Автоматический сбор данных с веб-сайтов стал неотъемлемой частью современного мира, где информация играет ключевую роль. Однако сбор данных вручную может быть трудоемким и затратным процессом, особенно при работе с большими объемами информации. В этом случае библиотека BeautifulSoup на Python становится незаменимым инструментом.

Индивидуальный график
Индивидуальный график
Индивидуальный график
BeautifulSoup — это библиотека для разбора HTML и XML-документов, которая позволяет извлекать данные из веб-страниц. Ее основная цель — упростить процесс анализа структуры веб-страницы и получение нужной информации. Библиотека предоставляет удобные методы для поиска, фильтрации и извлечения информации из HTML-разметки.
Работа с BeautifulSoup начинается с загрузки веб-страницы и ее разбора с использованием соответствующего парсера. Затем можно осуществлять поиск необходимых элементов и извлекать нужные данные. BeautifulSoup предоставляет мощный инструментарий для навигации по структуре HTML-документа и работе с его содержимым. Методы библиотеки позволяют осуществлять поиск по тегам, классам, идентификаторам, а также использовать сложные условия для более точного поиска.
Основы работы с библиотекой BeautifulSoup: автоматический сбор данных с веб-сайтов на Python
Библиотека BeautifulSoup является мощным инструментом для сбора данных с веб-сайтов на языке программирования Python. С помощью этой библиотеки, разработчики могут легко извлекать информацию из HTML и XML документов, структурировать ее и проводить анализ данных.
Для начала работы с библиотекой BeautifulSoup необходимо установить ее на свой компьютер. Для этого можно использовать менеджер пакетов pip, выполнив команду pip install beautifulsoup4 в командной строке или терминале.
После успешной установки библиотеки необходимо импортировать ее в свой проект. Для этого можно использовать следующую строку кода:
from bs4 import BeautifulSoupИмпортируя эту библиотеку, вы получаете доступ к множеству функций и методов, которые помогут вам провести сбор данных с веб-сайтов.
Одной из основных возможностей BeautifulSoup является поиск элементов на веб-странице по тегам, классам или идентификаторам. Для этого можно использовать методы find() и find_all(). Метод find() позволяет найти первый элемент, соответствующий указанным параметрам, а метод find_all() находит все элементы, соответствующие указанным параметрам.
Пример использования метода find():
soup = BeautifulSoup(html, 'html.parser')
element = soup.find('p', class_='content')
В данном примере мы создаем объект BeautifulSoup, передавая ему HTML код страницы и указывая парсер (например, ‘html.parser’). Затем мы ищем первый элемент p с классом content и сохраняем его в переменной element.
После того, как вы найдете нужные элементы на странице, вы можете извлечь информацию из них, используя различные методы и атрибуты BeautifulSoup. Например, вы можете получить текст элемента с помощью атрибута .text:
text = element.textТакже вы можете получить значение атрибута элемента, используя атрибут .get():
attribute_value = element.get('attribute_name')Библиотека BeautifulSoup также предоставляет удобный способ навигации по структуре HTML документа. Например, вы можете получить родительский элемент элемента с помощью атрибута .parent:
parent_element = element.parentТакже вы можете получить следующий или предыдущий элемент на том же уровне иерархии с помощью атрибутов .next_sibling и .previous_sibling.
Для работы с таблицами на веб-странице, BeautifulSoup предоставляет методы для поиска и извлечения данных из ячеек и строк таблицы.
Основы работы с библиотекой BeautifulSoup на Python позволяют собирать данные с веб-сайтов автоматически и использовать их для различных целей, таких как анализ данных, создание отчетов и многое другое.
Основные принципы работы с библиотекой BeautifulSoup
BeautifulSoup — это библиотека на языке Python, которая позволяет осуществлять автоматический сбор данных с веб-сайтов. Она предоставляет простой и удобный способ парсить HTML-код и извлекать нужную информацию.
Основой работы с BeautifulSoup является объектный дерево, которое представляет структуру HTML-документа. Для начала работы с библиотекой необходимо импортировать её в проект:
from bs4 import BeautifulSoup
Далее необходимо передать в конструктор BeautifulSoup HTML-код в виде строки. Например, для парсинга веб-страницы можно воспользоваться библиотекой requests:
import requests
response = requests.get("https://www.example.com")
soup = BeautifulSoup(response.text, 'html.parser')
Теперь объект soup представляет структуру веб-страницы и позволяет извлекать нужные данные.
Для поиска нужных элементов на странице можно использовать методы поиска, такие как find() и find_all(). Метод find(tag, attrs, recursive, text) возвращает первый элемент, соответствующий переданным атрибутам:
element = soup.find('h1', {'class': 'title'})
Метод find_all(tag, attrs, recursive, text) возвращает список всех элементов, соответствующих переданным атрибутам:
elements = soup.find_all('a', {'class': 'link'})
Для доступа к содержимому найденных элементов можно использовать различные методы и атрибуты. Например, метод text возвращает текстовое содержимое элемента:
text_content = element.text
Также можно получить атрибуты элемента, используя атрибут attrs:
element_attrs = element.attrs
Если нужно получить данные из таблицы, можно воспользоваться методами find() или find_all() для поиска элементов таблицы, а затем извлекать данные из каждой ячейки таблицы.
