Python – это универсальный язык программирования, который предоставляет разнообразные возможности для создания мощных и эффективных скриптов. Одним из таких скриптов является парсер, который позволяет производить разбор и извлечение данных из HTML и XML файлов.

Индивидуальный график
Индивидуальный график
Индивидуальный график
Распарсивание (парсинг) – это техника анализа и обработки данных, которая позволяет программе извлекать информацию из исходного кода страницы или документа, разбирая и анализируя его структуру и содержимое. В Python для создания парсеров часто используются библиотеки, такие как BeautifulSoup и lxml, которые предоставляют мощные инструменты для работы с HTML и XML.
Python обладает простым и интуитивно понятным синтаксисом, что делает его идеальным языком для написания парсеров. С его помощью можно легко создавать скрипты, которые собирают и анализируют данные, выполняют разбор и обработку различных форматов файлов, включая HTML и XML. Python также предоставляет богатые возможности для работы с сетевыми протоколами, что делает его отличным выбором для написания скриптов сбора информации из Интернета.
Секреты создания мощных и эффективных скриптов для распарсинга HTML и XML в Python заключаются в правильном использовании различных техник и методов. Некоторые из них включают использование селекторов CSS для выборки конкретных элементов страницы, применение регулярных выражений для нахождения и извлечения нужных данных, использование XPath для навигации по XML-структурам и многое другое.
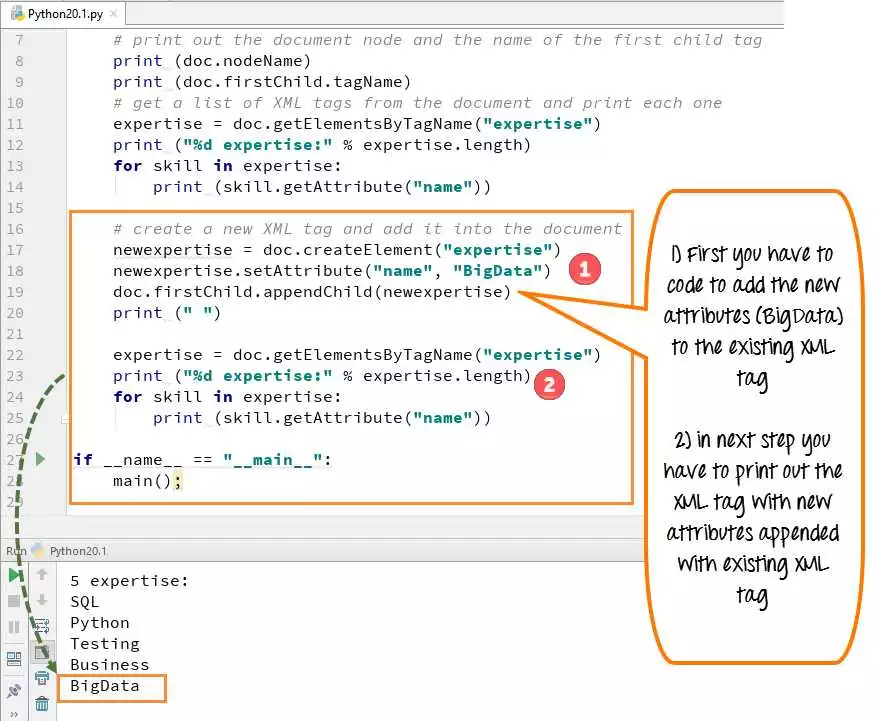
Python – это мощный язык программирования, который предлагает широкий набор инструментов для работы с данными. Если вы хотите создавать эффективные скрипты для анализа и обработки HTML и XML файлов, то Python – это лучший выбор. С его помощью вы сможете освоить тайны парсинга и создать мощные и эффективные скрипты для распарсинга данных в формате HTML и XML.
В результате, Python предлагает широкие возможности для создания скриптов, которые осуществляют парсинг и извлечение данных из HTML и XML файлов. Благодаря его мощным инструментам и гибкому синтаксису, разработчики могут создавать эффективные скрипты, которые выполняют разбор, анализ и обработку данных. Независимо от того, нужно ли вам собрать информацию с Интернета или проанализировать большой объем данных, Python и его возможности в парсинге HTML и XML помогут вам достичь желаемых результатов.
