Парсинг HTML может быть сложным и запутанным процессом, особенно для программистов-новичков. Большое количество тегов и разнообразные структуры HTML-кода могут создать проблемы при получении нужной информации с веб-страницы.

Индивидуальный график
Индивидуальный график
Индивидуальный график
Однако, благодаря библиотеке BeautifulSoup, эту проблему можно просто и эффективно решить. BeautifulSoup предоставляет удобный и интуитивно понятный способ для парсинга HTML. Она позволяет легко находить нужные элементы на веб-странице и извлекать информацию, которая вам нужна.
В этой статье мы рассмотрим несколько советов и рекомендаций, которые помогут вам успешно преодолеть сложности парсинга HTML с помощью BeautifulSoup. Мы расскажем о важных функциях и методах библиотеки, которые помогут вам понять строение HTML-кода и эффективно извлекать информацию из него.
Советы и рекомендации для начинающих программистов
Парсинг HTML-кода может быть сложной задачей для программистов-новичков. Однако с использованием библиотеки BeautifulSoup упрощается процесс извлечения данных из веб-страницы. В этом разделе рассмотрим некоторые советы и рекомендации, которые помогут преодолеть проблемы, с которыми сталкиваются программисты-новички при парсинге HTML.
Выбор правильного селектора
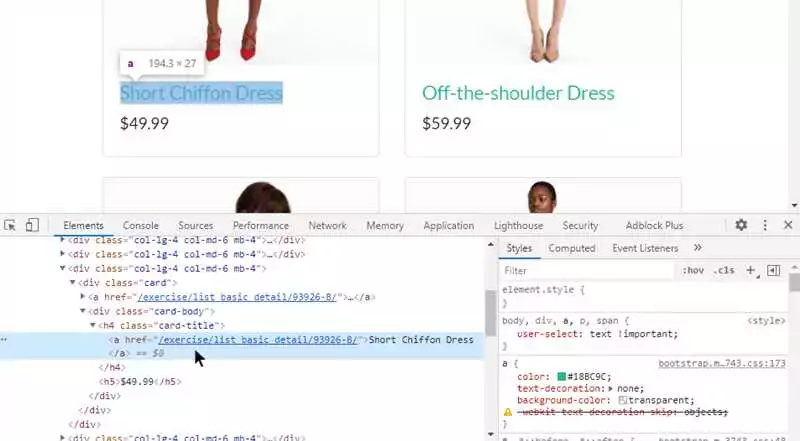
Один из основных шагов при парсинге HTML-кода — выбор правильного селектора. Селектор — это путь к элементу в структуре HTML-документа. Для этого используются CSS-селекторы. С помощью BeautifulSoup можно найти элементы по их тегу, классу, атрибуту и другим параметрам, используя функции find() и find_all().
Например, чтобы найти все элементы с тегом <a>, можно использовать следующий код:
soup.find_all('a')Обработка исключений
При парсинге HTML-кода могут возникать ошибки из-за непредвиденных ситуаций, таких как отсутствие определенного элемента или некорректный HTML-код. Чтобы избежать сбоев программы, рекомендуется обрабатывать исключения.
Например, если вы ожидаете, что элемент с определенным селектором будет всегда присутствовать, но это не всегда так, можно использовать конструкцию try-except для обработки исключения AttributeError:
try:
element = soup.find('selector')
except AttributeError:
element = None
Избегайте жесткой привязки к структуре HTML
Если структура HTML-страницы изменяется, ваш код парсинга может перестать работать. Чтобы избежать этой проблемы, рекомендуется извлекать данные с помощью CSS-селекторов, которые не зависят от конкретной структуры страницы.
Например, вместо привязки к определенным индексам или порядковым номерам элементов, лучше использовать селекторы, такие как «дочерний элемент» или «элемент с определенным классом». Это поможет вашему коду быть более гибким и устойчивым к изменениям в HTML-структуре.
