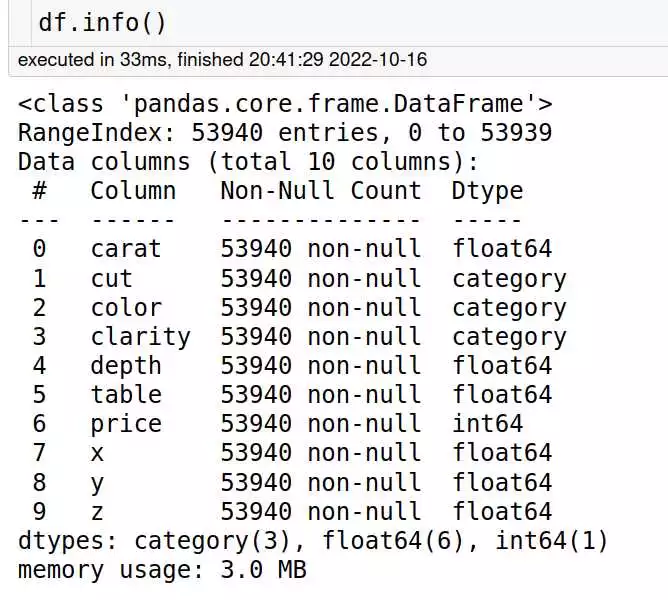
В наше время данные играют важную роль в различных сферах: от научных исследований до бизнес-аналитики. Большую часть этих данных представляют в текстовом формате, и для их обработки и анализа необходимо знание специальных инструментов. Одним из самых популярных инструментов для работы с данными в Python является библиотека Pandas.

Индивидуальный график
Индивидуальный график
Индивидуальный график
Pandas – это библиотека, разработанная для работы с данными. Она предоставляет удобные и эффективные инструменты для анализа и манипулирования структурированными данными. Pandas позволяет импортировать данные из различных источников, включая текстовые файлы, и предоставляет удобные методы для обработки и преобразования данных.
Это руководство создано для того, чтобы помочь вам освоить основы использования библиотеки Pandas для работы с данными из текстовых файлов. В нем вы найдете подробные объяснения основных концепций и функций Pandas, а также много примеров, демонстрирующих использование этих функций в практических ситуациях.
Чтение, запись, фильтрация, сортировка, группировка и агрегация – все эти операции можно легко выполнить с помощью Pandas. Благодаря широкой функциональности и простоте в использовании, Pandas позволяет эффективно работать с данными, сокращая время и усилия, затраченные на обработку и анализ.
Самый полный гайд
Библиотека Pandas является одним из основных инструментов для работы с данными в языке программирования Python. Она предоставляет удобные и эффективные средства для анализа, обработки и визуализации данных. В данном руководстве мы рассмотрим использование библиотеки Pandas для работы с данными из текстовых файлов.
Для начала работы с библиотекой Pandas необходимо установить ее при помощи менеджера пакетов Python, например, pip:
$ pip install pandas
После успешной установки библиотеки Pandas мы можем начать работу с данными из текстовых файлов. Для этого сначала необходимо импортировать библиотеку:
import pandas as pd
Затем мы можем использовать функцию read_csv() для чтения данных из текстового файла в объект типа DataFrame. Функция read_csv() позволяет указывать различные параметры, такие как разделитель полей, кодировка и другие:
df = pd.read_csv('example.csv', delimiter=',', encoding='utf-8')
После чтения файла в объект DataFrame мы можем выполнять различные операции с данными, такие как фильтрация, сортировка, агрегация и другие. Например, для вывода первых пяти строк данных можно использовать метод head():
df.head()
Для фильтрации данных можно использовать логические выражения. Например, можно выбрать только те строки, где значение в столбце «age» больше 30:
df[df['age'] > 30]
Также можно выполнять операции с определенными столбцами данных. Например, для вычисления среднего значения в столбце «salary» можно использовать метод mean():
df['salary'].mean()
Библиотека Pandas также предоставляет возможность визуализации данных. Например, для построения столбчатой диаграммы по столбцу «age» можно использовать метод plot():
df['age'].plot(kind='bar')
В данном руководстве мы рассмотрели только основные возможности библиотеки Pandas для работы с данными из текстовых файлов. Библиотека Pandas обладает множеством дополнительных функций и возможностей, которые могут быть полезными при работе с различными типами данных. Дополнительную информацию можно найти в официальной документации библиотеки Pandas.
Что такое библиотека Pandas в Python
Библиотека Pandas — это мощный инструмент, который используется для работы с данными в языке программирования Python. Она предоставляет удобные и эффективные средства для обработки, анализа и визуализации данных.
Основная идея Pandas — использование объектов для представления и манипулирования структурированными данными. Данные могут быть представлены в виде таблицы, похожей на таблицу в Excel, с различными типами данных в каждом столбце. Эти таблицы называются DataFrames.
