Автоматизация задач с использованием языка программирования Python становится все более востребованной. И одной из самых распространенных задач является работа с PDF-файлами. Независимо от того, ведете ли вы деловую документацию, производите анализ данных или реализуете простой скрипт, который поможет упростить манипуляции с PDF, использование Python для автоматизации этих задач является быстрым и эффективным подходом.

Индивидуальный график
Индивидуальный график
Индивидуальный график
В этом практическом руководстве мы рассмотрим несколько способов автоматизации работы с PDF на Python. Мы рассмотрим различные методы и техники, которые позволят вам ускорить и оптимизировать манипуляции с PDF-файлами. Мы покажем вам, как реализовать различные задачи автоматизации, такие как конвертирование PDF в другие форматы, извлечение данных из PDF, добавление водяных знаков, объединение нескольких PDF-файлов и многое другое.
Итак, если вы хотите улучшить свои навыки работы с PDF на Python, этот гайд даст вам необходимые советы и инструкции. Вы узнаете, как использовать различные библиотеки Python для автоматизации работы с PDF, а также познакомитесь с практическими примерами использования этих инструментов. Независимо от того, какой у вас опыт программирования или работы с PDF, этот гайд поможет вам ускорить и упростить вашу работу с PDF-файлами на Python.
Как автоматизировать работу с PDF на Python
PDF-файлы являются широко распространенным форматом документов, и автоматизация работы с ними может значительно упростить и ускорить процессы обработки информации. В этом практическом руководстве мы рассмотрим несколько способов автоматизировать работу с PDF на языке программирования Python, чтобы обеспечить более эффективную и оптимизированную работу.
- Использование библиотеки PyPDF2: Одним из наиболее популярных способов работы с PDF-файлами на Python является использование библиотеки PyPDF2. Эта библиотека позволяет выполнять различные операции с PDF-файлами, такие как чтение текста, извлечение метаданных, объединение или разделение страниц и многое другое.
- Использование библиотеки pdfminer: Еще одной полезной библиотекой для работы с PDF-файлами на Python является pdfminer. Она предоставляет функционал для извлечения текста, изображений и другой информации из PDF-файлов. Библиотека также поддерживает работу с паролями и шифровкой файлов.
- Манипуляции с помощью PDF-файлов: Python также позволяет выполнять различные манипуляции с PDF-файлами, такие как создание новых файлов, добавление и удаление страниц, изменение размера страницы и многое другое. Для этого можно использовать различные библиотеки, такие как reportlab и PyPDF2.
- Оптимизация и ускорение процесса обработки: Для улучшения производительности и ускорения работы с PDF-файлами на Python можно использовать различные техники и подходы. Например, можно использовать многопоточность или асинхронное программирование для одновременной обработки нескольких файлов. Также можно оптимизировать код с помощью использования более эффективных алгоритмов и структур данных.
В этом руководстве мы рассмотрели несколько способов автоматизировать работу с PDF-файлами на Python. Однако важно помнить, что каждая задача может требовать своеобразного подхода, поэтому решение задачи может потребовать комбинирования различных способов и методов. Надеемся, что эти советы помогут вам улучшить эффективность вашей работы с PDF-файлами и сделать ее более быстрой и удобной.
Методы автоматизации работы с PDF на Python
PDF-файлы являются одним из самых популярных форматов для обмена документами, что делает автоматизацию работы с ними важной задачей. Ниже представлено практическое руководство по использованию Python для быстрого и эффективного улучшения манипуляций с PDF.
1. Быстрое чтение и запись PDF-файлов
Одним из способов ускорить работу с PDF на Python является использование сторонней библиотеки, такой как PyPDF2 или PDFMiner. Эти библиотеки позволяют считывать текст из PDF-файлов, извлекать изображения или метаданные, а также записывать новые данные в файлы PDF.
2. Оптимизация PDF-файлов
Для ускорения работы с PDF-файлами можно воспользоваться различными методами оптимизации. Например, можно использовать библиотеку Ghostscript для уменьшения размера файлов PDF без потери качества. Также можно удалять ненужные объекты или объединять несколько файлов в один для упрощения работы.
3. Автоматизация изменений в PDF-файлах
Python позволяет легко реализовать автоматизацию изменений в PDF-файлах. Например, можно использовать библиотеку ReportLab для создания новых PDF-файлов, добавления изображений или таблиц, а также для генерации отчетов или документации на основе данных, хранящихся в других форматах.