Python и парсинг: создание мощных и эффективных скриптов для распарсинга HTML и XML
Распарсинг HTML и XML является важной техникой для работы с данными, содержащимися в веб-страницах и документах. Python предоставляет мощные инструменты для разбора и анализа данных, и написание скриптов для парсинга HTML и XML является одной из его сильных сторон.
Секреты создания эффективных скриптов для распарсинга HTML и XML включают в себя использование правильных методов и техник для извлечения данных из веб-страниц и документов. Python предоставляет различные библиотеки для парсинга и обработки HTML и XML, такие как BeautifulSoup и lxml. Эти библиотеки предоставляют простой и удобный интерфейс для работы с данными.
Один из основных инструментов для парсинга HTML и XML в Python — это парсеры. Парсеры позволяют разбирать и анализировать структуру данных и извлекать нужную информацию. Синтаксический анализатор разбирает HTML или XML и создает структуру данных, которую можно легко обрабатывать и извлекать информацию.
Для создания мощных и эффективных скриптов для распарсинга HTML и XML в Python следует учитывать некоторые важные аспекты. Во-первых, необходимо выбрать правильный парсер в зависимости от типа данных, с которым вы работаете. BeautifulSoup, например, предоставляет простой интерфейс для работы с HTML, в то время как lxml обеспечивает более высокую производительность и возможности для работы с XML.
Во-вторых, при написании скрипта для парсинга следует применять эффективные техники разбора и обработки данных. Использование селекторов CSS и xpath позволяет точно указать элементы, с которыми вы хотите работать, и избежать ненужных операций. Кроме того, использование кэширования запросов может значительно увеличить скорость выполнения скрипта.
Для эффективной обработки и извлечения данных из HTML и XML следует также использовать правильные методы доступа к данным. Использование методов find(), find_all() и select() позволяет легко найти нужные элементы и извлечь из них информацию. Кроме того, использование регулярных выражений может быть полезно при извлечении сложных данных.
В целом, Python предоставляет мощные инструменты и библиотеки для создания эффективных скриптов для распарсинга HTML и XML. Правильное использование этих инструментов и техник позволяет легко обрабатывать и анализировать содержимое веб-страниц и документов, а также извлекать нужную информацию для дальнейшей обработки и анализа данных.
Распарсинг HTML и XML

Распарсинг HTML и XML является одной из ключевых техник программирования на языке Python. Парсеры и анализаторы позволяют создавать мощные и эффективные скрипты для сбора и обработки данных, а также извлечения и анализа содержимого веб-страниц.
Python предоставляет различные библиотеки и инструменты для работы с парсингом HTML и XML. Наиболее популярная библиотека для парсинга HTML — это BeautifulSoup, которая позволяет легко и гибко выполнять разбор HTML-кода и извлекать нужную информацию. Для работы с XML часто используется модуль xml.etree.ElementTree, который предоставляет удобный интерфейс для разбора XML-документов.
При написании скриптов для парсинга HTML и XML важно учитывать синтаксический разбор и структуру данных, с которыми нужно работать. Способность эффективно обрабатывать данные и извлекать информацию из них является ключевой для создания эффективных скриптов парсинга.
Одной из основных задач парсинга HTML и XML является извлечение и анализ содержимого веб-страниц. Для этого используются различные техники, включая поиск по тегам, классам, идентификаторам, а также использование регулярных выражений. Такие техники позволяют собирать нужные данные, например, заголовки новостей, цены товаров или другую информацию.
Важной частью парсинга HTML и XML является работа с данными. После сбора информации необходимо провести ее анализ и обработать с целью получения нужных результатов. С использованием Python и парсеров HTML и XML можно легко и эффективно выполнять такие задачи.
Таким образом, распарсинг HTML и XML — это мощный инструмент для работы с данными, который позволяет создавать эффективные скрипты для сбора и анализа информации. С помощью Python и соответствующих библиотек можно легко освоить тайны создания мощных и эффективных скриптов для распарсинга HTML и XML.
Преимущества использования Python для распарсивания HTML и XML
Язык программирования Python предоставляет мощные инструменты для сбора данных, обработки и анализа информации из HTML и XML. Распарсинг, или парсинг, — это процесс извлечения данных из содержимого веб-страницы или файла с помощью специальных скриптов и техник.
С помощью Python можно создать эффективные и мощные скрипты для распарсивания HTML и XML, которые позволяют анализировать данные, извлекать информацию, а также осуществлять различные операции с данными.
