Python — один из самых популярных языков программирования, который широко используется для обработки данных и автоматизации задач. Извлечение, обработка и анализ HTML и XML файлов являются важными задачами для многих проектов. Для эффективной работы с данными и увеличения производительности своих скриптов, разработчикам необходимо использовать эффективные инструменты и библиотеки. В этой статье мы рассмотрим топ-5 Python библиотек для разбора HTML и XML файлов, которые помогут вам улучшить свои инструменты и программы.

Индивидуальный график
Индивидуальный график
Индивидуальный график
Первая библиотека, которую стоит рассмотреть, это Beautiful Soup. Она является одной из самых мощных и практичных библиотек для парсинга HTML и XML. Beautiful Soup предоставляет простой и интуитивно понятный способ работы с HTML-страницами и XML-документами. Она позволяет разбирать и анализировать данные, извлекать нужные элементы и работать с ними.
Другой мощной и эффективной библиотекой является lxml. Она предоставляет интерфейс для работы с XML и HTML файлами, позволяя разбирать документы, извлекать данные, редактировать их и создавать новые. Lxml отличается высокой скоростью работы и надежностью, что делает ее отличным выбором для обработки больших файлов и производительных задач.
Еще одна популярная библиотека для работы с HTML и XML — xml.etree.ElementTree. Она является частью стандартной библиотеки Python и предоставляет простой и удобный интерфейс для разбора и обработки XML-документов. Xml.etree.ElementTree позволяет извлекать данные, добавлять и изменять элементы, удалять их и выполнять другие операции над XML-структурами.
Для оптимизации работы с XML и HTML файлами, можно воспользоваться lxml.etree. Эта библиотека является частью lxml и предоставляет мощные инструменты для разбора, обработки и анализа XML и HTML данных. Lxml.etree отличается высокой производительностью и эффективностью, что позволяет сократить время работы скриптов и ускорить их выполнение.
Наконец, последняя библиотека, которую стоит упомянуть, это html.parser. Этот модуль является частью стандартной библиотеки Python и предоставляет простой и удобный способ разбора HTML-страниц. Html.parser позволяет извлекать данные из HTML документов, обрабатывать специальные символы и теги, а также создавать и модифицировать HTML структуры.
В заключение, выбор правильной библиотеки для разбора HTML и XML является важным шагом при разработке скриптов на Python. Использование эффективных и мощных инструментов позволит улучшить производительность ваших программ, ускорить их работу и повысить эффективность обработки данных.
Топ-5 Python библиотек для разбора HTML и XML и оптимизации ваших скриптов
1. BeautifulSoup
BeautifulSoup — это одна из самых надежных и популярных библиотек для разбора HTML и XML в Python. Она предоставляет эффективные средства для извлечения данных, парсинга и анализа HTML и XML файлов. BeautifulSoup обладает удобным API и простым синтаксисом, что делает его очень популярным среди разработчиков.
2. lxml
lxml — это мощная и эффективная библиотека для разбора XML и HTML файлов в Python. Она обладает высокой производительностью и ускоряет работу ваших скриптов. lxml предоставляет широкий набор инструментов и функций для работы с данными, включая парсинг, обработку и извлечение информации из XML и HTML файлов.
3. xml.etree.ElementTree
xml.etree.ElementTree — это встроенный модуль Python для разбора XML файлов. Он предоставляет простой и практичный интерфейс для работы с XML данными. xml.etree.ElementTree позволяет эффективно обрабатывать и анализировать XML файлы, извлекать нужную информацию и редактировать структуру документа. Этот модуль хорошо подходит для базовых задач разбора и обработки XML данных.
4. xml.dom
xml.dom — это модуль Python для разбора и обработки XML документов. Он предоставляет набор функций и классов для работы с XML данными. xml.dom обеспечивает полный контроль над структурой и содержимым XML документа. Он позволяет создавать, изменять и удалять элементы, а также осуществлять поиск по дереву элементов XML. Благодаря своей гибкости, xml.dom часто используется для более сложных задач разбора и обработки XML данных.
