В современном мире автоматизация стала неотъемлемой частью нашей повседневной жизни. Особенно в программировании, где задачи могут быть громадными и требовать большого количества времени и усилий. Python — один из самых популярных языков программирования, используемых для автоматизации. Одной из самых полезных библиотек для этой цели является Pandas.

Индивидуальный график
Индивидуальный график
Индивидуальный график
Pandas — это библиотека, разработанная для работы с данными и выполняющая множество задач по анализу данных. С помощью этой библиотеки можно эффективно обрабатывать и анализировать большие объемы данных. Библиотека Pandas предоставляет простой и интуитивно понятный интерфейс для работы с данными, при этом она эффективно использует возможности компьютера.
Применение библиотеки Pandas для автоматизации задач на Python предоставляет широкие возможности. Возьмем, например, задачу обработки большого файла данных. С использованием Pandas можно легко загрузить файл данных, выполнить различные операции с ним, такие как фильтрация, сортировка и агрегация, и выгрузить результаты в новый файл. Благодаря простой и понятной структуре кода, написание скриптов автоматизации этих задач становится гораздо проще и быстрее.
Другой пример использования библиотеки Pandas для автоматизации задач на Python — это создание отчетов и графиков на основе данных. Pandas предоставляет возможность быстро и удобно анализировать и визуализировать данные. С помощью Pandas можно легко сгруппировать данные, вычислить агрегированные показатели и построить графики. Это очень полезно при создании отчетов или презентаций, где требуется быстрый анализ данных и их визуализация. При этом код для автоматизации этих задач на Python с использованием Pandas записывается быстро и легко читается.
Pandas — одна из самых популярных библиотек на Python для анализа и обработки данных. Она предоставляет высокоуровневые структуры данных и инструменты для удобной работы с ними. Pandas может быть очень полезной при автоматизации рутинных задач, связанных с обработкой данных. Ниже приведены примеры кода, которые иллюстрируют различные задачи автоматизации с использованием библиотеки Pandas.
1. Чтение данных из файла
Прежде чем начать обрабатывать данные, необходимо их считать. Pandas предоставляет функциональность для чтения данных из различных форматов файлов, таких как CSV, Excel, SQL и других.
Пример чтения данных из CSV файла:
import pandas as pd
# Чтение данных из CSV файла
data = pd.read_csv('data.csv')
2. Отображение данных
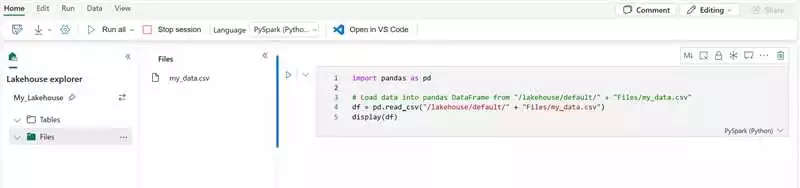
Часто удобно визуализировать данные перед их обработкой. Pandas предоставляет методы для отображения данных в виде таблицы.
Пример отображения первых пяти строк данных:
import pandas as pd
# Чтение данных из CSV файла
data = pd.read_csv('data.csv')
# Отображение первых пяти строк данных
print(data.head())
3. Фильтрация данных
Иногда необходимо выбрать только определенные строки или столбцы данных для работы. Pandas позволяет фильтровать данные на основе определенных условий.
Пример фильтрации данных, чтобы выбрать только строки с определенным значением в столбце «age»:
import pandas as pd
# Чтение данных из CSV файла
data = pd.read_csv('data.csv')
# Фильтрация данных
filtered_data = data[data['age'] > 30]
# Отображение отфильтрованных данных
print(filtered_data)
4. Группировка данных
Группировка данных может быть полезна для агрегирования информации и проведения статистического анализа данных. Pandas предоставляет функциональность для группировки данных по определенным признакам.
Пример группировки данных по значению в столбце «gender» и расчету среднего значения в столбце «age» для каждой группы:
import pandas as pd
# Чтение данных из CSV файла
data = pd.read_csv('data.csv')
# Группировка данных
grouped_data = data.groupby('gender')['age'].mean()
# Отображение группированных данных
print(grouped_data)
5. Запись данных в файл
После обработки данных можно записать их в файл для дальнейшего использования. Pandas позволяет сохранять данные в различных форматах файлов.
Пример записи данных в CSV файл:
import pandas as pd
# Чтение данных из CSV файла
data = pd.read_csv('data.csv')
# Обработка данных...
# Запись данных в CSV файл
data.to_csv('processed_data.csv', index=False)
Вышеуказанные примеры кода демонстрируют лишь некоторые возможности библиотеки Pandas для автоматизации задач по обработке данных. Однако, сочетая ее функциональность с другими инструментами и библиотеками Python, можно автоматизировать и более сложные задачи работы с данными.