Обработка данных перед использованием
При извлечении данных из HTML-кода рекомендуется обрабатывать их перед использованием. Например, удалить ненужные пробелы или знаки пунктуации, преобразовать строки в числа и т. д.
Для этого можно использовать функции строковой обработки Python или библиотеки для извлечения и преобразования данных, такие как re или numpy.
Работа с таблицами
Работа с таблицами в HTML может быть сложной задачей. BeautifulSoup предоставляет удобные методы для работы с таблицами, такие как find_all('table') и find_all('tr').
Чтобы получить данные из таблицы, вы можете использовать циклы for для перебора строк и ячеек:
table = soup.find('table')
rows = table.find_all('tr')
for row in rows:
cells = row.find_all('td')
for cell in cells:
# обработка данных из ячейки
Также можно использовать индексы строк и столбцов таблицы для извлечения конкретных данных.
Заключение
Преодоление сложностей парсинга HTML с помощью BeautifulSoup может быть вызовом для программистов-новичков. Однако, следуя советам и рекомендациям, вы сможете улучшить свои навыки в парсинге HTML-кода и сделать ваш код более гибким и надежным.
Значение парсинга HTML для программистов-новичков
Парсинг HTML — это неотъемлемая часть работы программистов, особенно для тех, кто только начинает свой путь в этой области. Парсинг HTML представляет собой процесс извлечения структурированных данных из HTML-кода веб-страницы. Использование правильных инструментов и знание основ этого процесса позволяет преодолеть множество сложностей, которые могут возникнуть при работе с HTML.
Одним из самых популярных инструментов для парсинга HTML является BeautifulSoup. Эта библиотека позволяет легко и эффективно осуществлять поиск и извлечение данных из HTML-кода. С помощью BeautifulSoup можно обходить дерево HTML-элементов и получать доступ к содержимому тегов, атрибутам и другим компонентам страницы.
Преимущества использования BeautifulSoup для парсинга HTML очевидны. Во-первых, это удобный и интуитивно понятный инструмент, который позволяет программистам-новичкам быстро освоить основы парсинга HTML-кода. Во-вторых, благодаря возможностям BeautifulSoup можно сэкономить много времени и усилий при анализе и обработке больших объемов данных.
Однако, несмотря на удобство использования BeautifulSoup, парсинг HTML может столкнуть программистов-новичков с некоторыми сложностями. Например, при несовпадении структуры HTML-кода с ожидаемой, могут возникнуть проблемы с поиском и извлечением необходимой информации. В таких случаях важно быть готовым к анализу и исправлению ошибок в HTML-коде.
Преодоление этих сложностей требует наличия определенных навыков и знаний. Программистам-новичкам рекомендуется ознакомиться с основами HTML и CSS, чтобы лучше понимать структуру веб-страницы и правила форматирования. Также полезно изучить основы языка Python, так как BeautifulSoup работает на этом языке.
Вместе с тем, для эффективного парсинга HTML важно научиться использовать различные методы и функции BeautifulSoup. Например, методы find() и find_all() позволяют осуществлять поиск тегов по определенным критериям, а функция get() — получать значения атрибутов. Умение применять эти и другие методы поможет справиться с различными задачами при парсинге HTML-кода.
В итоге, парсинг HTML с помощью BeautifulSoup является важным инструментом для программистов-новичков. Он позволяет преодолеть сложности, связанные с извлечением данных из HTML-кода, и упрощает работу с веб-страницами. Знание основ парсинга HTML и умение работать с BeautifulSoup помогут программистам-новичкам успешно решать задачи по обработке и анализу данных.
Советы и рекомендации для работы с библиотекой BeautifulSoup
Преодоление сложностей парсинга HTML с помощью BeautifulSoup может быть вызвано различными проблемами. В этой статье мы предлагаем несколько советов и рекомендаций для программистов-новичков, которые помогут вам более эффективно работать с этой библиотекой.
- Изучите HTML-структуру: Прежде чем приступать к парсингу HTML-страницы, рекомендуется внимательно изучить ее структуру. Понимание структуры поможет вам легче находить и получать нужную информацию с помощью BeautifulSoup.