Основные преимущества использования Python для распарсивания HTML и XML:
- Простота и удобство: Python — простой и интуитивно понятный язык программирования, который позволяет легко писать код для парсинга. Он имеет читаемый синтаксис и обширную библиотеку, специализированную для работы с данными HTML и XML.
- Богатая функциональность: Python предоставляет обширные возможности для анализа и обработки данных. С его помощью можно осуществлять поиск и извлечение нужной информации, а также выполнять различные операции с данными, такие как сортировка, фильтрация и агрегация.
- Широкое распространение: Python является одним из самых популярных языков программирования. Это означает, что существует множество ресурсов, библиотек и сообществ, готовых помочь вам в работе с HTML и XML.
- Удобный парсер: В Python существует много различных парсеров для работы с HTML и XML, таких как BeautifulSoup и lxml. Они предоставляют удобные и мощные инструменты для синтаксического разбора и обработки данных.
- Широкие возможности работы с данными: Python обладает мощными возможностями для работы с данными, включая поддержку структурированных данных, таких как таблицы и словари. Это позволяет легко обрабатывать и анализировать данные после их извлечения из HTML и XML.
Использование Python для распарсивания HTML и XML — мощный инструмент для сбора и анализа данных. С его помощью можно легко создать эффективные скрипты для извлечения нужной информации из веб-страниц и файлов, а также осуществлять сложные операции с данными. Используйте тайны мощных скриптов и техники программирования на Python для распарсинга HTML и XML, чтобы улучшить свою работу с данными и получить полезные результаты.
Мощные инструменты Python для распарсивания HTML и XML
Распарсинг HTML и XML является важной техникой обработки данных в программировании. Python предлагает мощные инструменты и библиотеки для разбора и анализа содержимого веб-страниц и XML-документов. С помощью этих инструментов вы можете извлекать и обрабатывать информацию, создавать эффективные и мощные скрипты для парсинга данных.
Одним из самых популярных инструментов для парсинга HTML является Beautiful Soup. Он предоставляет удобный и простой в использовании интерфейс для работы с HTML-кодом. С помощью Beautiful Soup вы можете извлекать данные из HTML-страниц, основываясь на их синтаксической структуре, а также выполнять различные операции анализа и обработки.
Для работы с XML-документами в Python часто используется XML-парсер lxml. Он предлагает мощные и эффективные методы для разбора и обработки XML-файлов. С помощью lxml вы можете извлекать данные из XML-документов, выполнять поиск по элементам, изменять их содержимое и структуру, а также выполнять другие операции анализа и обработки данных.
Помимо Beautiful Soup и lxml, Python имеет множество других библиотек и инструментов для парсинга HTML и XML. Некоторые из них включают в себя: html.parser, xml.etree.ElementTree, xml.dom.minidom и др. Каждая из этих библиотек предлагает свои уникальные возможности и функции для работы с данными.
При создании эффективных скриптов для распарсивания HTML и XML следует учитывать несколько техник и секретов:
- Используйте правильные селекторы для извлечения нужных данных. Селекторы позволяют указывать, какие элементы HTML или XML нужно выбрать для дальнейшей обработки. Например, вы можете использовать CSS-селекторы или XPath для выбора элементов по определенным критериям.
- Используйте регулярные выражения для извлечения информации из текстовых строк. Регулярные выражения предоставляют мощные и универсальные методы для поиска и извлечения данных из текстовых строк, включая HTML и XML.
- Применяйте различные методы обработки данных, такие как фильтрация, сортировка, преобразование и др. Эти методы позволяют обработать и преобразовать данные в нужный формат или вид для дальнейшего анализа и использования.
Однако не забывайте, что при парсинге и обработке HTML и XML следует быть внимательным и аккуратным. Веб-страницы и XML-документы могут содержать неправильные или некорректные данные, поэтому рекомендуется проводить проверку и валидацию данных перед их использованием.
В заключение, Python предоставляет мощные инструменты и библиотеки для распарсивания HTML и XML. С их помощью вы можете создавать эффективные скрипты для извлечения, анализа и обработки данных. Ознакомьтесь с различными инструментами и техниками для парсинга HTML и XML, и вы сможете стать опытным и умелым разработчиком в области скрапинга и анализа данных с использованием Python.
