Извлечение данных из HTML и XML-файлов является одним из ключевых этапов в разработке веб-приложений и веб-скрапинга. Для плавного и эффективного получения информации из веб-страниц и структурированных документов необходимо использовать подходящий под задачу кодирование. В этой статье мы представляем пошаговое руководство по разработке с использованием Python, который поможет вам освоить алгоритмы и инструменты для извлечения данных из HTML и XML.

Индивидуальный график
Индивидуальный график
Индивидуальный график
На первом этапе мы ознакомимся с основными элементами HTML и XML, атрибутами и синтаксисом, необходимыми для выполнения парсинга. Затем мы разработаем стратегию для последовательного извлечения данных, рассмотрим различные селекторы и функции для получения нужных значений.
Далее вам будет представлено постоянное руководство по разработке скрипта на Python для автоматического парсинга данных из HTML и XML. Вся информация будет представлена с подробностью и детальными пояснениями каждого шага и каждой инструкции.
Использование специальных модулей Python, таких как BeautifulSoup и xml.etree.ElementTree, позволит нам легко извлекать данные из HTML и XML-файлов. Мы создадим функции, которые будут парсировать файлы пошагово, а также покажем примеры кода для получения информации из различных объектов и элементов.
Как написать скрипт на Python для извлечения данных из HTML и XML: пошаговое руководство
Извлечение данных из HTML и XML может быть сложной задачей, особенно если вы не знакомы с соответствующими языками разметки. Однако, с помощью Python и некоторых специальных модулей, этот процесс можно сделать постепенным и автоматическим.
- Изучите HTML и XML. Прежде чем начать использовать Python для получения данных, вам необходимо понимать структуру HTML и XML файлов. Ознакомьтесь со синтаксисом, ключевыми элементами, атрибутами и значениями.
- Установите необходимые модули. Для работы с HTML вы можете использовать модуль
BeautifulSoup, а для работы с XML — модульxml.etree.ElementTree. Установите их с помощьюpipили любого другого менеджера пакетов Python. - Создайте скрипт парсинга. Разработайте алгоритм и функции для получения нужной информации из HTML или XML файлов. Вы можете использовать пакет
requestsдля получения данных из ссылок или указывать путь к файлам напрямую. - Используйте селекторы. В модуле BeautifulSoup вы можете использовать селекторы, чтобы точно указать, какие элементы вам нужно извлечь. Например, вы можете использовать селекторы CSS или Xpath для определенных элементов.
- Перебирайте элементы. Используйте циклы Python для последовательного извлечения данных из выбранных элементов. Это позволит вам получить все необходимые данные.
- Получите информацию. Вам также потребуется использовать различные методы и атрибуты, чтобы получить детальный результат из каждого элемента. Например, вы можете использовать методы
textилиgetдля получения текстовой информации или значений атрибутов. - Автоматизируйте процесс. Если у вас есть несколько HTML или XML файлов, вы можете разработать автоматический скрипт, который будет извлекать данные из каждого файла по очереди.
В итоге, написание скрипта на Python для извлечения данных из HTML и XML требует подхода пошагового и постепенного. Используйте модули BeautifulSoup и xml.etree.ElementTree для создания парсера, а затем примените разработанный алгоритм для извлечения нужных данных. Используйте селекторы, перебор элементов и методы получения информации для достижения желаемых результатов.
Распарсинг HTML и XML: пошаговое руководство

Если вы хотите извлечь информацию из HTML или XML файлов, вы можете использовать язык программирования Python для создания скрипта, который будет выполнять эту задачу. В этом руководстве будет подробно описан подход к распарсиванию HTML и XML файлов с использованием модулей Python.
Шаг 1: Импортируйте необходимые модули
Перед тем как начать, необходимо импортировать модули, которые будут использоваться в процессе парсинга. Для парсинга HTML вы можете использовать модуль BeautifulSoup, а для парсинга XML — модуль xml.etree.ElementTree.
Шаг 2: Загрузите HTML или XML файл
Следующий шаг — загрузить HTML или XML файл, из которого вы хотите извлечь данные. Для этого необходимо указать путь к файлу или ссылку на него в вашем скрипте.
Шаг 3: Создайте объект парсера
Для парсинга HTML создайте объект парсера с использованием модуля BeautifulSoup, указав тип парсера (например, «html.parser») и кодировку, если это требуется. Для парсинга XML создайте объект парсера с использованием модуля xml.etree.ElementTree.