Библиотека BeautifulSoup также предоставляет много других возможностей для работы с HTML-кодом. С её помощью можно осуществлять проверку наличия элементов на странице, навигацию по дереву, фильтрацию элементов и многое другое.
В заключение, основные принципы работы с библиотекой BeautifulSoup включают импорт библиотеки, создание объекта BeautifulSoup, поиск нужных элементов и извлечение данных. Это очень полезная и мощная библиотека для автоматического сбора данных с веб-сайтов на языке Python.
Установка и импорт библиотеки
Для сбора данных с веб-сайтов на Python вам потребуется работать с библиотекой BeautifulSoup. Эта библиотека предоставляет удобный и простой способ извлекать информацию из HTML- и XML-разметки.
Прежде чем начать работу с BeautifulSoup, вам необходимо установить его. Для этого вы можете использовать следующую команду в командной строке:
pip install beautifulsoup4
После успешной установки вы можете импортировать библиотеку в свой Python-скрипт:
from bs4 import BeautifulSoup
Теперь, когда вы установили и импортировали библиотеку, вы можете приступить к основам работы с ней для автоматического сбора данных с веб-сайтов.
Парсинг HTML кода с помощью BeautifulSoup
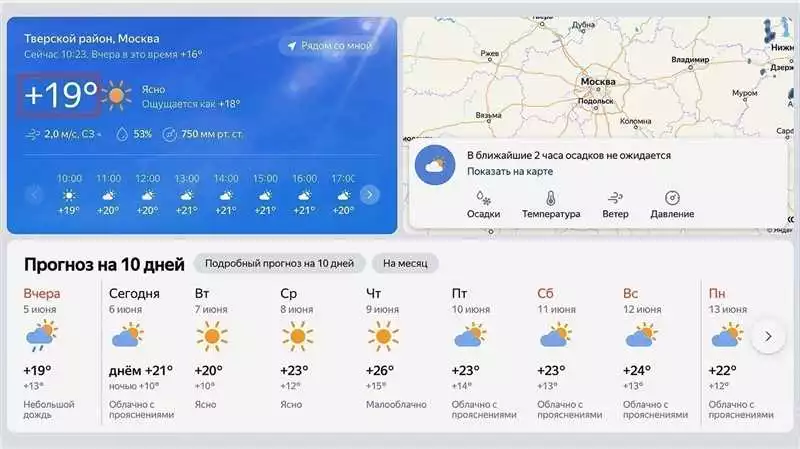
Работа с библиотекой BeautifulSoup – один из основных способов автоматического сбора данных с веб-сайтов на языке программирования Python.
BeautifulSoup – библиотека для разбора HTML и XML документов. Она позволяет эффективно извлекать информацию из веб-страницы и обрабатывать ее. Благодаря своим простым и удобным инструментам, BeautifulSoup стал одним из самых популярных инструментов для парсинга.
Основы работы с библиотекой BeautifulSoup состоят из нескольких шагов:
- Загрузка HTML кода страницы.
- Создание объекта BeautifulSoup для парсинга HTML кода.
- Извлечение нужных данных из HTML кода.
В процессе работы с BeautifulSoup, мы можем использовать различные методы для нахождения нужных элементов HTML документа. Например, мы можем использовать метод find() для поиска первого элемента с указанным тегом, классом или идентификатором. Также, мы можем использовать метод find_all() для поиска всех элементов с указанными тегами, классами или идентификаторами.
Полученные данные можно обрабатывать и использовать в различных сценариях: анализировать, сохранять в базу данных, создавать отчеты и многое другое.
Парсинг HTML кода с помощью BeautifulSoup значительно упрощает автоматический сбор данных с веб-сайтов. Он позволяет получать нужную информацию из страницы без необходимости ручного поиска и обработки данных.
Используя BeautifulSoup, вы сможете собирать данные с любых веб-сайтов и получать нужную информацию в удобном виде.
Базовые навыки работы с библиотекой BeautifulSoup
Библиотека BeautifulSoup является мощным инструментом для автоматического сбора данных с веб-сайтов на языке программирования Python. Она предоставляет удобные возможности для парсинга HTML и XML документов.
Для работы с библиотекой необходимо установить ее на компьютер. Воспользуйтесь командой pip install beautifulsoup4 для установки библиотеки.
Получение доступа к HTML документу осуществляется с помощью функции BeautifulSoup, которая принимает два аргумента: сам HTML документ и парсер, используемый для анализа.
Пример использования:
from bs4 import BeautifulSoup
html_doc = """
<html>
<head>
<title>Пример страницы</title>
</head>
<body>
<h1>Привет, мир!</h1>
<p>Это пример HTML документа.</p>
</body>
</html>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
print(soup.prettify())
В этом примере мы передали HTML документ в переменной html_doc, создали объект BeautifulSoup с помощью функции BeautifulSoup, указав парсер html.parser, и затем вывели отформатированный HTML с помощью метода prettify().