Работа с библиотекой Pandas

Pandas — мощная библиотека для анализа данных на языке программирования Python. Она предоставляет высокоуровневые структуры данных, такие как DataFrame, для удобной и эффективной работы с числовыми и табличными данными.
Основными структурами данных в библиотеке Pandas являются:
- Series — одномерный индексированный массив с метками;
- DataFrame — двумерная таблица данных с метками для строк и столбцов;
Библиотека Pandas позволяет выполнять множество операций с данными, включая загрузку данных из различных источников, фильтрацию, сортировку, объединение, агрегацию и визуализацию.
Ниже приведены некоторые примеры использования библиотеки Pandas для автоматизации задач на языке программирования Python:
- Загрузка данных из CSV-файла:
- Фильтрация данных по условию:
- Сортировка данных по столбцу:
- Объединение данных из нескольких источников:
- Агрегация данных для анализа:
- Визуализация данных с использованием библиотеки Matplotlib:
import pandas as pd
data = pd.read_csv('data.csv')
print(data)
filtered_data = data[data['age'] > 30]
print(filtered_data)
sorted_data = data.sort_values('age')
print(sorted_data)
merged_data = pd.merge(data1, data2, on='id')
print(merged_data)
grouped_data = data.groupby('category').mean()
print(grouped_data)
import matplotlib.pyplot as plt
data.plot(kind='bar')
plt.show()
Библиотека Pandas является неотъемлемой частью многих проектов, чтобы облегчить и ускорить работу с данными. Ее эффективность и удобный синтаксис делают ее одним из наиболее популярных инструментов для работы с данными на языке Python.
Установка библиотеки Pandas
Для использования библиотеки Pandas для автоматизации задач на Python, сначала необходимо установить ее. Вот несколько примеров того, как можно установить Pandas:
- Используя pip: Введите следующую команду в командной строке:
pip install pandas
- Используя conda: Введите следующую команду в командной строке:
conda install pandas
После установки Pandas, вы можете начать использовать его для автоматизации задач с использованием Python. Библиотека Pandas предоставляет инструменты для обработки и анализа данных, а также для работы с таблицами и временными рядами.
Пример использования Pandas для автоматизации задач:
- Загрузка данных из файла
- Обработка данных, например, фильтрация, сортировка, удаление дубликатов
- Выполнение вычислений на данных
- Визуализация данных в виде графиков и диаграмм
- Сохранение обработанных данных в файл
Библиотека Pandas широко используется в области анализа данных и машинного обучения, а также для выполнения различных задач, связанных с обработкой и анализом данных.
Установите библиотеку Pandas с помощью выбранного метода установки и начните использовать ее для автоматизации ваших задач на Python!
Импорт библиотеки Pandas
Pandas – это мощная библиотека для работы с данными в Python. Она предоставляет простой и эффективный способ обработки и анализа структурированных данных.
Для использования функционала библиотеки Pandas в Python необходимо импортировать ее в свой код. Для этого используется ключевое слово import. Дополнительно, можно задать псевдоним для более удобного использования.
Примеры использования Pandas для автоматизации задач:
- Чтение и запись данных в различных форматах (CSV, Excel, SQL, JSON и др.)
- Фильтрация, сортировка и группировка данных
- Вычисление статистических показателей и агрегирование данных
- Объединение и преобразование таблиц
- Визуализация данных
Вот пример импорта библиотеки Pandas с присвоением псевдонима:
import pandas as pdТеперь, чтобы использовать функции и методы библиотеки Pandas, можно использовать псевдоним pd. Например:
df = pd.read_csv('data.csv')В данном примере мы используем функцию read_csv() для чтения данных из файла data.csv и сохранения их в переменную df.
Подводя итог, импорт библиотеки Pandas является первым шагом к использованию ее функционала при автоматизации задач на Python. После импорта можно использовать все возможности Pandas для работы с данными.
Основные конструкции и функции Pandas
Python — это мощный язык программирования, широко используемый для анализа данных. Для работы с данными в Python существует множество библиотек, одной из самых популярных из них является библиотека Pandas.
Библиотека Pandas предоставляет различные структуры данных и функции для работы с таблицами и временными рядами. Она часто используется для автоматизации задач, связанных с анализом и обработкой данных.
-
Создание таблицы:
С помощью функции
DataFrame()можно создать таблицу на основе данных из списка, словаря или файла. Например:import pandas as pddata = {'Name': ['John', 'Marry', 'Mike'], 'Age': [25, 30, 35]}df = pd.DataFrame(data)В результате будет создана таблица с двумя столбцами «Name» и «Age».