Шаг 4: Извлеките данные с помощью селекторов
Используя различные селекторы в Python, вы можете получить нужную информацию из HTML или XML файлов. Селекторы позволяют указывать определенные элементы или атрибуты, которые вы хотите извлечь.
Шаг 5: Перебор элементов и получение значений
Чтобы получить информацию из каждого элемента или атрибута, необходимо использовать циклы и функции Python. Перебирая элементы, вы можете получить нужные данные и сохранить их для дальнейшей обработки.
Шаг 6: Разработка алгоритма и создание скрипта
На этом этапе вы можете разработать подробный алгоритм для извлечения данных из HTML или XML файлов. Затем создайте скрипт на Python, который будет последовательно выполнять все необходимые действия.
Шаг 7: Повторяйте постепенно
Выполняйте парсинг HTML или XML файлов пошагово, чтобы убедиться, что ваш скрипт работает правильно. Проверяйте данные, полученные в каждом шаге, и вносите изменения в скрипт при необходимости.
Шаг 8: Использование и сохранение данных
После успешного парсинга, вы можете использовать полученные данные в своих проектах или сохранить их в других форматах (например, Excel, JSON или CSV). Для этого вам могут понадобиться дополнительные модули или функции.
Это подробное руководство по парсингу HTML и XML файлов с использованием Python. Надеемся, что оно поможет вам разработать эффективный и плавный алгоритм для извлечения данных из этих файлов.
Важность извлечения данных из HTML и XML
Автоматическое извлечение данных из HTML и XML является важным шагом в обработке информации. Благодаря этому процессу можно получить доступ к структуре и детальной информации, содержащейся в веб-страницах и документах.
Использование специальных скриптов на языке Python позволяет создать пошаговые и подробные алгоритмы для извлечения данных из HTML и XML файлов. В результате получается подробный список значений, которые могут быть использованы для дальнейшей разработки или анализа.
Один из ключевых этапов в извлечении данных из HTML и XML состоит в парсировании документов. При этом используются различные синтаксические элементы, такие как теги, атрибуты и ссылки. Модуль BeautifulSoup в Python является мощным инструментом для парсинга и обработки HTML и XML файлов, обладающим множеством функций для работы с данными.
Пошаговая инструкция по использованию BeautifulSoup может быть следующей:
- Установите модуль BeautifulSoup с помощью команды pip install beautifulsoup4.
- Импортируйте модуль BeautifulSoup в свой скрипт на Python.
- Загрузите HTML или XML файл для парсинга.
- Создайте объект BeautifulSoup, передав в него загруженный файл и указав соответствующий парсер.
- Используйте селекторы для выбора нужных элементов в документе.
- Получите данные из выбранных элементов, используя соответствующие методы и свойства объекта BeautifulSoup.
- Обработайте полученные данные в соответствии с вашими потребностями.
Такой подход позволяет постепенно и последовательно извлекать данные, анализировать их и использовать в своих проектах. При этом можно осуществить разработку специальных функций, которые будут автоматически парсить данные и возвращать нужную информацию.
Разработка скриптов на Python для извлечения данных из HTML и XML файлов является постоянным процессом прогресса и улучшения. С каждым разом вы будете все глубже погружаться в детали использования BeautifulSoup и улучшать свои навыки по парсингу и анализу данных.
Преимущества использования Python для распарсинга
Python является одним из наиболее популярных и мощных языков программирования для разработки скриптов, включая скрипты для извлечения данных из HTML и XML. Его список преимуществ включает:
- Простой и понятный синтаксис Python облегчает разработку скриптов для парсинга. Детальный и понятный ключевой код позволяет создать эффективную инструкцию для парсирования данных.
- Последовательный шаг за шагом подход в разработке позволяет постепенно создавать скрипт для парсинга, обеспечивая плавный прогресс в получении информации.
- В Python существуют специальные модули и парсеры, которые облегчают процесс извлечения данных из HTML и XML. Эти модули предоставляют функции и методы для работы с элементами, атрибутами и значениями в разметке.
- Python предоставляет множество инструментов для парсинга HTML и XML файлов. Благодаря этому, разработчик может выбрать подходящий инструмент или метод в зависимости от структуры и требований парсинга.
- Подробная документация и обширное сообщество Python обеспечивают постоянную поддержку и ресурсы для разработки скриптов парсинга.
- Гибкая и мощная функциональность Python позволяет разработчику разрабатывать сложные алгоритмы для извлечения и обработки данных. Это дает возможность использовать различные стратегии и подходы к парсингу.