5. xmltodict
xmltodict — это удобный пакет для разбора XML данных в Python. Он предоставляет простой интерфейс для преобразования XML документов в словари Python. xmltodict преобразует XML структуру в словари, что упрощает работу с данными и обеспечивает более удобный доступ к информации. Этот пакет особенно полезен для работы со сложными XML файлами, где удобства работы с обычными словарями Python гораздо больше.
Использование этих пяти библиотек и пакетов для разбора HTML и XML файлов позволит увеличить эффективность и улучшить скорость работы ваших скриптов и модулей Python. Вы можете выбрать подходящую библиотеку в зависимости от вашей конкретной задачи и требований к обработке данных.
BeautifulSoup — модуль для парсинга HTML и XML
BeautifulSoup — одна из самых мощных и надежных библиотек на языке Python для парсинга и обработки HTML и XML файлов. Она предоставляет широкий набор инструментов и функций для извлечения данных из ваших скриптов, программ и пакетов, а также для оптимизации и улучшения производительности вашего кода.
Одной из главных задач разработчика является разбор и анализ HTML и XML данных. BeautifulSoup предоставляет удобный и эффективный способ распарсинга файлов HTML и XML, что делает его идеальным инструментом для работы с данными, которые содержатся в реальных проектах.
Основные возможности BeautifulSoup:
- Парсинг HTML и XML файлов
- Извлечение данных из HTML и XML структур
- Обработка данных с помощью мощных методов и функций
- Поддержка различных видов выборки элементов (по тегу, классу, id и т.д.)
- Поддержка работы с CSS селекторами
Преимущества использования BeautifulSoup:
- Увеличение скорости разбора и анализа данных
- Улучшение эффективности работы вашего кода
- Надежная и стабильная работа с HTML и XML файлами
- Простота и удобство использования
- Поддержка практичных методов и функций для работы с данными
BeautifulSoup является одной из наиболее популярных и широко используемых библиотек для парсинга HTML и XML на языке Python. Ее гибкость и мощность делают ее идеальным выбором для разработчиков, которым требуется эффективное и надежное средство для работы с данными.
Если вам нужно ускорить работу с HTML и XML файлами, улучшить производительность и оптимизировать ваши скрипты, то BeautifulSoup — один из лучших выборов для вас. Попробуйте использовать эту библиотеку в своем проекте и наслаждайтесь простотой и гибкостью разбора и анализа данных.
Удобный и гибкий инструмент
Python предлагает широкий выбор библиотек и модулей для работы с HTML и XML. Среди них есть несколько практичных и мощных инструментов, которые помогут вам улучшить производительность и эффективность ваших скриптов.
Библиотеки для разбора HTML и XML
- BeautifulSoup — одна из самых надежных и эффективных библиотек для анализа и обработки HTML и XML данных. Она позволяет производить парсинг HTML и XML файлов, извлекать нужные элементы и атрибуты, а также улучшить скорость работы ваших скриптов.
- lxml — мощный и быстрый XML и HTML парсер. Он предоставляет широкие возможности для разбора и обработки XML и HTML файлов, позволяя работать с данными непосредственно в виде объектов.
- xml.etree.ElementTree — стандартный модуль Python для разбора XML файлов. Он предоставляет простой и эффективный интерфейс для работы с XML данными, позволяя извлекать нужные элементы, атрибуты, и текстовые данные.
Библиотеки для оптимизации работы с HTML и XML
- requests — библиотека Python для работы с HTTP запросами. Она позволяет получать HTML и XML данные с веб-страниц, что упрощает процесс получения данных для дальнейшего их разбора и обработки.
- re — модуль Python для работы с регулярными выражениями. Он может быть использован для извлечения нужных данных из HTML и XML файлов, если вы знакомы с синтаксисом регулярных выражений.
