эти библиотеки позволяют эффективно работать с данными, выполнить предварительную обработку текста, преобразовать текстовые данные в численные значения и т. д.
Исходя из вышеизложенного, обучение модели на текстовых данных с помощью TensorFlow представляет собой комплексный процесс, требующий тщательной подготовки данных, выбора подходящих алгоритмов и моделей, а также глубоких знаний в области машинного обучения и анализа текста.
Оценка и тестирование модели классификации текста
Для анализа и классификации текстовых данных с использованием нейросетевых моделей необходимо провести оценку и тестирование полученной модели. Это позволит оценить ее точность и эффективность в задаче классификации текста.
Построение модели классификации текста с применением TensorFlow и Python включает в себя следующие этапы:
- Подготовка и предварительная обработка данных. Для выполнения анализа текста необходимо провести обработку и очистку данных от лишних символов и слов, привести текст к одному формату. Для этого можно использовать методы предобработки текста, такие как токенизация и стемминг.
- Обучение модели. Для классификации текста с использованием TensorFlow и Python можно использовать различные алгоритмы, такие как рекуррентные нейронные сети (RNN) или сверточные нейронные сети (CNN).
- Тестирование модели. После обучения модели необходимо провести ее тестирование на новых данных. Для этого можно использовать отдельный набор тестовых данных, которые модель не видела во время обучения.
- Анализ и оценка результатов. После тестирования модели необходимо проанализировать полученные результаты и оценить ее точность и качество классификации.
При оценке модели классификации текста с использованием TensorFlow и Python можно использовать различные метрики, такие как точность (accuracy), полноту (recall), точность предсказания (precision) и F1-меру. Эти метрики позволяют оценить качество классификации модели.
Также важно учитывать аппаратные требования для выполнения анализа данных с использованием нейронных сетей. Для эффективной работы моделей классификации текста рекомендуется использовать аппаратные средства, оптимизированные для вычислений с использованием нейросетей, такие как графические процессоры (GPU) или Digital Signal Processor (DSP).
Технология обработки и классификации текстовых данных с использованием нейронных сетей и Python имеет широкие возможности применения. Она может быть использована в области натурального языка (NLP), машинного обучения, распознавания речи и других задач, связанных с анализом текста.
В конечном итоге, при применении модели классификации текста с использованием TensorFlow и Python необходимо провести оценку и тестирование модели, чтобы определить ее эффективность и качество классификации.
Выполнение NLP анализа на Python
Анализ естественного языка (Natural Language Processing, NLP) — это область компьютерного науки, связанная с обработкой и анализом естественного языка с помощью алгоритмов и моделей машинного обучения. Возможность распознавания и анализа текстового содержимого имеет важное значение в различных областях, от обработки естественного языка в аудио-, видео- и текстовых данных до построения нейросетевых моделей для классификации данных.
Python в сочетании с библиотекой TensorFlow предоставляет мощный инструментарий для осуществления NLP анализа. TensorFlow — это открытое программное обеспечение для машинного обучения и глубокого обучения, которое предоставляет широкий набор функций для работы с текстовыми данными.
Осуществление анализа текста на Python с использованием TensorFlow включает в себя обработку и классификацию текстовых данных. Средствами TensorFlow можно проводить такие задачи, как анализ тональности текста, определение ключевых слов, классификация текста по определенным категориям и многое другое.
Для выполнения NLP анализа на Python с помощью TensorFlow можно использовать следующие шаги:
- Загрузка и предварительная обработка текстовых данных.
- Подготовка данных для обучения и тестирования моделей.
- Построение нейросетевых моделей для классификации и анализа текста.
- Обучение моделей на текстовых данных.
- Оценка производительности моделей и выбор наилучшей модели.
- Использование различных технологий и методов для улучшения результатов, таких как использование аппаратных средств для ускорения обучения моделей.
В результате выполнения NLP анализа на Python с использованием TensorFlow можно получить точные и надежные результаты анализа текста, которые могут быть использованы в различных областях, включая маркетинг, социальные науки, медицину и другие.
Таким образом, выполнение NLP анализа на Python позволяет осуществить обработку и классификацию текстовых данных с помощью мощных инструментов TensorFlow, что открывает широкие возможности для анализа текста и применения результатов анализа в различных областях и задачах.
Описание Natural Language Processing (NLP)

Natural Language Processing (NLP), или обработка естественного языка, является областью исследований в области компьютерного научения, которая занимается обработкой, анализом и классификацией текстовых данных с использованием текстового анализа. NLP используется для выполнения различных задач, связанных с обработкой текста и распознаванием речи.
Основной целью NLP является осуществление компьютерного анализа и понимания естественного языка, то есть естественным образом используемых людьми в коммуникации. Это включает в себя построение моделей и алгоритмов для анализа и интерпретации текста с помощью аппаратных средств, таких как TensorFlow.