Библиотека Pandas обладает множеством функций для работы с данными. Некоторые из них:
- Чтение данных из различных источников, таких как текстовые файлы, базы данных или веб-страницы.
- Обработка данных, включая сортировку, фильтрацию, группировку и агрегацию.
- Добавление, удаление и редактирование столбцов и строк.
- Выполнение различных математических операций над данными.
- Визуализация данных с помощью графиков и диаграмм.
Pandas также интегрируется с другими популярными библиотеками Python, такими как NumPy и Matplotlib, что позволяет более эффективно проводить анализ данных и создавать визуализации.
Библиотека Pandas имеет хорошую документацию и великолепное сообщество разработчиков, что делает ее привлекательным выбором для работы с данными в Python.
Если вы только начинаете использовать библиотеку Pandas, существует большое количество руководств, уроков и примеров, которые помогут вам освоить основы и начать использовать ее в своих проектах.
Описание библиотеки Pandas
Библиотека Pandas — одна из наиболее популярных библиотек для работы с данными в языке программирования Python. Она предоставляет широкий набор инструментов и функций для обработки и анализа данных, особенно в формате таблицы. Pandas обеспечивает простой, эффективный и интуитивно понятный способ работы с данными.
Главным объектом в библиотеке Pandas является DataFrame — двумерный массив данных, структурированный в виде таблицы. DataFrame позволяет представлять данные в удобной для анализа форме, где каждая строка таблицы соответствует отдельной записи, а столбцы — различным признакам или переменным.
Библиотека Pandas предлагает множество методов и функций для работы с DataFrame, таких как фильтрация, сортировка, группировка, агрегация и многое другое. Она также позволяет вводить и экспортировать данные из различных форматов файлов, включая CSV, Excel, SQL, JSON и другие.
Одной из ключевых особенностей Pandas является его поддержка работы с отсутствующими данными. Библиотека позволяет легко обрабатывать и заполнять пропущенные значения, а также проводить различные операции с данными, включая их агрегацию, без необходимости удаления неполных записей.
Библиотека Pandas также предоставляет возможность проводить различные операции по изменению структуры данных, такие как добавление и удаление столбцов, объединение, разделение и трансформация таблиц. Это позволяет эффективно подготавливать данные для анализа и построения моделей.
Пандас также имеет мощный инструментарий для визуализации данных, который позволяет строить графики и диаграммы для анализа и визуализации данных.
В целом, библиотека Pandas представляет собой мощный инструмент для работы с данными в языке программирования Python. Она обеспечивает удобный и эффективный способ работы с таблицами данных, предоставляет множество функций для обработки и анализа данных, а также инструменты для визуализации и подготовки данных.
Преимущества использования библиотеки Pandas
Библиотека Pandas — одна из наиболее популярных библиотек Python для анализа данных. Она предоставляет широкий спектр возможностей для работы с данными, особенно с табличными данными. В этом руководстве рассмотрим основные преимущества использования библиотеки Pandas.
- Удобство работы с данными
- Высокая производительность
- Широкий функционал
- Интеграция с другими библиотеками
- Простота изучения и использования
С помощью Pandas можно легко и быстро загружать данные из различных источников, таких как CSV-файлы, Excel-файлы, SQL-запросы и другие форматы. Библиотека позволяет проводить манипуляции с данными, выполнять фильтрацию, сортировку и агрегацию, а также выполнять операции по изменению структуры данных.
Pandas использует внутреннюю структуру данных, называемую DataFrame, которая позволяет эффективно хранить и обрабатывать большие объемы данных. Благодаря оптимизации производительности библиотеки, Pandas обладает высокой скоростью работы даже с большими наборами данных.
Pandas обладает множеством функций и методов для работы с данными. Библиотека предоставляет гибкие возможности по дополнительной обработке и очистке данных, включая заполнение пропущенных значений, удаление дубликатов, обработку строк и многое другое. Благодаря наличию различных функций, Pandas позволяет проводить сложные аналитические вычисления и статистические операции.
Pandas может работать с другими популярными библиотеками Python, такими как NumPy, Matplotlib и SciPy. Используя Pandas в сочетании с этими библиотеками, можно выполнять сложные аналитические задачи, создавать графики и визуализации, а также проводить статистические и научные вычисления.
Библиотека Pandas имеет простой и интуитивно понятный интерфейс, что делает ее доступной для начинающих пользователей. Pandas также имеет обширную документацию и активное сообщество разработчиков, которые помогают в решении возникающих вопросов и проблем.
В итоге, использование библиотеки Pandas в Python для работы с данными из текстовых файлов предоставляет ряд преимуществ, включая удобство работы с данными, высокую производительность, широкий функционал, интеграцию с другими библиотеками и простоту использования.