-
Извлечение данных:
В Pandas есть различные методы для извлечения данных из таблицы. Например:
df.head()— возвращает первые несколько строк таблицы.df.tail()— возвращает последние несколько строк таблицы.df.loc[row_index]— возвращает строку по указанному индексу.df.iloc[row_index]— возвращает строку по указанному числовому индексу.df[column_name]— возвращает столбец по указанному имени.
-
Фильтрация данных:
С помощью метода
df[df[column_name] condition]можно отфильтровать данные по определенному условию. Например:df[df['Age'] > 30]В результате будут отфильтрованы все строки, в которых значение в столбце «Age» больше 30.
-
Группировка данных:
Метод
df.groupby(column_name)позволяет сгруппировать данные по указанному столбцу. Например:df.groupby('Name').mean()В результате будет рассчитано среднее значение для каждого уникального значения в столбце «Name».
-
Объединение данных:
С помощью функции
pd.concat([df1, df2])можно объединить несколько таблиц в одну. Например:df1 = pd.DataFrame({'Name': ['John', 'Marry'], 'Age': [25, 30]})df2 = pd.DataFrame({'Name': ['Mike'], 'Age': [35]})df = pd.concat([df1, df2])В результате будет создана новая таблица, содержащая данные из обоих таблиц.
Примеры использования кода описанных выше конструкций и функций позволяют автоматизировать множество задач по обработке и анализу данных с помощью библиотеки Pandas.
Автоматизация задач на Python

Python — это мощный язык программирования, который предлагает богатый выбор библиотек для автоматизации различных задач. Одной из таких библиотек является Pandas, которая предоставляет широкие возможности для работы с данными.
Библиотека Pandas позволяет загружать, обрабатывать и анализировать структурированные данные. С ее помощью можно выполнять различные операции, такие как сортировка, фильтрация, агрегация и многое другое. Благодаря этому, Pandas становится незаменимым инструментом для автоматизации задач в области анализа данных.
Примеры кода для автоматизации задач на Python с использованием библиотеки Pandas могут включать в себя следующие операции:
- Чтение и запись данных в различных форматах (например, CSV, Excel, SQL).
- Очистка и преобразование данных.
- Фильтрация данных по определенным условиям.
- Агрегация данных с использованием различных функций (например, сумма, среднее значение).
- Создание сводных таблиц.
- Визуализация данных.
Преимущества использования Python и библиотеки Pandas для автоматизации задач заключаются в простоте и гибкости языка, а также богатых возможностях Pandas. Это позволяет эффективно решать различные задачи, связанные с обработкой данных, и повышает производительность и эффективность работы.
Выводя все вместе, автоматизация задач на Python с помощью библиотеки Pandas — это удобный и мощный способ обработки данных, который облегчает рутинные операции и ускоряет аналитические процессы.
Создание скрипта для чтения данных из Excel с использованием Pandas
Python предлагает множество инструментов для автоматизации задач, в том числе и для работы с таблицами Excel. Одной из самых популярных библиотек для работы с данными в Python является Pandas. В этом разделе мы рассмотрим примеры кода для автоматизации чтения данных из Excel файлов с использованием библиотеки Pandas.
Установка библиотеки Pandas
Перед тем как приступить к созданию скрипта, необходимо убедиться, что библиотека Pandas установлена на вашем компьютере. Если она не установлена, ее можно установить с помощью пакетного менеджера pip. В командной строке выполните следующую команду:
pip install pandas
После успешной установки Pandas мы можем приступить к созданию скрипта для чтения данных из Excel файлов.
Пример кода
Ниже приведен пример кода на Python, который демонстрирует чтение данных из Excel файла с использованием библиотеки Pandas:
import pandas as pd
# Указываем путь к Excel файлу
file_path = 'path/to/excel/file.xlsx'
# Чтение данных из Excel файла
dataframe = pd.read_excel(file_path)
# Вывод данных на экран
print(dataframe)
Интерактивное чтение данных
Библиотека Pandas предлагает множество функций для работы с данными, включая возможность интерактивного чтения данных из Excel файла. Ниже приведен пример кода, который демонстрирует использование интерактивного режима чтения данных:
import pandas as pd
# Указываем путь к Excel файлу
file_path = 'path/to/excel/file.xlsx'
# Интерактивное чтение данных из Excel файла
for dataframe in pd.read_excel(file_path, chunksize=1000):
# Обработка данных
print(dataframe)
В приведенном примере данные будут читаться по блокам (chunk) размером 1000 строк, что позволяет работать с большими объемами данных без необходимости загружать все данные в память.
Заключение

Библиотека Pandas предоставляет мощные инструменты для работы с данными в Python. В данном разделе были рассмотрены примеры кода для автоматизации чтения данных из Excel файлов с использованием Pandas. Эти примеры могут быть полезны при работе с таблицами Excel и помогут вам ускорить процесс обработки данных.