BeautifulSoup — это мощная библиотека для Python, которая предоставляет широкий спектр возможностей для работы с HTML и парсинга данных с веб-страниц. Эта библиотека дает разработчикам инструменты для извлечения нужных данных из HTML-страниц и образования информации в удобном для анализа виде. Таким образом, BeautifulSoup позволяет с легкостью собирать и анализировать данные, которые в дальнейшем могут быть использованы для различных целей, таких как создание баз данных или визуализация информации.

Индивидуальный график
Индивидуальный график
Индивидуальный график
BeautifulSoup предоставляет простой и интуитивно понятный способ обработки HTML. Он делает весь процесс парсинга и извлечения данных из HTML простым, понятным и эффективным. С помощью BeautifulSoup разработчики могут быстро настраивать и настраивать проекты, не тратя много времени на написание длинного и сложного кода.
Одна из главных особенностей BeautifulSoup — его способность обрабатывать сложные структуры HTML, такие как вложенные теги, классы и атрибуты. Он позволяет легко идентифицировать и извлекать нужные элементы из HTML-страницы, используя различные методы и фильтры. BeautifulSoup также предоставляет возможность работать с HTML-кодом, который содержит ошибки, и автоматически исправлять их, чтобы облегчить процесс извлечения данных.
Использование BeautifulSoup в работе с HTML и парсингом данных с веб-страниц может значительно упростить и ускорить процесс разработки. Эта мощная библиотека отлично подходит для разработчиков, которым приходится работать с большим объемом данных и искать определенную информацию. BeautifulSoup является незаменимым инструментом для всех, кто занимается анализом данных или веб-скрапингом.
Познакомьтесь с BeautifulSoup: упрощение работы с HTML и парсинг данных с веб-страниц
BeautifulSoup — это библиотека Python, которая позволяет легко и эффективно работать с HTML кодом веб-страниц и осуществлять парсинг данных с них.
Для многих программистов и веб-разработчиков, работа с HTML-кодом может быть одной из самых сложных и утомительных задач. Но благодаря BeautifulSoup, это становится гораздо проще.
Одной из основных возможностей BeautifulSoup является его способность разбирать HTML код, создающий древовидную структуру, которую мы можем легко обрабатывать и извлекать данные.
Обзор возможностей BeautifulSoup:
- Упрощение работы с HTML-кодом: BeautifulSoup позволяет нам обращаться к элементам HTML-структуры с помощью удобного и интуитивно понятного синтаксиса.
- Парсинг данных с веб-страниц: BeautifulSoup позволяет извлекать данные из веб-страниц, такие как текст, атрибуты, ссылки и многое другое. Это делает его очень полезным инструментом для анализа и обработки данных.
- Поддержка различных типов парсера: BeautifulSoup поддерживает различные типы парсера, включая встроенный парсер HTML, парсеры lxml и html5lib. Это позволяет выбрать наиболее подходящий парсер для вашей конкретной задачи.
В общем, BeautifulSoup значительно упрощает работу с HTML и позволяет нам легко и эффективно парсить данные с веб-страниц. Он является очень популярной библиотекой среди веб-разработчиков и исследователей данных и оказывается очень полезным инструментом для автоматизации и анализа информации.
Роль BeautifulSoup в работе с HTML
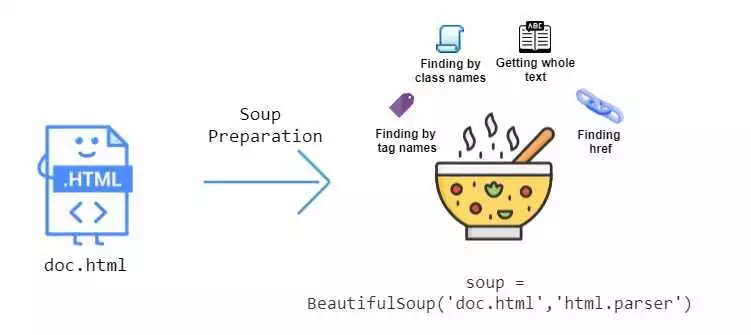
BeautifulSoup — это Python библиотека, которая позволяет упростить работу с HTML и осуществлять парсинг данных с веб-страниц. Она предлагает широкий спектр возможностей для облегчения работы с HTML-кодом и удобного извлечения нужной информации.
HTML (HyperText Markup Language) является основным языком разметки веб-страниц. Он состоит из различных тегов, которые определяют структуру и содержимое страницы. Однако иногда получить нужные данные из HTML-кода может быть сложно вручную, особенно если страница содержит большое количество информации.
BeautifulSoup позволяет упростить этот процесс, предоставляя инструменты для обработки и разбора HTML-кода. Она позволяет работать с HTML в удобной и понятной форме, позволяя извлекать нужные данные и проводить различные манипуляции над ними. Библиотека предлагает легковесный и интуитивно понятный интерфейс, который делает работу с HTML более эффективной.
- BeautifulSoup позволяет легко извлекать данные из HTML-кода. Благодаря мощным методам для поиска нужных элементов, вы можете извлекать содержимое тегов, атрибуты и другие данные, не перебирая весь код вручную.