Автоматизация и скриптинг на Python
Python — мощный язык программирования, предоставляющий широкие возможности для автоматизации и скриптинга. Одной из ключевых областей применения Python в сфере анализа данных является парсинг HTML и XML. В этой статье мы рассмотрим секреты создания эффективных скриптов на Python для разбора и обработки данных, а также извлечения информации из HTML и XML.
Парсинг, или разбор, HTML и XML — техники синтаксического анализа и обработки содержимого веб-страниц и документов. С помощью Python мы можем создавать мощные скрипты для распарсинга и анализа данных, сбора информации и обработки содержимого.
Один из основных инструментов для парсинга HTML и XML в Python — модуль BeautifulSoup. Он содержит различные функции и методы для работы с HTML и XML, позволяя легко извлекать нужную информацию из веб-страниц и документов.
С использованием BeautifulSoup мы можем выполнять различные операции, такие как поиск элементов по тегам, классам или атрибутам, извлечение данных из таблиц, создание мощных фильтров и многое другое. Все это делает BeautifulSoup идеальным инструментом для разбора и анализа данных.
Распарсивание HTML и XML с использованием Python и BeautifulSoup может быть эффективным способом для анализа и обработки данных. Однако для создания мощных и эффективных скриптов необходимо знать некоторые техники и секреты написания парсеров.
Одной из ключевых техник является правильный выбор методов и функций BeautifulSoup для работы с HTML и XML. Например, для извлечения текстового содержимого из элемента мы можем использовать методы .text или .string, в зависимости от конкретной ситуации.
Еще одним секретом эффективного парсинга является использование CSS-селекторов для выбора нужных элементов на веб-странице или в документе XML. CSS-селекторы — это мощный инструмент для фильтрации и выбора элементов, который позволяет нам указывать условия выбора в стиле CSS.
Также стоит отметить важность правильной обработки ошибок при парсинге HTML и XML. В случае, если веб-страница или документ XML содержат некорректную структуру или неправильные данные, наш скрипт может выдавать ошибки. Хорошей практикой является обработка возможных ошибок и исключений для предотвращения аварийного завершения скрипта.
В итоге, создание мощных и эффективных скриптов для парсинга HTML и XML с использованием Python — это задача, требующая навыков программирования, знания специфики веб-страниц и документов XML, а также умения применять различные техники и секреты парсинга.
Используя Python и его богатые возможности для автоматизации и скриптинга, мы можем создавать мощные инструменты для сбора, анализа и обработки данных. Благодаря библиотекам, таким как BeautifulSoup, и различным техникам парсинга HTML и XML, мы можем извлекать нужную информацию, анализировать ее и использовать в своих целях.
Преимущества автоматизации с использованием Python
Python является мощным и эффективным языком программирования, который предлагает широкий спектр возможностей для сбора, обработки, анализа и извлечения данных. Он позволяет создавать скрипты и программы для разбора и анализа HTML и XML данных, а также для парсинга и распарсинга содержимого веб-страниц.
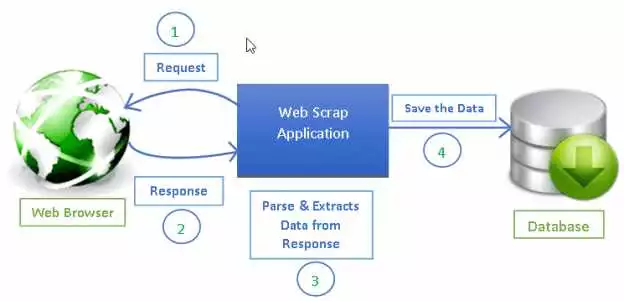
Одной из важных техник, которые Python предоставляет для работы с данными, является скрапинг. С помощью скрапинга можно извлекать информацию с веб-страниц и использовать ее для различных целей, таких как сбор данных, анализ и представление данных.
Преимущества использования Python для скриптов и программ парсеров включают:
- Простота и удобство написания кода: Python имеет простой и понятный синтаксис, что делает его очень легким в использовании для создания парсеров и скриптов для обработки данных.
- Широкие возможности для парсинга данных: Python предоставляет богатый набор инструментов и библиотек для работы с HTML и XML, таких как BeautifulSoup и lxml. Это позволяет эффективно и точно выполнять парсинг, анализ и обработку данных.
- Гибкость и мощность: Python позволяет создавать мощные и эффективные скрипты и программы для сбора, обработки и анализа данных. Его возможности включают работу с различными источниками данных, манипуляцию с данными, обработку ошибок и многое другое.