Библиотеки для увеличения скорости разбора HTML и XML данных
- html5lib — библиотека для разбора и обработки HTML файлов, основанная на стандартах HTML5 и XML. Она позволяет работать с неправильно структурированными HTML данными, обрабатывая их корректно и эффективно.
- xml.sax — модуль Python для разбора XML файлов в стиле SAX (Simple API for XML). Он позволяет обрабатывать XML данные в виде последовательных событий, что ускоряет процесс их разбора и обработки.
Используйте эти библиотеки и модули для улучшения производительности, эффективности и скорости работы ваших скриптов по разбору, обработке, и оптимизации HTML и XML данных.
Поддержка различных методов разбора

Для извлечения данных из HTML и XML файлов ваших программ на Python существует множество библиотек и инструментов. Выбор правильного инструмента не только улучшит производительность и эффективность ваших скриптов, но также позволит ускорить обработку и анализ данных.
1. Библиотеки для разбора HTML и XML

- BeautifulSoup — одна из самых популярных и мощных библиотек для разбора HTML и XML файлов. Она предлагает широкий набор функций для парсинга и обработки данных.
- lxml — библиотека, основанная на языке программирования C, которая очень эффективна и надежна при разборе больших объемов данных.
- html.parser — это модуль Python, предоставляющий простой и практичный способ парсинга HTML файлов. Он входит в стандартную библиотеку Python и не требует установки сторонних пакетов.
2. Методы оптимизации и увеличения скорости разбора

Для улучшения производительности разбора HTML и XML данных в Python можно использовать следующие методы:
- Выбор правильной библиотеки: выбор библиотеки, наиболее подходящей для конкретной задачи, может существенно повысить эффективность и скорость разбора данных.
- Применение параллельных вычислений: разбор данных можно распараллелить, что позволит ускорить процесс обработки и анализа больших объемов информации.
- Оптимизация запросов: минимизируйте количество запросов к серверу и использование ресурсов при доступе к HTML или XML файлам.
3. Улучшение производительности с помощью эффективных инструментов
| Инструмент | Описание |
|---|---|
| asyncio | Мощный модуль для асинхронной обработки HTML и XML данных, позволяет значительно ускорить процесс разбора и обработки данных. |
| Scrapy | Высокоуровневый фреймворк для извлечения данных с веб-страниц, поддерживающий множество удобных функций для оптимизации и ускорения разбора HTML и XML файлов. |
| pyquery | Модуль, основанный на библиотеке lxml, облегчает извлечение данных из HTML и XML файлов с помощью удобного и простого синтаксиса. |
Выбор оптимального инструмента и оптимизация процесса разбора HTML и XML файлов являются ключевыми аспектами при работе с данными в Python. Эффективность и скорость разбора существенно повысят производительность ваших программ и облегчат анализ данных.
Возможность работы с неправильным HTML кодом
При программировании на Python важно иметь эффективные инструменты для разбора и обработки HTML кода. Однако, не всегда HTML код, с которым приходится работать, является правильным и валидным.
Для работы с неправильным HTML кодом в Python существует несколько надежных и эффективных библиотек, предназначенных для разбора и анализа HTML и XML данных. Рассмотрим практичные и мощные инструменты, которые помогут улучшить производительность и скорость работы ваших программ.
1. BeautifulSoup
BeautifulSoup является одной из самых популярных библиотек для разбора и обработки HTML кода. Она позволяет извлекать данные из HTML файлов и предоставляет удобный интерфейс для работы с различными типами тегов, атрибутами и текстовым содержимым.
2. lxml
lxml — мощная и быстрая библиотека, построена на основе языка программирования C и позволяет парсить XML и HTML файлы. Она обеспечивает эффективность и высокую производительность, что особенно полезно при обработке больших объемов данных.