- С помощью BeautifulSoup вы можете легко обрабатывать и манипулировать HTML-кодом. Это может быть полезно для удаления нежелательных элементов, изменения структуры страницы или добавления новых данных.
- Библиотека предоставляет возможности для навигации по дереву HTML-элементов. Вы можете осуществлять поиск элементов на основе их тегов, классов, id и других атрибутов, а также перемещаться по родительским и дочерним элементам.
- BeautifulSoup также предлагает функции для работы с текстовыми данными. Вы можете извлекать только текст из элементов, очищать его от лишних пробелов и форматировать по своему усмотрению.
В целом, BeautifulSoup предоставляет полный обзор и контроль над HTML-кодом. С ее помощью вы можете легко извлечь нужные данные, выполнить различные манипуляции и упростить понимание структуры веб-страницы. Благодаря своим удобным возможностям, BeautifulSoup стал неотъемлемым инструментом в работе с HTML и парсинге данных с веб-страниц.
Пример использования BeautifulSoup для парсинга HTML:
from bs4 import BeautifulSoup
# Создание объекта BeautifulSoup из HTML-кода
html_code = "
Текст на странице
"
soup = BeautifulSoup(html_code, 'html.parser')
# Извлечение текста из элементов
heading = soup.h1.text
paragraph = soup.p.text
print("Заголовок:", heading)
print("Параграф:", paragraph)
Основные преимущества использования BeautifulSoup
BeautifulSoup — это библиотека для парсинга HTML и XML, которая облегчает работу с веб-страницами и извлечение данных из них. Вот основные преимущества использования BeautifulSoup:
- Простота использования: BeautifulSoup предоставляет простой и понятный интерфейс для работы с HTML. Вы можете легко найти и извлечь данные, обходить элементы страницы и манипулировать ими с помощью простых методов и атрибутов.
- Гибкость: BeautifulSoup поддерживает различные способы поиска и фильтрации элементов страницы. Вы можете использовать разные типы селекторов, операторы, фильтры и регулярные выражения для получения нужных данных.
- Возможность работы с «грязным» HTML: BeautifulSoup может работать с неполным, недействительным или плохо отформатированным HTML. Он автоматически исправляет ошибки и приводит код в правильную форму, что упрощает его парсинг и обработку.
- Обзор структуры страницы: BeautifulSoup позволяет легко просматривать и анализировать структуру веб-страницы. Вы можете получить список всех тегов, атрибутов и текстовых данных на странице, а также их взаимосвязь и иерархию.
- Извлечение данных: BeautifulSoup предоставляет возможность извлекать конкретные данные из HTML, такие как текст, URL, ссылки, изображения, таблицы, списки и другие элементы страницы. Вы можете получить доступ к этим данным с помощью простых методов и атрибутов объектов BeautifulSoup.
- Поддержка разных типов данных: BeautifulSoup поддерживает работу не только с HTML, но и с XML. Вы можете использовать его для парсинга и обработки различных типов данных, с которыми вам приходится работать.
В целом, BeautifulSoup является мощным инструментом для парсинга данных с веб-страниц и обладает множеством возможностей, которые помогут вам упростить и ускорить работу с HTML и XML.
Работа с библиотекой BeautifulSoup
Библиотека BeautifulSoup является одним из наиболее популярных инструментов для работы с парсингом данных с веб-страниц. Она предоставляет широкие возможности для упрощения процесса извлечения информации из HTML-кода.
BeautifulSoup позволяет легко и эффективно обрабатывать HTML-страницы, а также осуществлять поиск и извлечение нужных данных. Благодаря своему интуитивному интерфейсу и гибким функциям, библиотека является незаменимым инструментом для разработчиков и аналитиков данных.
Одной из ключевых особенностей BeautifulSoup является его способность работать с любыми веб-страницами, независимо от их сложности. Библиотека предоставляет мощные инструменты для извлечения данных с веб-страниц, включая возможность находить и обрабатывать HTML-теги, классы, идентификаторы, атрибуты и т.д.
Для работы с BeautifulSoup необходимо импортировать соответствующий модуль и создать объект, представляющий интересующую нас HTML-страницу. Затем можно использовать различные методы и функции BeautifulSoup для поиска и извлечения нужных данных.
Благодаря возможностям BeautifulSoup, парсинг данных с веб-страниц становится проще и быстрее. Библиотека предоставляет множество функций и методов, которые упрощают процесс обработки HTML-кода и извлечения нужных данных.
Возможности BeautifulSoup включают:
- Поиск и извлечение данных с помощью метода
find()илиfind_all(); - Итерация по HTML-элементам;
- Извлечение содержимого тегов;
- Получение атрибутов тегов;
- Поиск по CSS-селекторам;
- Фильтрация результатов поиска;
- И многое другое.
С помощью BeautifulSoup можно обрабатывать сложные структуры HTML-кода, такие как таблицы, списки и многоуровневые вложения. Библиотека предоставляет инструменты для работы с такими структурами, что позволяет легко и быстро извлекать нужные данные из веб-страниц.
Таким образом, использование библиотеки BeautifulSoup значительно упрощает работу с HTML-кодом и парсингом данных с веб-страниц. Его возможности и гибкость делают извлечение информации из веб-страниц быстрым и эффективным процессом, что делает библиотеку популярным выбором среди разработчиков и аналитиков данных.