4. Использование шаблонов и макросов

Для быстрого создания и форматирования PDF-файлов можно использовать шаблоны или макросы. Например, можно создать шаблон для документации или отчета, в котором будут заданы стандартные элементы (заголовок, номера страниц, разделы и т.д.), а затем использовать Python для генерации новых документов на основе этих шаблонов.
5. Советы по оптимизации и улучшению производительности
Для оптимизации и улучшения производительности работы с PDF-файлами на Python можно использовать следующие советы:
- Использовать библиотеки с открытым исходным кодом, такие как PyPDF2 или PDFMiner, для ускорения чтения и записи файлов.
- Оптимизировать PDF-файлы перед работой с ними для сокращения времени обработки.
- Ограничить использование сложных операций или функций, которые могут замедлить работу.
- Разбить сложные задачи на более простые подзадачи для более эффективного решения.
В заключение, работая с PDF-файлами на Python, необходимо использовать эффективные методы автоматизации и оптимизации для ускорения процесса работы. Это позволит упростить манипуляции с PDF, повысить производительность и получить более эффективные результаты.
Преобразование PDF в текст
Преобразование PDF-файлов в текстовый формат является важной задачей при автоматизации работы с данными. Существует несколько подходов и техник, которые позволяют быстро и эффективно выполнить данную задачу.
В данном руководстве представлено практическое руководство по автоматизации работы с PDF на языке программирования Python. Оно поможет упростить и ускорить манипуляции с PDF-файлами, а также реализовать эффективные методы и способы преобразования PDF в текст.
Использование библиотеки PyPDF2

Одним из способов преобразования PDF-файлов в текстовый формат является использование библиотеки PyPDF2. Данная библиотека предоставляет удобные инструменты для работы с PDF-файлами.
Следующий код демонстрирует простой пример использования библиотеки PyPDF2:
«`python
import PyPDF2
def extract_text_from_pdf(file_path):
with open(file_path, ‘rb’) as file:
pdf_reader = PyPDF2.PdfFileReader(file)
text = »
for page_num in range(pdf_reader.numPages):
page = pdf_reader.getPage(page_num)
text += page.extract_text()
return text
file_path = ‘example.pdf’
text = extract_text_from_pdf(file_path)
print(text)
«`
Данный код открывает PDF-файл с помощью метода `PdfFileReader`, а затем извлекает текст с каждой страницы с помощью метода `extract_text()`.
Таким образом, с использованием библиотеки PyPDF2 можно быстро и удобно преобразовать PDF в текст формат.
Использование библиотеки pdfminer.six
Еще одним эффективным способом преобразования PDF в текст является использование библиотеки pdfminer.six. Данная библиотека предоставляет возможность более точного извлечения текста из PDF-файлов.
Следующий код демонстрирует пример использования библиотеки pdfminer.six:
«`python
from pdfminer.high_level import extract_text
def extract_text_from_pdf(file_path):
text = extract_text(file_path)
return text
file_path = ‘example.pdf’
text = extract_text_from_pdf(file_path)
print(text)
«`
В данном примере мы использовали метод `extract_text` из модуля `pdfminer.high_level`, который позволяет извлекать текст из PDF-файлов.
Таким образом, использование библиотеки pdfminer.six предоставляет более точный и эффективный способ преобразования PDF в текст.
Общие советы и рекомендации
Для улучшения процесса автоматизации преобразования PDF в текст, рекомендуем следовать следующим советам:
- Используйте параллельные вычисления для ускорения обработки большого количества PDF-файлов.
- Оптимизируйте код для улучшения производительности.
- Используйте методы предварительной обработки PDF-файлов (например, удаление изображений) для ускорения процесса преобразования.
- Проверяйте качество текста после преобразования для выявления возможных ошибок.
- Документируйте код и добавляйте комментарии для более легкого понимания.
С помощью этих советов можно улучшить и ускорить процесс автоматизации работы с PDF на языке Python.
Извлечение изображений из PDF

Python является мощным инструментом для автоматизации различных процессов, включая работу с PDF-файлами. Одной из задач, которую можно упростить и оптимизировать с его помощью, является извлечение изображений из PDF.
Для улучшения эффективности работы с PDF-файлами и ускорения процесса извлечения изображений, следует реализовать некоторые методы и техники.