3. xml.etree.ElementTree
Модуль xml.etree.ElementTree входит в стандартную поставку Python и предоставляет инструменты для разбора и обработки XML данных. Он прост в использовании и эффективен, позволяя с легкостью извлекать информацию из XML файлов.
4. html.parser
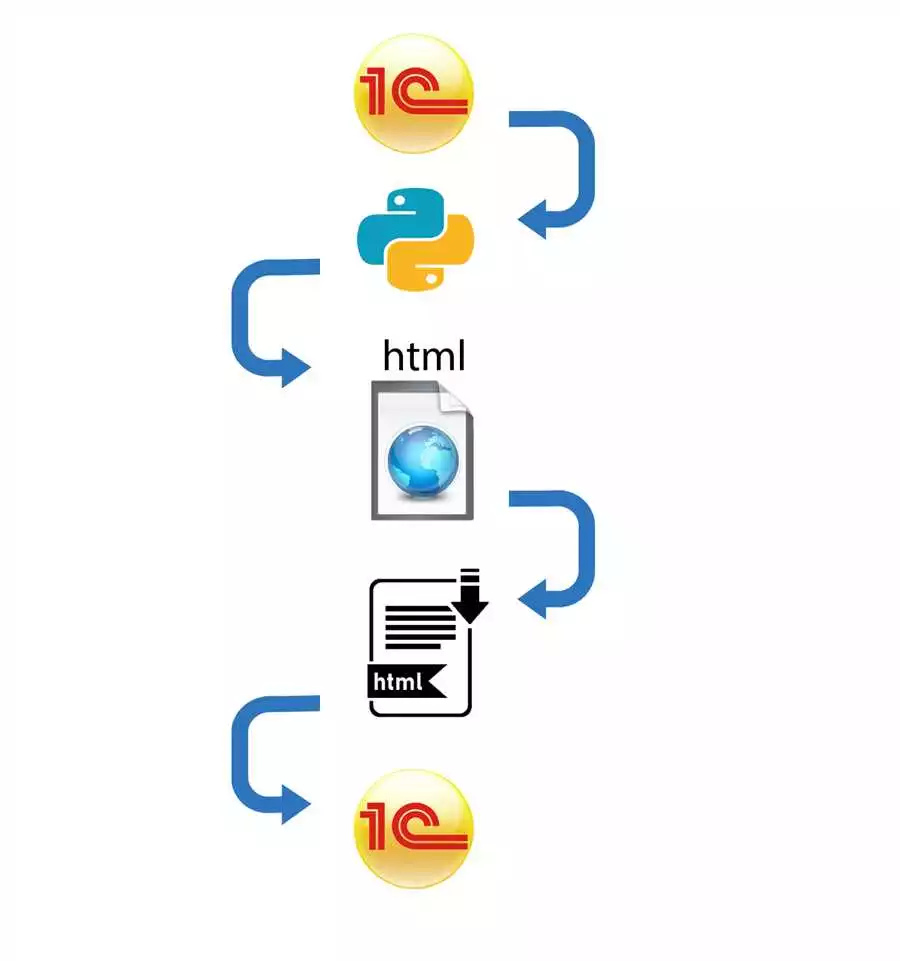
Модуль html.parser также входит в стандартную поставку Python и предоставляет простые и эффективные инструменты для разбора HTML кода. Он хорошо справляется с неправильным HTML и позволяет извлекать информацию из HTML файлов с высокой производительностью.
5. PyQuery
PyQuery — это Python-реализация библиотеки jQuery, которая облегчает работу с HTML и XML файлами. Она предоставляет удобные средства для извлечения данных и улучшения эффективности работы ваших скриптов.
Использование этих библиотек и модулей позволяет эффективно работать с неправильным HTML кодом, увеличивая скорость и производительность обработки данных. Они являются надежными инструментами для оптимизации и улучшения работы ваших программ.
lxml — библиотека для обработки HTML и XML
lxml — это один из наиболее мощных и эффективных инструментов для работы с HTML и XML в Python. Он предоставляет ряд средств для парсинга и обработки файлов таких форматов, а также позволяет увеличить производительность и эффективность ваших программ.