- Итеративная обработка данных: Python позволяет легко создавать циклы и итерироваться по данным для выполнения различных операций, таких как фильтрация, сортировка, группировка и т.д. Это позволяет эффективно обрабатывать большие объемы данных.
Использование Python для автоматизации распарсинга и анализа данных позволяет значительно упростить и ускорить процесс обработки информации. Благодаря его мощным возможностям и богатому экосистеме библиотек и инструментов, Python становится незаменимым инструментом для создания мощных и эффективных скриптов и программ для парсинга данных.
Использование Python для создания скриптов распарсивания HTML и XML

Python является мощным языком программирования, который позволяет создавать эффективные скрипты для распарсивания и анализа HTML и XML данных. С помощью Python вы можете написать скрипты скрапинга, которые извлекают информацию из веб-сайтов и обрабатывают ее для получения нужных данных.
Секреты создания таких мощных и эффективных скриптов распарсивания заключаются в использовании специализированных библиотек, таких как BeautifulSoup и lxml, которые предоставляют гибкие и удобные инструменты для работы с HTML и XML.
Для работы с HTML и XML данными в Python существуют различные техники и подходы. Например, для парсинга HTML можно использовать синтаксический разбор или использовать CSS-селекторы для извлечения необходимого содержимого. Кроме того, с помощью модуля requests можно получить содержимое веб-страницы, которое затем можно обработать с помощью библиотеки BeautifulSoup или lxml.
При распарсинге XML данных с использованием Python можно использовать модуль xml.etree.ElementTree, который предоставляет удобные средства для анализа и обработки XML. Этот модуль позволяет выполнять парсинг XML документов, извлекать информацию и вносить изменения в данные.
Создание эффективных скриптов распарсивания HTML и XML в Python включает в себя использование различных техник, таких как управление итерациями, обход дерева элементов, извлечение текста и атрибутов, фильтрация данных и т.д. Для более сложных задач можно использовать регулярные выражения или другие инструменты для обработки данных.
Использование Python для создания скриптов распарсивания HTML и XML является мощным и гибким подходом, который позволяет эффективно работать с веб-страницами и другими источниками информации. Функциональность и гибкость языка позволяют легко и удобно обрабатывать данные, выполнять анализ и извлечение необходимой информации.
Парсеры HTML и XML в Python
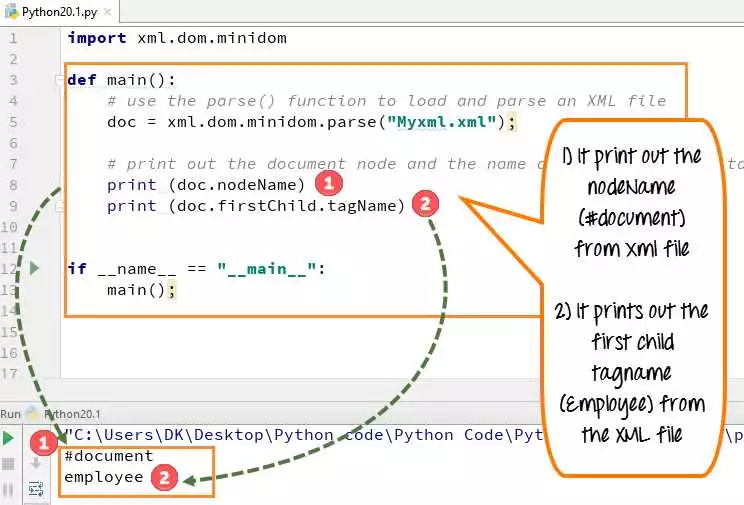
Для более удобного и эффективного распарсивания HTML и XML данных в Python существует множество библиотек и инструментов. Некоторые из наиболее популярных парсеров включают:
- BeautifulSoup — библиотека, которая предоставляет мощные средства для извлечения данных из HTML и XML
- lxml — библиотека, которая сочетает в себе преимущества ElementTree API и XPath выражений
- xml.etree.ElementTree — модуль, входящий в стандартную библиотеку Python и предоставляющий средства для анализа XML данных
- re — модуль регулярных выражений, который позволяет выполнять синтаксический разбор и обработку текста
Эти парсеры позволяют разработчикам Python легко работать с HTML и XML данными, выполнять различные операции обработки и анализа, извлекать необходимую информацию и работать с данными без необходимости писать многословный и сложный код.