С помощью NLP можно классифицировать текстовые данные на основе их содержания, анализировать текст для выявления определенных паттернов и трендов, а также распознавать и анализировать естественный язык с целью создания автоматических систем общения с компьютерами.
NLP играет важную роль в многих сферах, включая машинный перевод, автоматическую обработку запросов пользователей, синтез речи, анализ тональности текста, классификацию и категоризацию текстовых данных.
Применение технологии NLP также имеет широкий спектр использования в практически всех отраслях, включая медицину, финансы, маркетинг и социальные науки. Это связано с тем, что NLP позволяет обрабатывать и анализировать большие объемы текстовых данных, что открывает новые возможности для извлечения ценной информации из текста.
Технология NLP базируется на использовании нейросетевых алгоритмов, которые обучаются на текстовых данных для выполнения задач анализа и классификации. Она также активно использует методы обработки сигналов и дигитальной обработки сигналов (DSP) для извлечения и анализа признаков текста.
В целом, NLP предоставляет мощные инструменты для анализа и интерпретации текста, что делает ее незаменимым инструментом в современном мире информационных технологий.
Применение NLP анализа при обработке текстовых данных
Анализ текста — это процесс преобразования неструктурированной информации в структурированную, позволяющий получить полезные знания из текстов. Одним из средств анализа текста является Natural Language Processing (NLP) — компьютерное исследование и моделирование языка, которое позволяет компьютеру понимать, интерпретировать и генерировать естественный язык.
При обработке текстовых данных с использованием NLP анализа, осуществление анализа и классификации текстовых данных происходит с помощью аппаратных и программных технологий, таких как Python, TensorFlow и DSP (Digital Signal Processing).
Python — это мощный язык программирования, широко используемый для обработки текстовых данных и реализации различных алгоритмов анализа текста. Библиотека TensorFlow позволяет строить и обучать нейросетевые модели для анализа и классификации текстового контента. Использование TensorFlow позволяет значительно ускорить выполнение анализа и классификации текстовых данных.
Основными задачами NLP анализа являются: построение моделей для распознавания частей речи, определение семантической близости текстов, извлечение ключевых слов и сущностей из текста, определение тональности текста и многое другое.
Применение NLP анализа при обработке текстовых данных позволяет автоматизировать процессы обработки больших объемов текстовой информации, что особенно важно для аналитических целей и машинного обучения.
Примеры применения NLP анализа на Python:
- Анализ тональности текста — определение положительных, отрицательных или нейтральных отзывов о продукте или услуге
- Автоматическое категоризирование текстовых данных — разделение текстов на предопределенные категории
- Автоисправление опечаток — исправление орфографических ошибок в тексте
- Генерация автопродолжений — автоматическое продолжение предложений на основе имеющегося контекста
Применение NLP анализа при обработке текстовых данных с использованием Python и TensorFlow является эффективным способом обработки и классификации больших объемов текстовой информации.
Примеры алгоритмов NLP анализа в Python

Анализ текста на Python с использованием технологий обработки естественного языка (NLP) стал неотъемлемой частью многих проектов компьютерного зрения. Различные алгоритмы NLP позволяют выполнять анализ текста, распознавание и классификацию данных с помощью нейросетевых сетей.
Процесс анализа текста в Python начинается с построения модели, которая осуществляет обработку текстового материала. С помощью библиотеки TensorFlow можно использовать мощные аппаратные возможности для выполнения NLP анализа.
Основными методами анализа текста в Python в NLP являются:
- Анализ тональности текста
- Распознавание именованных сущностей
- Извлечение ключевых слов
- Классификация текстовых данных
- Машинный перевод текста
Анализ тональности текста позволяет определить эмоциональный окрас текста (нейтральный, положительный, отрицательный). Распознавание именованных сущностей позволяет выделить имена, организации, географические названия и другие сущности в тексте.
Извлечение ключевых слов позволяет выделить наиболее важные слова или фразы в тексте. Классификация текстовых данных помогает определить принадлежность текста к определенным классам или категориям. Машинный перевод текста позволяет автоматически перевести текст с одного языка на другой.
Важно отметить, что анализ текста в Python с использованием NLP алгоритмов требует специализированных знаний и навыков. Однако благодаря библиотекам и инструментам на Python, таким как TensorFlow, выполнение анализа текста становится более доступным и удобным.
| Алгоритм | Описание |
|---|---|
| Анализ тональности текста | Определение эмоционального окраса текста (нейтральный, положительный, отрицательный) |
| Распознавание именованных сущностей | Выделение имен, организаций, географических названий и других сущностей в тексте |
| Извлечение ключевых слов | Выделение наиболее важных слов или фраз в тексте |
| Классификация текстовых данных | Определение принадлежности текста к определенным классам или категориям |
| Машинный перевод текста | Автоматический перевод текста с одного языка на другой |