Основные возможности библиотеки
- Разбор HTML и XML файлов
- Извлечение данных из HTML и XML
- Анализ структуры и содержимого файлов
- Обработка и модификация XML-документов
Преимущества использования lxml
lxml является одной из самых практичных и мощных библиотек для разбора HTML и XML в Python. Он обеспечивает высокую скорость и надежность обработки данных благодаря своему эффективному алгоритму. В отличие от некоторых других пакетов для разбора HTML и XML, lxml предоставляет простой и удобный интерфейс и хорошо документированное API.
Пример использования
Для того чтобы начать работать с lxml, вам необходимо установить его с помощью pip:
pip install lxmlПосле установки вы можете импортировать модуль lxml в свои скрипты:
import lxmlДалее вы можете использовать функции и классы, предоставляемые lxml, для обработки и анализа HTML и XML файлов. Например, для разбора XML файла и извлечения данных, вы можете использовать следующий код:
from lxml import etree
# Загрузка XML файла
tree = etree.parse("file.xml")
# Извлечение данных
root = tree.getroot()
data = root.find("data")
value = data.text
print(value)
В этом примере мы сначала загружаем XML файл с помощью функции parse из модуля etree. Затем мы извлекаем корневой элемент файла и находим элемент с тегом «data». В конце мы выводим значение этого элемента на экран.
Заключение
lxml — это мощная и эффективная библиотека для обработки HTML и XML файлов в Python. Он предоставляет набор эффективных инструментов, которые позволяют ускорить и оптимизировать ваши скрипты, а также повысить производительность и эффективность работы с данными.
Высокая скорость разбора
Python предлагает множество эффективных библиотек и средств для разбора HTML и XML данных. Использование этих модулей позволяет увеличить скорость и эффективность анализа и обработки файлов.
1. BeautifulSoup
BeautifulSoup — это один из самых популярных и мощных пакетов для разбора HTML и XML данных в Python. Он предоставляет практичные инструменты для извлечения информации, распарсинга и обработки HTML и XML файлов.
2. lxml
lxml — это быстрый и надежный пакет, который использует C-расширение для парсинга XML и HTML файлов. Он обеспечивает высокую производительность и эффективность при обработке больших объемов данных.
3. xml.etree.ElementTree
xml.etree.ElementTree — встроенный модуль Python, который предоставляет простой и эффективный интерфейс для разбора XML данных. Он обладает надежной производительностью и ускорением при парсинге XML файлов.
4. html.parser
html.parser — это встроенный модуль Python, который предоставляет простой и удобный API для разбора HTML данных. Он является частью стандартной библиотеки Python и обеспечивает надежность и скорость обработки HTML файлов.
5. PyQuery
PyQuery — это библиотека Python, основанная на jQuery-подобном синтаксисе, которая предоставляет удобные методы для разбора, обработки и извлечения данных из HTML и XML файлов. Она обеспечивает улучшение скорости и производительности ваших скриптов.
| Библиотека | Преимущества | Недостатки |
|---|---|---|
| BeautifulSoup | Мощный, практичный, широкий функционал | Медленнее по сравнению с lxml и xml.etree.ElementTree |
| lxml | Высокая производительность, простота использования | Требуется установка C-расширения |
| xml.etree.ElementTree | Полностью встроенная в Python, простота использования | Не такой широкий функционал как BeautifulSoup и lxml |
| html.parser | Встроенный в Python, простота использования | Менее эффективен для сложных HTML структур |
| PyQuery | Удобный синтаксис, близкий к jQuery | Медленнее по сравнению с lxml |
Выбор библиотеки зависит от ваших потребностей в скорости, надежности, удобстве и функциональности разбора HTML и XML данных. Рассмотрите особенности каждой библиотеки, чтобы выбрать наиболее подходящий инструмент для ваших задач.