- Использование специализированных библиотек и модулей на языке Python, таких как PyPDF2, pdf2image или pdf2png. Они предоставляют удобные функции для манипуляции с PDF-файлами и извлечения из них изображений.
- Практическое руководство по использованию выбранной библиотеки. Необходимо изучить документацию к выбранной библиотеке и ознакомиться с доступными функциями и их параметрами.
- Разработка собственной функции или класса для извлечения изображений из PDF-файла. Если выбранные библиотеки не подходят для конкретной задачи, можно написать собственные функции или классы на основе доступных методов и способов работы с PDF.
Применение этих методов и способов позволит значительно ускорить процесс извлечения изображений из PDF-файлов и обеспечить быстрое и эффективное выполнение задачи. Необходимо лишь выбрать подходящую библиотеку и осуществить настройку их параметров в соответствии с требованиями и целями проекта.
В итоге, Python предоставляет широкие возможности для автоматизации работы с PDF и реализации различных методов и техник для извлечения изображений из PDF-файлов. С правильным подходом и использованием определенных библиотек и инструментов, можно значительно упростить и ускорить процесс извлечения изображений, а также улучшить эффективность работы с PDF-файлами в целом.
Создание и редактирование PDF-файлов
Создание и редактирование PDF-файлов — практическое руководство по автоматизации работы с PDF с использованием языка программирования Python. Ниже описаны способы реализовать оптимизацию и упростить работу с PDF-файлами, предлагаются методы и техники для быстрого и эффективного улучшения процесса автоматизации.
1. Ускорение работы с PDF-файлами
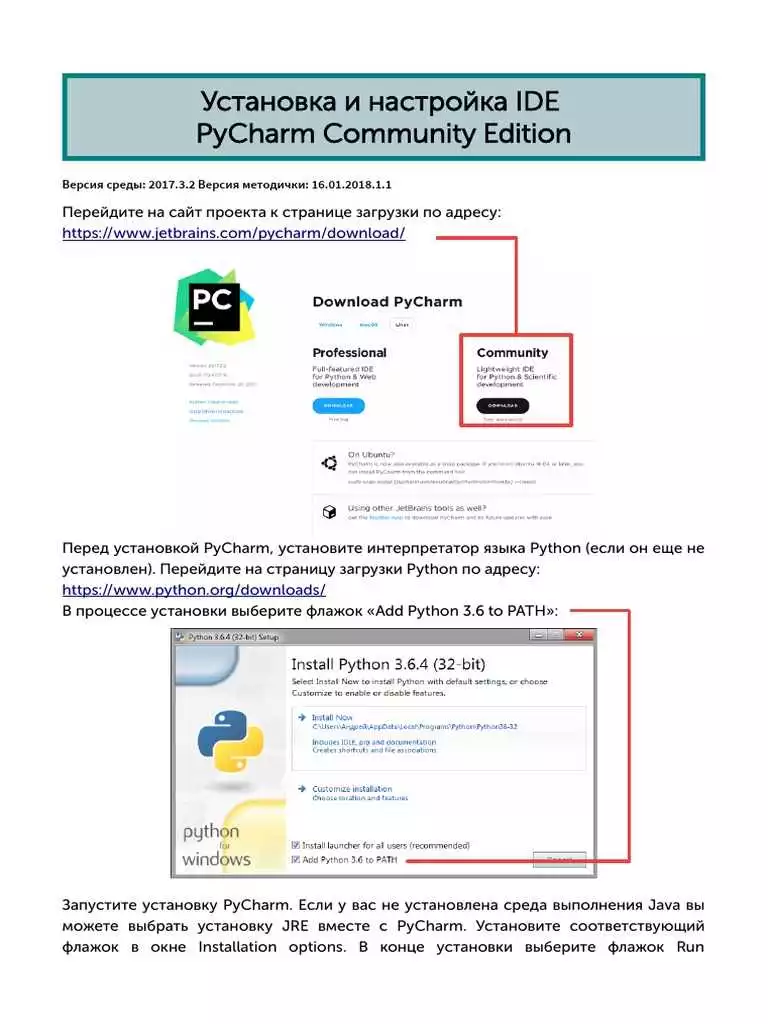
Для ускорения работы с PDF-файлами можно использовать следующие советы:
- Используйте специализированные библиотеки для работы с PDF, такие как PyPDF2, pdfminer.six, ReportLab.