- Автоматическое получение данных из HTML и XML файлов в Python делает процесс парсинга более эффективным и эффективно использует время программиста.
Использование Python для распарсинга данных из HTML и XML файлов позволяет программисту с легкостью извлекать нужную информацию и обрабатывать ее с помощью различных функций и методов. Сочетание простоты и мощи Python делает его идеальным инструментом для разработки скриптов парсинга.
Шаг 1: Загрузка HTML и XML файлов
Перед тем, как приступить к парсированию и извлечению данных из файлов HTML и XML, необходимо их загрузить. В этом разделе мы рассмотрим, как выполнить загрузку файлов и подготовить их для дальнейшей обработки в Python.
Для работы с HTML и XML файлами в Python мы будем использовать модуль BeautifulSoup, который предоставляет удобный интерфейс для парсинга и обработки данных.
Давайте начнем с HTML файлов. Вам потребуется создать объект парсера BeautifulSoup и передать в него HTML файл. Далее вы сможете использовать различные функции и методы этого объекта для постепенного извлечения нужной информации.
Вот пример кода, который демонстрирует этот процесс:
from bs4 import BeautifulSoup
# Загрузка HTML файла
with open("example.html") as file:
html = file.read()
# Создание объекта парсера BeautifulSoup
soup = BeautifulSoup(html, "html.parser")
# Дальнейшая обработка файла
# ...
Теперь перейдем к XML файлам. Для их загрузки и обработки мы также будем использовать модуль BeautifulSoup. Однако в случае XML файлов нам понадобится указать другой парсер — «xml» вместо «html.parser».
Вот пример кода, демонстрирующий этот процесс:
from bs4 import BeautifulSoup
# Загрузка XML файла
with open("example.xml") as file:
xml = file.read()
# Создание объекта парсера BeautifulSoup
soup = BeautifulSoup(xml, "xml")
# Дальнейшая обработка файла
# ...
Теперь вы знаете, как загрузить HTML и XML файлы в Python с помощью модуля BeautifulSoup. Продолжайте следующие шаги, чтобы разработать более детальный способ извлечения данных и обработки файлов.
Подготовка рабочей среды
Перед разработкой скрипта для извлечения данных из HTML и XML необходимо подготовить рабочую среду. Этот этап включает в себя разработку стратегии парсинга, подбор необходимых модулей Python и создание подходящего окружения для кодирования.
- Выберите подход для парсинга
- Установите необходимые модули Python
- Создайте файл скрипта
- Импортируйте необходимые модули
- Получите HTML или XML данные
- Разработайте код для извлечения данных
- Проверьте результаты
Первым шагом в подготовке рабочей среды является разработка стратегии парсинга. Это важный этап, который включает определение объектов и атрибутов, которые вы хотите извлечь из HTML или XML. Детальная и подробная стратегия парсинга поможет вам эффективнее использовать свой скрипт для получения нужной информации.
Для выполнения извлечения данных из HTML и XML вам потребуются специальные модули Python. Один из наиболее популярных и удобных модулей для парсинга HTML и XML — это Beautiful Soup. Он предоставляет простой и интуитивно понятный синтаксис для работы с HTML и XML.
Чтобы установить модуль Beautiful Soup, выполните следующую команду:
pip install beautifulsoup4
После установки модуля Beautiful Soup можно приступить к созданию файла скрипта. Рекомендуется использовать интегрированную среду разработки, такую как PyCharm или Jupyter Notebook, для более плавного и постепенного разработки скрипта. Создайте новый файл скрипта и назовите его, например, «extract_data.py».
В начале скрипта добавьте следующие строки для импорта необходимых модулей:
from bs4 import BeautifulSoup
import requests
Модуль requests позволяет получать HTML-страницу по ссылке. Он автоматически обрабатывает перенаправление и кодирование данных. Модуль BeautifulSoup обеспечивает удобный способ парсинга HTML и XML данных, используя различные селекторы и методы.
Для получения HTML или XML данных вам необходимо указать ссылку или имя файла, который содержит данные. В случае HTML-страницы вы можете использовать модуль requests для получения данных следующим образом:
url = "https://www.example.com"
response = requests.get(url)
html_data = response.text
Если у вас есть XML-файл, вы можете использовать функцию open для чтения файла и получения его содержимого:
with open("example.xml", "r") as f:
xml_data = f.read()
Следующим шагом является разработка кода для извлечения нужных значений из HTML или XML. Для этого вы можете использовать различные методы и селекторы, предоставляемые модулем BeautifulSoup. Например, вы можете использовать метод find или findAll для поиска элементов по тегу или классу. Затем можно получить значение атрибута или текстового содержимого элемента.