Возможность выполнения XPath-запросов
Одной из самых практичных и мощных возможностей библиотек для анализа HTML и XML данных в Python является поддержка выполнения XPath-запросов. Многие из популярных модулей и пакетов для разбора файла формата HTML или XML предоставляют эту функциональность, которая значительно улучшает эффективность работы средств парсинга и обработки данных.
Использование XPath-запросов позволяет осуществлять выборку и манипуляцию различными элементами и атрибутами файлов HTML и XML с помощью простого и выразительного синтаксиса. Для повышения производительности и ускорения работы скриптов, многие библиотеки предоставляют оптимизированные функции для выполнения XPath-запросов, что дает возможность эффективно обрабатывать большие объемы данных.
Одной из надежных и эффективных библиотек для выполнения XPath-запросов в Python является инструмент lxml. Этот пакет предоставляет удобный API для разбора и распарсинга файлов HTML и XML, а также позволяет выполнять сложные запросы с использованием XPath. Благодаря его мощным возможностям, вы сможете быстро и эффективно извлекать нужные данные и улучшать производительность ваших программ.
Еще одной популярной библиотекой для выполнения XPath-запросов является модуль xml.etree.ElementTree, входящий в стандартную библиотеку Python. Он предоставляет удобный интерфейс для работы с XML-документами и позволяет выполнять XPath-запросы для выборки данных. Вместе с другими возможностями этого модуля, он может быть полезным инструментом для разбора и обработки XML-файлов в ваших программных проектах.
При работе с файлами формата HTML, библиотека BeautifulSoup является одной из самых распространенных и удобных для выполнения XPath-запросов. Она предоставляет простой API для разбора HTML-документов и позволяет выполнять различные операции с элементами и атрибутами, используя XPath-запросы. Благодаря своим удобным возможностям, BeautifulSoup может значительно упростить работу с HTML-данными и улучшить скорость обработки.
Для увеличения производительности и ускорения выполнения XPath-запросов, рекомендуется использовать библиотеку lxml вместо BeautifulSoup при работе с XML-документами. Lxml предоставляет более эффективные и оптимизированные функции для работы с файлами формата XML, что позволяет значительно улучшить скорость и эффективность выполнения запросов на выборку данных.
В заключение, возможность выполнения XPath-запросов является важным инструментом для работы с данными в формате HTML и XML в Python. Благодаря использованию эффективных библиотек для разбора и обработки файлов HTML и XML, вы сможете значительно улучшить производительность и оптимизировать работу ваших скриптов.
Поддержка XSLT-преобразований
Для распарсинга HTML и XML существует множество библиотек на языке Python, которые предлагают надежные и эффективные инструменты для работы с данными. Однако, при разборе и анализе файлов часто возникают необходимость в их обработке и оптимизации для увеличения скорости и улучшения производительности скриптов.
Для этой цели в Python доступны мощные библиотеки, пакеты и средства, которые предлагают различные способы обработки и преобразования файлов XML и HTML. Одним из таких способов является использование XSLT-преобразований.
Что такое XSLT-преобразования?
XSLT (Extensible Stylesheet Language Transformations) — это язык преобразования XML-документов. Он позволяет определить, каким образом XML-документы должны быть преобразованы в другие форматы, такие как HTML, XML или текстовый формат.
XSLT-преобразования можна использовать для различных целей, например:
- извлечения определенной информации из XML-документов
- оптимизации структуры и формата документов
- улучшения визуального представления данных
- объединения нескольких документов в один
Библиотеки Python для поддержки XSLT-преобразований
Python предлагает несколько библиотек и пакетов, которые предоставляют инструменты для работы с XSLT-преобразованиями:
- lxml — это одна из самых популярных и мощных библиотек для работы с XML и HTML в Python. Она предлагает полную поддержку XSLT-преобразований, а также множество других функций для разбора и обработки XML и HTML.