- При работе с большими файлами используйте потоковую обработку данных.
- Оптимизируйте код и избегайте использования ненужных циклов и операций.
2. Быстрое создание и редактирование PDF-файлов
Для быстрого создания и редактирования PDF-файлов в Python можно использовать следующие подходы:
- Используйте библиотеку ReportLab для создания новых PDF-файлов с нуля или для редактирования существующих файлов.
- Используйте PyPDF2 для объединения нескольких PDF-файлов в один и для разделения одного PDF-файла на несколько.
- Используйте pdfminer.six для извлечения текста и данных из PDF-файлов, а также для их редактирования.
3. Улучшение процесса автоматизации работы с PDF
Для улучшения процесса автоматизации работы с PDF рекомендуется использовать следующие методы:
- Структурируйте код и используйте функции и классы для повторных операций.
- Используйте шаблоны для создания документов на основе заданного формата.
- Автоматизируйте процесс работы с PDF через командную строку или через веб-интерфейс.
Резюме
Создание и редактирование PDF-файлов является важным аспектом автоматизации работы с PDF-файлами. Python предоставляет множество библиотек и инструментов, которые позволяют быстро и эффективно работать с PDF. Ознакомившись с описанными методами и техниками, вы сможете ускорить процесс работы и улучшить результаты вашей работы с PDF-файлами.
Быстрая и эффективная инструкция
Python — это эффективный язык программирования, который предлагает множество методов для автоматизации и упрощения работы с PDF файлами. В этом руководстве мы рассмотрим несколько способов реализовать быстрые и эффективные манипуляции с PDF, используя язык программирования Python.
Вот несколько советов и техник, которые помогут вам улучшить и ускорить работу с PDF файлами.
- Использование библиотек: Для работы с PDF файлами в Python существует ряд библиотек, таких как PyPDF2, pdfrw, PyMuPDF и многие другие. Используйте эти библиотеки для упрощения и автоматизации работы с PDF.
- Оптимизация работы с файлами: Если нужно обработать много файлов, рассмотрите возможность использования многопоточности или асинхронности, чтобы ускорить процесс обработки.
- Выбор подходящих методов: Изучите документацию библиотеки и выберите наиболее подходящие методы для конкретных задач. Некоторые методы могут быть более эффективными и быстрыми, чем другие.
- Использование практических примеров: Изучите практические примеры и реализации, чтобы быстро освоиться с работой с PDF на Python.
- Улучшение производительности: Если ваш код выполняется медленно, рассмотрите возможность оптимизации, например, путем использования более эффективных алгоритмов или структур данных.
В итоге, эффективная инструкция по автоматизации работы с PDF на Python включает в себя выбор подходящих библиотек, использование оптимизации и эффективных методов, изучение практических примеров, улучшение производительности и использование различных техник для быстрого и эффективного решения задач.
Установка необходимых библиотек
Если вы хотите автоматизировать работу с PDF на языке Python, то существуют различные способы, чтобы реализовать это. Однако, чтобы упростить и ускорить этот процесс, рекомендуется использовать подход с использованием специальных библиотек.
PDF — это универсальный формат файлов, который широко используется для представления различных данных, включая текст, изображения, таблицы и графики. Использование PDF для автоматизации работы может значительно улучшить эффективность вашего проекта и сэкономить время и ресурсы.
Вот несколько советов и рекомендаций о том, как использовать Python для автоматизации работы с PDF, а также о том, как ускорить и упростить процесс с помощью оптимизации кода и использования специализированных библиотек.
1. Инструкция по установке библиотек

Перед тем, как начать использовать Python для работы с PDF, вы должны установить необходимые библиотеки. Одним из самых популярных пакетов является PyPDF2. Этот пакет позволяет вам работать с PDF-файлами, извлекать текст, изображения и другие данные.
Для установки PyPDF2, вы можете использовать менеджер пакетов pip, выполнив следующую команду:
pip install PyPDF2После установки PyPDF2 вы будете готовы начать работу с PDF-файлами на Python. Однако, в зависимости от ваших потребностей, возможно, вам понадобятся и другие библиотеки, такие как reportlab, pdfrw, PyMuPDF и другие. Поэтому рекомендуется изучить документацию по этим библиотекам и установить необходимые пакеты перед началом работы.