Одна из основных возможностей BeautifulSoup — это поиск элементов на веб-странице с использованием различных методов. Один из таких методов — это метод find(), который позволяет найти первый элемент, соответствующий заданным условиям.
Пример использования:
# Предположим, что у нас есть HTML документ следующего содержания:
html_doc = """
<html>
<head>
<title>Пример страницы</title>
</head>
<body>
<h1>Привет, мир!</h1>
<p>Это пример HTML документа.</p>
<p><a href="https://example.com">Ссылка</a></p>
</body>
</html>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
# Находим первый элемент с тегом h1
element = soup.find('h1')
print(element.text)
Этот код выведет текст элемента с тегом h1, то есть «Привет, мир!».
Кроме метода find() в BeautifulSoup также имеются другие методы поиска, например find_all(), который находит все элементы, соответствующие заданным условиям, и select(), который позволяет использовать CSS-селекторы для поиска элементов.
Помимо поиска элементов, BeautifulSoup также позволяет работать с атрибутами элементов. Например, можно получить значение атрибута href у ссылки с помощью следующего кода:
# Предположим, что у нас есть HTML документ следующего содержания:
html_doc = """
<html>
<head>
<title>Пример страницы</title>
</head>
<body>
<h1>Привет, мир!</h1>
<p>Это пример HTML документа.</p>
<p><a href="https://example.com">Ссылка</a></p>
</body>
</html>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
# Находим первую ссылку
link = soup.find('a')
# Получаем значение атрибута href
href = link.get('href')
print(href)
В этом примере мы находим первую ссылку с помощью метода find(), а затем получаем значение атрибута href с помощью метода get(). Результатом будет «https://example.com».
Кроме того, BeautifulSoup предоставляет возможности для работы с текстом элементов, навигацией по дереву элементов HTML, получения содержимого таблиц и многое другое.
В этой статье были рассмотрены лишь базовые навыки работы с библиотекой BeautifulSoup. Она предоставляет богатый набор инструментов для парсинга и анализа HTML и XML, и ее возможности могут быть использованы в самых различных сферах.
Поиск элементов на веб-странице
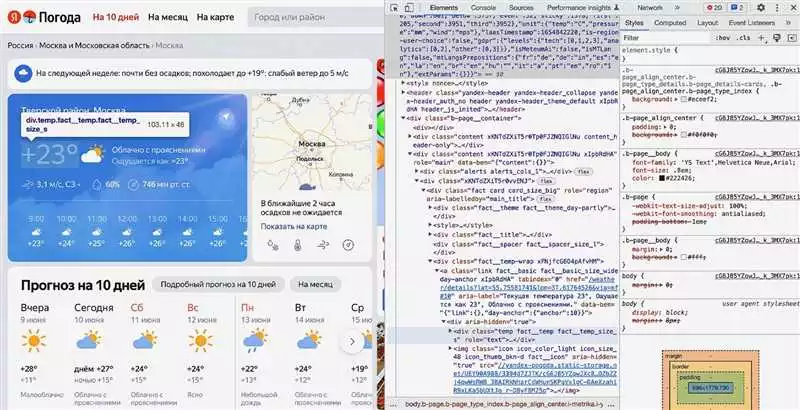
При работе с данными на веб-страницах с использованием библиотеки BeautifulSoup в Python, необходимо уметь находить и извлекать нужные элементы для дальнейшей обработки.
BeautifulSoup предоставляет различные методы для поиска элементов на веб-странице. Некоторые из них:
- find() — ищет первый элемент, соответствующий указанным критериям;
- find_all() — находит все элементы, соответствующие указанным критериям;
- select() — возвращает список элементов, найденных с помощью указанного CSS-селектора.
При использовании этих методов можно указывать различные критерии для поиска, такие как теги, классы, идентификаторы и т.д. Например, чтобы найти все элементы с определенным классом, можно использовать следующий код:
soup.find_all(class_='имя_класса')Также можно использовать комбинированные критерии, чтобы уточнить поиск элементов. Например, чтобы найти все элементы с определенным классом внутри элемента с определенным тегом, можно использовать следующий код:
soup.find_all('тег', class_='имя_класса')После того, как элементы найдены, их можно обрабатывать, получая необходимую информацию или сохраняя данные для дальнейшего использования. Это может быть достигнуто с использованием различных методов и атрибутов, предоставляемых BeautifulSoup.
Например, чтобы получить содержимое найденного элемента, можно использовать атрибут .text или метод .get_text(). Это позволит получить текстовую информацию из найденного элемента.
Также можно использовать атрибуты элемента, чтобы получить значения определенных атрибутов, таких как href, src и т.д.
Пример получения атрибута href элемента:
element['href']Таким образом, при работе с данными на веб-страницах с использованием библиотеки BeautifulSoup в Python, необходимо уметь находить и извлекать нужные элементы, а затем обрабатывать полученные данные для достижения поставленных целей.