- xml.etree.ElementTree — это стандартная библиотека Python для работы с XML. Она также предоставляет средства для выполнения XSLT-преобразований.
- 4Suite — это набор инструментов и библиотек, предназначенных для работы с XML и XSLT. Он предлагает удобные средства для выполнения XSLT-преобразований и других задач, связанных с обработкой XML-документов.
Выбор подходящей библиотеки зависит от ваших конкретных потребностей и предпочтений. Но в любом случае, использование XSLT-преобразований может значительно улучшить эффективность и скорость работы ваших скриптов для разбора XML и HTML.
xml.etree.ElementTree — инструмент для работы с XML

xml.etree.ElementTree — это библиотека Python, которая предоставляет простой и эффективный способ извлечения данных из XML-документов. Она является одним из самых популярных инструментов для разбора и обработки XML и широко используется в различных программах и скриптах.
Основные возможности
- Парсинг XML-файлов: с помощью xml.etree.ElementTree вы можете легко разбирать XML-документы и получать доступ к их элементам и атрибутам.
- Манипулирование XML-данными: вы можете создавать, изменять и удалять элементы и атрибуты в XML-документе.
- Генерация XML-файлов: вы можете создавать XML-документы с нуля или добавлять новые элементы и атрибуты к существующим XML-документам.
- Поддержка XPath: xml.etree.ElementTree позволяет использовать язык запросов XPath для выборки нужных элементов из XML-документа.
- Использование callback-функций: библиотека позволяет использовать функции обратного вызова для обработки элементов XML в процессе его разбора.
Преимущества и практическое применение
xml.etree.ElementTree является одним из наиболее надежных и эффективных инструментов для работы с XML в Python. Он обладает хорошей производительностью и скоростью, что делает его практичным выбором для обработки больших объемов данных.
Благодаря простому API и легкости использования, xml.etree.ElementTree подходит для широкого круга задач, включая:
- Извлечение данных из XML-файлов, таких как конфигурационные файлы, логи и протоколы.
- Обработка и анализ XML-документов для извлечения конкретных информационных элементов.
- Генерация XML-документов для создания конфигурационных файлов или других структурированных данных.
- Оптимизация скорости выполнения программ и скриптов, связанных с обработкой XML.
- Улучшение производительности и увеличение эффективности работы ваших программ и скриптов.
Заключение
xml.etree.ElementTree — это мощный инструмент для разбора и обработки XML-документов в Python. Библиотека предоставляет надежные и эффективные средства для извлечения и манипулирования данными в XML-формате. С его помощью вы сможете улучшить производительность и оптимизировать свои скрипты для работы с XML.
Простота использования
Одной из главных преимуществ библиотек для разбора HTML и XML на Python является их простота использования. Благодаря этому, разработчики могут быстро и легко извлекать данные из HTML и XML файлов, а также оптимизировать процесс парсинга и анализа информации.
Python предоставляет пользователю мощные и практичные инструменты для разбора HTML и XML файлов. Среди них можно выделить несколько надежных и эффективных библиотек, которые значительно улучшают производительность и скорость работы скриптов:
- BeautifulSoup/bs4 — это одна из самых популярных библиотек для разбора HTML и XML в Python. Она предоставляет удобный и гибкий интерфейс для работы с DOM-деревом и позволяет легко находить и извлекать нужные данные.
- lxml — библиотека, основанная на языке программирования C, обеспечивает высокую скорость и мощные возможности для работы с XML и HTML файлами. Она предоставляет набор функций и классов для эффективного распарсинга и ускорения работы с данными.
- html.parser — модуль Python, входящий в стандартную библиотеку, обеспечивает простой и удобный интерфейс для разбора HTML файлов. Он позволяет извлекать данные с помощью мощных и эффективных инструментов.