Используйте команды pip для установки дополнительных библиотек. Например, чтобы установить reportlab:
pip install reportlabТакже, возможно, вам потребуется установить некоторые дополнительные зависимости, такие как Ghostscript или ImageMagick, для обработки изображений. Обратитесь к документации по каждой конкретной библиотеке, чтобы узнать о всех требованиях и зависимостях.
После установки всех необходимых библиотек вы будете готовы использовать Python для автоматизации работы с PDF и получать быстрый и эффективный результат.
Преобразование PDF в текст
Преобразование PDF в текст — практическое решение, которое позволяет быстро упростить работу с PDF файлами, автоматизировать определенные задачи и оптимизировать процессы.
Для автоматизации работы с PDF существует множество различных языков и инструментов, но Python является одним из самых популярных и эффективных языков для реализации манипуляций с PDF файлами. Ниже приведены несколько советов и техник по использованию Python для улучшения работы с PDF файлами.
-
Использование библиотеки PyPDF2
Одним из способов преобразования PDF в текст на Python является использование библиотеки PyPDF2. Эта библиотека позволяет работать с PDF файлами, извлекать текст, метаданные и другую информацию. С помощью PyPDF2 можно ускорить процесс преобразования PDF в текст, а также реализовать сложные операции с файлами.
-
Применение подхода «PDF to Text»
Другим эффективным подходом к преобразованию PDF в текст является использование метода «PDF to Text». Этот подход заключается в извлечении текстовой информации из PDF файла без сохранения его форматирования и стилей. Его преимущество в том, что он позволяет быстро получить чистый текст без необходимости обрабатывать форматирование и другие элементы PDF.
-
Использование OCR технологии
Для преобразования сложных PDF файлов, содержащих отсканированные изображения и рукописный текст, можно воспользоваться технологией оптического распознавания символов (OCR). Библиотека pytesseract позволяет использовать OCR для извлечения текста из изображений PDF и преобразования его в обычный текст.
-
Выполнение парсинга PDF с использованием преобразования в HTML
Еще одним способом преобразования PDF в текст является преобразование PDF в HTML и выполнение парсинга HTML для извлечения текста. Это может быть полезно в случаях, когда структура PDF файлов не является обычной и требуется уникальный подход к извлечению текста.
Не существует единого идеального способа преобразования PDF в текст на Python, каждый метод имеет свои преимущества и недостатки. Однако, выбрав подходящий для конкретной задачи метод и применив соответствующие методы и библиотеки, можно значительно ускорить и упростить работу с PDF файлами.
Извлечение и обработка данных

Использование PDF-файлов в процессе работы с данными требует определенных навыков и инструментов. Однако, с помощью Python и некоторых эффективных техник, процесс извлечения и обработки данных из PDF можно значительно упростить и ускорить.
В данном руководстве мы рассмотрим несколько методов и способов, которые помогут вам реализовать автоматизацию работы с PDF-файлами на языке Python. Мы также предоставим вам ряд советов по оптимизации и улучшению процесса работы.
Использование библиотеки PyPDF2
Одним из наиболее популярных инструментов для работы с PDF-файлами на Python является библиотека PyPDF2. Она предоставляет широкий набор функций для извлечения и манипуляции данными в PDF-файлах.
- Установите библиотеку PyPDF2 с помощью pip:
pip install PyPDF2
- Откройте PDF-файл в Python:
import PyPDF2
file = open('example.pdf', 'rb')
pdf = PyPDF2.PdfFileReader(file)
- Извлеките текст из PDF-файла:
text = ''
for page in range(pdf.numPages):
text += pdf.getPage(page).extract_text()
Использование библиотеки tabula-py
Если вам требуется извлечь табличные данные из PDF-файла, вы можете воспользоваться библиотекой tabula-py. Эта библиотека позволяет извлекать данные из таблиц в формате CSV или DataFrame.
- Установите библиотеку tabula-py с помощью pip:
pip install tabula-py
- Извлеките таблицу из PDF-файла:
import tabula
df = tabula.read_pdf('example.pdf')
Использование библиотеки Camelot
Еще одним инструментом, предназначенным для извлечения данных из PDF-файлов, является библиотека Camelot. Она специализируется на извлечении таблиц и предоставляет функции для работы с данными в формате DataFrame.