Роль библиотеки Pandas в анализе данных
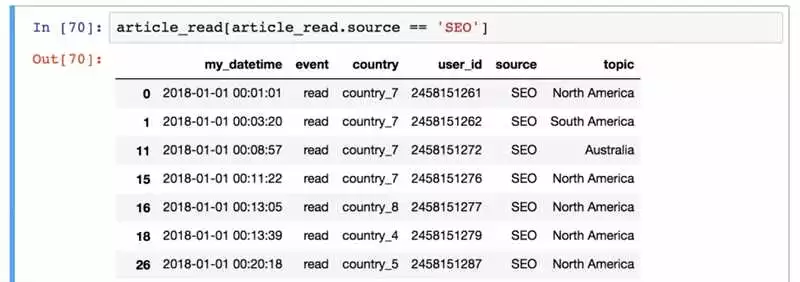
Библиотека Pandas является неотъемлемой частью инструментария для работы с данными в языке программирования Python. Основанная на другой популярной библиотеке, NumPy, Pandas предоставляет мощные и удобные инструменты для обработки, анализа и манипуляции с данными.
Одной из ключевых возможностей Pandas является работа с текстовыми файлами, такими как CSV, TXT, Excel и другими форматами файлов, содержащими структурированные данные.
Использование Pandas для работы с текстовыми данными предоставляет программистам и аналитикам удобный интерфейс для считывания и записи данных, а также возможность выполнять сложные операции по обработке и анализу информации.
Важным преимуществом библиотеки Pandas является его способность работать с большими объемами данных, что особенно полезно при анализе больших наборов информации.
Руководство по использованию Pandas для работы с текстовыми файлами предоставляет аналитикам все необходимые инструменты и методы для выполнения широкого спектра задач, таких как фильтрация, сортировка, объединение, агрегирование и визуализация данных.
Благодаря удобному и интуитивно понятному синтаксису, Pandas позволяет с легкостью выполнять различные операции по обработке данных, что делает его незаменимым инструментом в области анализа данных.
В заключение, использование библиотеки Pandas для работы с текстовыми данными позволяет упростить и ускорить процесс анализа информации, а также предоставляет отличные возможности для создания высокоэффективных программных решений.
Работа с текстовыми файлами в Pandas
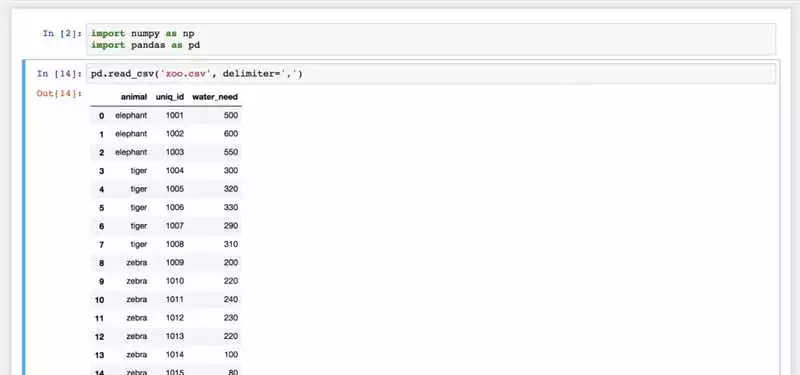
Библиотека Pandas является одной из самых популярных библиотек для работы с данными в Python. Она предоставляет удобные инструменты для анализа, обработки и визуализации данных. Одна из важных возможностей Pandas — работа с текстовыми файлами.
Текстовые файлы являются одним из наиболее распространенных форматов хранения данных. Использование Pandas позволяет легко импортировать данные из текстовых файлов, выполнять с ними различные операции и экспортировать обработанные данные обратно в текстовый формат.
Для работы с текстовыми файлами в Pandas можно использовать методы read_csv, read_table, read_fwf и другие, в зависимости от формата и структуры файла.
Примеры использования этих методов:
- read_csv — чтение данных из CSV-файла.
- read_table — чтение данных из файла с разделителями.
- read_fwf — чтение данных из файла с фиксированной шириной столбцов.
После чтения файлов в Pandas, данные могут быть преобразованы и обработаны с помощью различных методов. Например, можно проводить фильтрацию, сортировку, группировку, агрегацию и многое другое.
Примеры выполнения операций над данными:
- filter — фильтрация данных по условию.
- sort_values — сортировка данных по значениям столбцов.
- groupby — группировка данных по значениям столбцов.
- aggregate — агрегация данных с помощью различных агрегатных функций.
После обработки данных, их можно экспортировать обратно в текстовый формат с помощью метода to_csv или других. Это позволяет сохранить результат работы в удобном для дальнейшего использования формате.
Пример экспорта данных в CSV-файл:
- to_csv — экспорт данных в CSV-файл.
Использование библиотеки Pandas для работы с текстовыми файлами обеспечивает мощные инструменты для анализа и обработки данных. Она позволяет легко импортировать данные из текстовых файлов, выполнять с ними различные операции и экспортировать результаты обратно в текстовый формат. Руководство по использованию Pandas позволяет освоить основные возможности библиотеки и получить доступ к многим функциям, упрощающим работу с данными.