После разработки кода для извлечения данных, проверьте его работу на примере данных. Распечатайте извлеченные значения, чтобы убедиться, что скрипт работает правильно и извлекает нужную информацию.
Теперь, когда вы ознакомились с подготовкой рабочей среды, вы готовы перейти к детальному созданию скрипта для извлечения данных из HTML и XML. Это руководство поможет вам более полно освоить процесс парсинга и использования модуля BeautifulSoup.
Открытие и чтение файлов
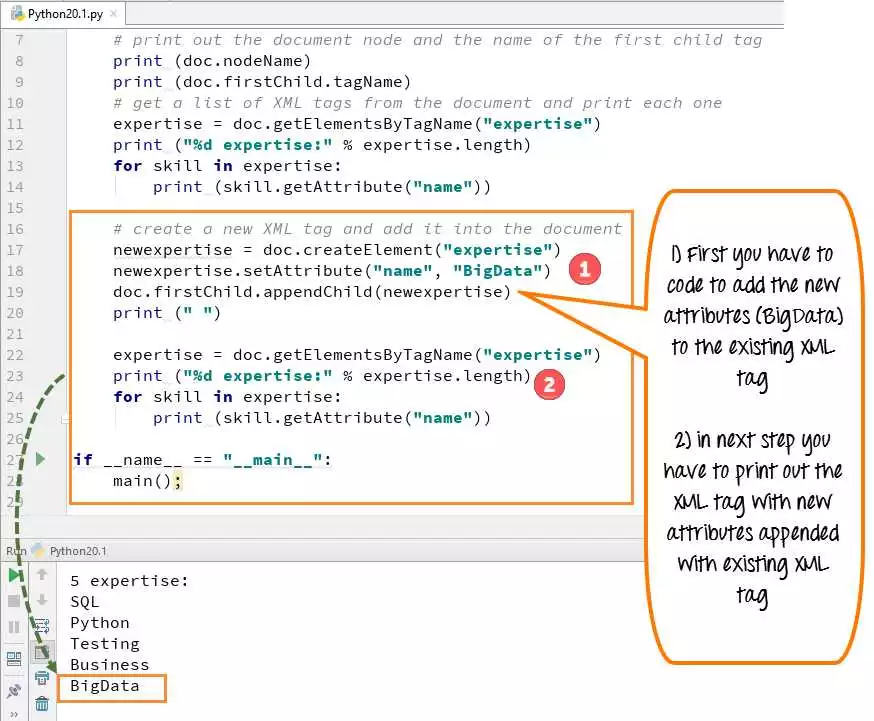
Процесс извлечения данных из HTML и XML файлов в Python может быть разработан в несколько этапов. Первый шаг — это открытие и чтение файлов, в которых содержится информация, которую мы хотим извлечь.
Python имеет встроенную функцию open(), которая позволяет открыть файл и получить объект-файл с атрибутами, позволяющими работать с файлом. Затем мы можем использовать этот объект-файл для чтения данных из файла.
Для открытия файла в Python используется следующий синтаксис:
file = open("file_name", "mode")
В этом коде «file_name» — это имя файла, который мы хотим открыть, а «mode» — это режим открытия файла.
Режимы открытия файла могут быть различными, но наиболее часто используемые режимы — это:
- «r» — режим чтения, который позволяет только чтение файла;
- «w» — режим записи, который позволяет только запись в файл (при этом, если файл существует, его содержимое будет перезаписано);
- «a» — режим добавления, который позволяет записывать данные в конец файла (если он уже существует).
После открытия файла, мы можем использовать методы объекта file для чтения данных. Некоторые из наиболее часто используемых методов:
- read() — чтение всего содержимого файла;
- readline() — чтение одной строки из файла;
- readlines() — чтение всех строк файла в виде списка.
Пример использования методов чтения файла:
file = open("file_name", "r")
content = file.read()
print(content)
file.close()
Когда мы закончили работать с файлом, необходимо закрыть его с помощью метода close() для освобождения ресурсов компьютера.
В данном руководстве будет использоваться более подробный и пошаговый подход к парсингу HTML и XML файлов. Но необходимость в чтении файлов всегда остается постоянной частью разработки алгоритма для извлечения данных. Так что будьте готовы использовать функции для открытия и чтения файлов в своих скриптах на Python.
Парсинг XML прайс-листа поставщика на Python

КАК СОЗДАТЬ XML-ФАЙЛ НА PYTHON?