- Установите библиотеку Camelot с помощью pip:
pip install camelot-py[cv]
- Извлеките таблицу из PDF-файла:
import camelot
tables = camelot.read_pdf('example.pdf')
df = tables[0].df
Дополнительные способы и методы
Кроме библиотеки PyPDF2, tabula-py и Camelot, существуют и другие инструменты для работы с PDF-файлами на языке Python. Некоторые из них могут помочь вам в определенных сценариях и задачах. Вот несколько примеров:
- PDFMiner: библиотека для извлечения текста, метаданных и изображений из PDF-файлов;
- Slate: библиотека для извлечения текста из PDF-файлов;
- PyMuPDF: библиотека для работы с PDF-файлами, основанная на MuPDF;
- PDFQuery: библиотека для извлечения данных из PDF-файлов с использованием XPath-выражений.
Используйте эти инструменты и подходы в зависимости от ваших конкретных потребностей и задач. Это практическое руководство поможет вам быстро и эффективно автоматизировать работу с PDF-файлами на языке Python, а также упростить процесс извлечения и обработки данных.
Работа с PDF и текстовыми файлами
Автоматизация работы с PDF и текстовыми файлами является эффективным способом упростить и ускорить обработку информации. Python — мощный язык программирования, который предоставляет множество инструментов для автоматизации и оптимизации работы с файлами различных форматов.
Для работы с PDF файлами в Python существует несколько подходов. Один из самых популярных способов — использование библиотеки PyPDF2. Эта библиотека позволяет выполнять различные манипуляции с PDF файлами, такие как чтение текста, извлечение изображений, объединение и разделение страниц и многое другое.
Для работы с текстовыми файлами в Python можно использовать стандартные функции языка, такие как чтение и запись данных. Однако, для более удобной и эффективной работы со строками, существуют специальные методы и библиотеки, такие как String Methods и библиотека re для работы с регулярными выражениями.
Оптимизация и ускорение работы с PDF и текстовыми файлами можно достичь путем использования различных методов и техник. Например, для улучшения производительности работы с PDF файлами можно использовать методы кэширования данных или многопоточную обработку. Для ускорения работы с текстовыми файлами можно использовать параллельные вычисления или улучшенные алгоритмы работы с данными.
В данном руководстве будет представлено практическое руководство по автоматизации работы с PDF и текстовыми файлами с использованием языка Python. В нем будут описаны основные методы и техники работы с файлами, а также приведены примеры кода для реализации различных задач.
- Чтение и запись текстовых файлов с использованием стандартных функций языка Python.
- Манипуляции с PDF файлами с помощью библиотеки PyPDF2.
- Оптимизация работы с файлами для улучшения производительности.
- Использование параллельных вычислений для ускорения обработки данных.
Важно отметить, что работа с PDF и текстовыми файлами является неотъемлемой частью множества процессов и задач. Автоматизация и оптимизация этой работы с помощью языка Python позволяет значительно улучшить производительность и эффективность обработки информации.
Чтение и запись текстовых файлов
Одной из основных задач в автоматизации работы с PDF является чтение и запись текстовых файлов. Быстрый и эффективный метод чтения и записи текстовых файлов поможет ускорить ваши манипуляции с PDF-файлами и упростить работу с ними.
Вот некоторые советы и методы, которые помогут вам оптимизировать и улучшить процесс чтения и записи текстовых файлов на Python:
- Используйте модуль Python «io» для ускорения чтения и записи файлов. Этот модуль предоставляет эффективные методы работы с текстовыми файлами.
- Используйте специальные методы чтения и записи, такие как read() и write(), для более быстрой и эффективной обработки файлов.
- Оптимизируйте работу с файлами, используя буферизацию данных. Буферизация данных позволяет улучшить производительность при работе с файлами большого размера.
- Объединяйте операции чтения и записи в одну операцию для ускорения процесса. Например, использование метода writelines() для записи списка строк в файл.
- Используйте контекстный менеджер «with» для автоматического закрытия файла после работы с ним. Это упростит код и предотвратит утечку ресурсов.
- Используйте генераторы для постепенного чтения и записи данных из файла. Это поможет ускорить работу с большими объемами данных.
Приведенные выше методы и советы помогут вам улучшить эффективность работы с текстовыми файлами на Python. Используйте их в практической реализации для автоматизации работы с PDF-файлами и ускорения процесса обработки данных.