Выбрав одну из этих библиотек, вы сможете значительно увеличить скорость и эффективность работы ваших скриптов, а также улучшить производительность и оптимизацию данных.
Встроенные методы для поиска и работы с элементами
Python предлагает множество встроенных методов и инструментов для разбора HTML и XML, а также для оптимизации и ускорения работы ваших скриптов. Ниже перечислены пять практичных и эффективных библиотек Python для анализа и обработки файлов данных:
- Beautiful Soup: это одна из самых мощных и надежных библиотек Python для парсинга HTML и XML. Она предоставляет простой и интуитивно понятный интерфейс для извлечения данных из веб-страниц и обработки различных элементов.
- Lxml: это библиотека Python, которая предоставляет высокую скорость распарсинга XML и HTML, а также возможности для увеличения производительности и оптимизации программ.
- ElementTree: это встроенный модуль Python для работы с XML. Он предоставляет простой и удобный интерфейс для извлечения и обработки данных из XML-файлов.
- MarkupSafe: это пакет Python, который предоставляет безопасные и эффективные методы для работы с разметкой (markup) HTML и XML. Он позволяет улучшить производительность и увеличить скорость обработки файлов данных.
- html5lib: это библиотека Python, которая реализует полный и надежный разбор HTML и XML согласно стандартам HTML5. Она предоставляет мощные инструменты для работы с элементами и анализа веб-страниц.
Используя эти инструменты и библиотеки Python, вы получите возможность эффективно извлекать и обрабатывать данные из HTML и XML-файлов, а также улучшить производительность и оптимизировать скорость работы ваших скриптов.
Поддержка работы с именованными пространствами и XIncludes
В контексте анализа и оптимизации HTML и XML файлов, особенно при работе с большим объемом данных, важно иметь надежные инструменты и библиотеки. Python предлагает мощные и эффективные библиотеки для парсинга, обработки и улучшения скорости работы ваших скриптов.
1. lxml

Библиотека lxml является одной из наиболее популярных и мощных библиотек для работы с XML и HTML данными в Python. Она предлагает практичные инструменты для извлечения информации, парсинга, обработки и оптимизации XML и HTML файлов. Благодаря своей эффективности и производительности, lxml является незаменимым инструментом для работы с большими объемами данных.
2. BeautifulSoup
BeautifulSoup — это еще одна популярная библиотека Python, которая предлагает удобные возможности для парсинга HTML и XML данных. Она обладает простым и интуитивно понятным API, что делает ее идеальным выбором для начинающих исследователей или программистов, которые хотят получить доступ к данным с минимальными усилиями.
3. ElementTree

ElementTree является модулем Python, входящим в стандартную библиотеку. Он предоставляет удобный API для работы с XML данными, включая поддержку работы с именованными пространствами и XIncludes. ElementTree обладает хорошей производительностью и простым в использовании интерфейсом, что делает его предпочтительным выбором для решения множества задач.
4. xml.etree.ElementTree
Модуль xml.etree.ElementTree также входит в стандартную библиотеку Python и предоставляет базовые инструменты для работы с XML данными. Он поддерживает парсинг и обработку XML файлов, включая работу с именованными пространствами и XIncludes. Несмотря на свою простоту, этот модуль позволяет эффективно работать с XML данными и использовать их в своих программах.
5. xml.sax
Модуль xml.sax предоставляет интерфейс для событийного парсинга XML данных. Он позволяет обрабатывать большие XML файлы, не загружая их целиком в память. xml.sax предоставляет поддержку работы с именованными пространствами и XIncludes, что делает его полезным инструментом для обработки больших объемов данных с минимальными затратами памяти.
Выбор библиотеки для работы с именованными пространствами и XIncludes в Python зависит от ваших потребностей и предпочтений. Однако, вы можете быть уверены, что все эти библиотеки обладают надежной функциональностью для эффективной обработки и анализа XML и HTML данных.