Пример использования Python для распарсивания HTML и XML данных

Вот простой пример использования Python и BeautifulSoup для распарсивания HTML данных:
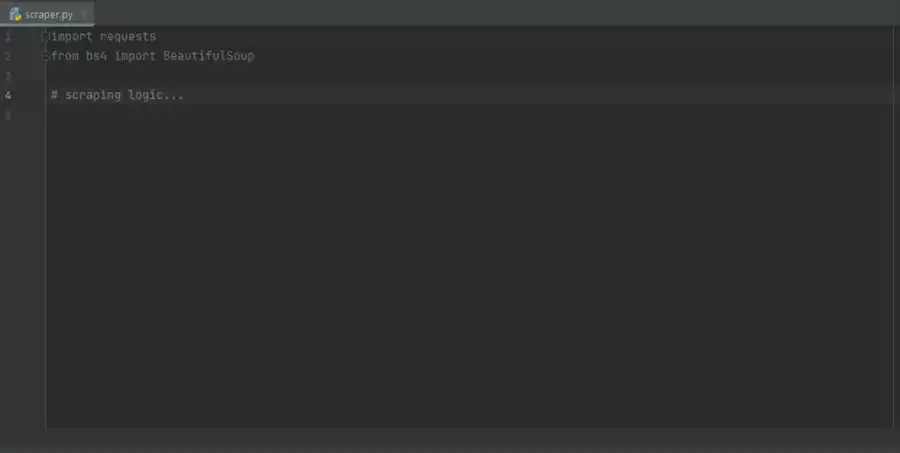
import requests
from bs4 import BeautifulSoup
# Получение содержимого веб-страницы
url = "https://www.example.com"
response = requests.get(url)
html_content = response.text
# Создание объекта BeautifulSoup
soup = BeautifulSoup(html_content, "html.parser")
# Извлечение заголовка веб-страницы
title = soup.title.text
# Извлечение всех ссылок на странице
links = []
for link in soup.find_all("a"):
links.append(link.get("href"))
# Вывод результата
print("Title: ", title)
print("Links: ", links)
В приведенном выше примере мы используем библиотеку requests для получения содержимого веб-страницы и BeautifulSoup для выполнения распарсивания HTML данных. Мы находим заголовок веб-страницы и извлекаем все ссылки на странице.
Аналогично можно использовать Python и другие библиотеки для работы с XML данными, применяя соответствующие методы и функциональность для анализа и извлечения информации.
В заключение, использование Python для создания скриптов распарсивания HTML и XML является мощным и эффективным подходом, который позволяет легко работать с данными и извлекать необходимую информацию. Благодаря богатым возможностями Python и специализированным библиотекам, разработчики могут успешно выполнять анализ и обработку данных из различных источников.
Примеры использования Python для автоматизации и скриптинга

Язык программирования Python предоставляет мощные инструменты для работы с данными, включая возможности для автоматизации сбора и обработки информации из HTML и XML. Парсинг данных и создание эффективных скриптов для распарсинга HTML и XML являются важными техниками анализа содержимого веб-страниц.
Одним из способов использования Python для HTML и XML парсинга является использование модуля BeautifulSoup, который позволяет легко извлекать информацию из HTML или XML файлов. Этот инструмент предоставляет простой и понятный интерфейс для работы с HTML-разметкой, позволяет синтаксический разбор и извлечение нужных данных.
Примеры программирования на Python для автоматизации и скриптинга:
- Сбор данных: Python используется для автоматического сбора данных с веб-страниц. С помощью парсинга HTML или XML, можно извлечь нужную информацию, такую как заголовки новостей, цены товаров, контактные данные и т.д.
- Анализ данных: Python позволяет проводить анализ данных, извлекая нужные значения и проводя статистический анализ. С помощью скриптов на Python можно собирать и обрабатывать большие объемы информации для создания отчетов или для выявления закономерностей в данных.
- Создание эффективных скрапинг и парсинг скриптов: Python имеет различные библиотеки, такие как Scrapy или BeautifulSoup, которые упрощают создание мощных скриптов для распарсивания HTML и XML. Такие скрипты позволяют извлекать нужные данные из веб-страниц и сохранять их в удобном формате.
Python — мощный язык программирования, который предоставляет широкие возможности для работы с данными и их обработки. Используя скрипты на Python, можно создать эффективный парсер для автоматического сбора и анализа информации из HTML и XML файлов.