- Используйте правильные CSS-селекторы: BeautifulSoup предлагает широкие возможности для выбора элементов на HTML-странице с использованием CSS-селекторов. Изучите основные типы селекторов и практикуйтесь в их применении.
- Используйте регулярные выражения: Для более сложной обработки текста на HTML-странице может потребоваться применение регулярных выражений. BeautifulSoup предоставляет функциональность для работы с регулярными выражениями, которую стоит изучить.
- Обрабатывайте возможные ошибки: При работе с HTML-страницами могут возникать различные ошибки, например, отсутствие необходимых элементов или неожиданные изменения в структуре страницы. Рекомендуется обрабатывать эти ошибки с помощью соответствующих конструкций в вашем коде.
- Тестируйте ваш код: Перед применением вашего кода на реальных данных рекомендуется провести тестирование на небольших образцах HTML-страниц. Это поможет вам обнаружить и исправить возможные ошибки и улучшить работу вашего парсера.
Надеемся, что эти советы и рекомендации помогут вам успешно преодолеть сложности парсинга HTML с использованием библиотеки BeautifulSoup. Удачи в вашей работе!
Изучение основных функций BeautifulSoup
Парсинг HTML является важной частью работы программиста. Он позволяет извлекать информацию со веб-страницы и анализировать ее. Одним из самых популярных инструментов для парсинга HTML является BeautifulSoup.
BeautifulSoup — это библиотека Python, которая облегчает преодоление сложностей парсинга HTML. Она предоставляет простой и удобный способ извлекать данные из HTML-разметки, а также проводить различные манипуляции с ними.
Вот несколько основных функций BeautifulSoup, которые помогут вам начать работу с этой библиотекой:
- BeautifulSoup(html, «html.parser») — функция для создания объекта BeautifulSoup из HTML-страницы. В качестве аргументов она принимает HTML-код и используемый парсер.
- tag — объект, представляющий HTML-тег, например или . С помощью этого объекта можно получать доступ к атрибутам и содержимому тега, а также проводить различные манипуляции.
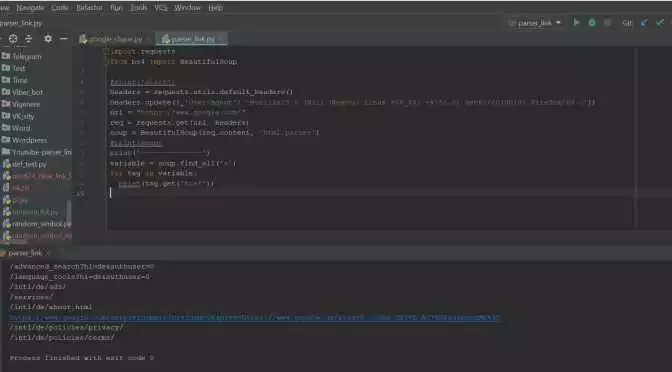
- .find(tag) — метод BeautifulSoup, который позволяет найти первый элемент на странице с заданным тегом. Например,
soup.find("h1")найдет первый тег<h1>на странице. - .find_all(tag) — метод BeautifulSoup, который позволяет найти все элементы на странице с заданным тегом. Например,
soup.find_all("a")найдет все теги<a>на странице. - [«attribute»] — специальный синтаксис для доступа к атрибутам тега. Например,
tag["href"]вернет значение атрибутаhrefу тега. - .get_text() — метод BeautifulSoup, который позволяет получить текстовое содержимое элемента. Например,
tag.get_text()вернет текстовое содержимое тега. - .prettify() — метод BeautifulSoup, который форматирует HTML-код, делая его более читабельным. Например,
soup.prettify()вернет отформатированный HTML-код страницы.
Изучение этих основных функций поможет вам начать парсить HTML-страницы с помощью BeautifulSoup. Не стесняйтесь экспериментировать и применять эти знания к реальным проектам. Удачи в изучении и использовании BeautifulSoup!