Преобразование веб-страниц в структурированные данные является важной задачей для многих веб-разработчиков и исследователей данных. Веб-страницы могут содержать огромное количество информации, и обработка их вручную может быть трудоемким и неэффективным процессом. Однако, благодаря библиотеке BeautifulSoup и языку Python, преобразование веб-страниц в структурированные данные становится гораздо проще и быстрее.

Индивидуальный график
Индивидуальный график
Индивидуальный график
BeautifulSoup — это мощная библиотека для парсинга и анализа HTML и XML документов. Она предоставляет удобные инструменты для извлечения данных из веб-страниц и их преобразования в структурированный формат. Благодаря простому и интуитивному API, BeautifulSoup позволяет с легкостью находить нужные элементы на веб-странице и извлекать из них нужные данные.
Использование Python в сочетании с BeautifulSoup делает процесс преобразования веб-страниц в структурированные данные еще более эффективным. Благодаря богатому функционалу языка Python, можно легко обрабатывать различные типы данных, преобразовывать их и сохранять в нужном формате. Кроме того, наличие множества полезных библиотек и модулей в Python позволяет расширить возможности преобразования данных и упростить их дальнейший анализ и использование.
Преобразование веб-страниц в структурированные данные с помощью BeautifulSoup и Python — это одна из самых эффективных и удобных техник для работы с данными из интернета. Безусловно, использование этих инструментов значительно упрощает и ускоряет процесс извлечения данных и их последующую обработку. Благодаря абстракции и удобству использования, BeautifulSoup и Python стали незаменимыми инструментами в арсенале веб-разработчиков и исследователей данных.
Преобразование веб-страниц в структурированные данные с помощью BeautifulSoup и Python
BeautifulSoup — это библиотека Python, которая позволяет преобразовывать веб-страницы в структурированные данные для дальнейшего анализа и обработки. С его помощью можно извлекать информацию из HTML-кода страницы и преобразовывать ее в удобный для работы формат.
Одним из основных преимуществ BeautifulSoup является его простота использования. Он предоставляет простой и понятный интерфейс для работы с HTML-кодом, позволяя легко находить и извлекать нужные элементы.
Для начала работы с BeautifulSoup необходимо импортировать соответствующий модуль в свой проект:
from bs4 import BeautifulSoup
Затем можно получить HTML-код страницы, например, с помощью модуля requests:
import requests
response = requests.get('https://example.com')
html_code = response.text
Чтобы преобразовать полученный HTML-код в структурированные данные, необходимо создать объект BeautifulSoup и передать ему HTML-код:
soup = BeautifulSoup(html_code, 'html.parser')
Теперь можно использовать объект soup для работы с HTML-кодом страницы. Например, можно найти и извлечь все ссылки на странице:
links = soup.find_all('a')
for link in links:
print(link.get('href'))
Также с помощью BeautifulSoup можно легко найти и извлечь другие элементы страницы, такие как заголовки, тексты, изображения и т.д.:
titles = soup.find_all('h1')
for title in titles:
print(title.text)
Полученные данные можно дальше обработать и сохранить в нужном формате, например, в базу данных или в файл CSV.
Таким образом, с использованием BeautifulSoup и Python можно преобразовывать веб-страницы в структурированные данные, что позволяет легко и удобно анализировать и обрабатывать информацию на веб-страницах.
Работа с библиотекой BeautifulSoup

Для работы с веб-страницами и получения структурированных данных в формате HTML с помощью Python существует множество инструментов и библиотек. Однако одной из самых популярных и удобных является библиотека BeautifulSoup.
BeautifulSoup позволяет извлекать данные из HTML-кода веб-страницы и манипулировать ими с помощью удобного и интуитивно понятного API. Благодаря этому, с помощью BeautifulSoup можно осуществлять парсинг веб-страниц и извлекать необходимую информацию.
Для начала работы с BeautifulSoup необходимо установить его с помощью пакетного менеджера pip:
- Откройте командную строку.
- Введите команду pip install beautifulsoup4 и нажмите Enter.
После установки библиотеки можно начинать работу. Для этого необходимо использовать следующий код:
from bs4 import BeautifulSoup
# Открываем файл с HTML-кодом веб-страницы
with open('webpage.html', 'r') as f:
html_code = f.read()
# Создаем объект BeautifulSoup и передаем в него HTML-код страницы
soup = BeautifulSoup(html_code, 'html.parser')
# Парсим страницу и получаем необходимые данные, например, заголовки статей или ссылки
headings = soup.find_all('h1')
links = soup.find_all('a')
print(headings)
print(links)
В данном примере мы открываем файл ‘webpage.html’, содержащий HTML-код веб-страницы, с помощью функции open() и метода read() получаем его содержимое. Затем создаем объект BeautifulSoup, передаем в него HTML-код и указываем парсер html.parser.
После этого мы можем использовать различные методы и функции BeautifulSoup для поиска и извлечения нужной информации. Например, метод find_all() позволяет найти все элементы на странице по заданному тегу, метод get_text() позволяет получить текстовое содержимое элемента, метод get() позволяет получить значение атрибута элемента и т.д.
Для удобства работы с данными, полученными с помощью BeautifulSoup, их можно сохранить в структурированном виде, например, в формате JSON или CSV.
Таким образом, работа с библиотекой BeautifulSoup в Python позволяет удобно и эффективно извлекать и обрабатывать данные с веб-страниц, делая их структурированными и готовыми для дальнейшего анализа.
Установка и настройка BeautifulSoup

Для структурирования данных на веб-страницах с использованием Python существует мощная библиотека BeautifulSoup. Она позволяет легко преобразовывать HTML-код в удобный для обработки формат.
Для начала необходимо установить BeautifulSoup. Для этого можно воспользоваться менеджером пакетов pip, запустив команду:
$ pip install beautifulsoup4
После успешной установки библиотеки, она готова к использованию. Теперь можно начинать работу над преобразованием веб-страниц в структурированные данные.
Для начала необходимо импортировать библиотеку BeautifulSoup в свой Python-скрипт:
from bs4 import BeautifulSoup
Теперь можно использовать функционал библиотеки BeautifulSoup для анализа и преобразования HTML-кода. Для этого необходимо создать объект BeautifulSoup, передав в конструктор анализируемую веб-страницу:
soup = BeautifulSoup(html, 'html.parser')
Функция BeautifulSoup принимает два аргумента — HTML-код в виде строки и метод анализа, в данном случае ‘html.parser’. Второй аргумент необходим, чтобы BeautifulSoup определил, каким образом обрабатывать входные данные.
Теперь структурированные данные веб-страницы доступны через объект soup. Можно получать информацию, изменять и преобразовывать ее в необходимый формат.
Используя библиотеку BeautifulSoup, можно значительно упростить процесс преобразования веб-страниц в удобный для обработки формат. Благодаря этому инструменту Python-разработчики получают возможность более эффективно работать с данными, представленными на веб-страницах.
Примеры работы со структурированными данными веб-страниц с помощью BeautifulSoup:
- Нахождение элементов на странице и извлечение содержимого.
- Изменение содержимого элементов.
- Фильтрация элементов по атрибутам.
- Навигация по структурированным данным.
- Извлечение данных из таблиц.
Рассмотрение каждого из этих пунктов позволит более глубоко понять возможности и сильные стороны библиотеки BeautifulSoup.
Примеры использования BeautifulSoup для парсинга веб-страниц
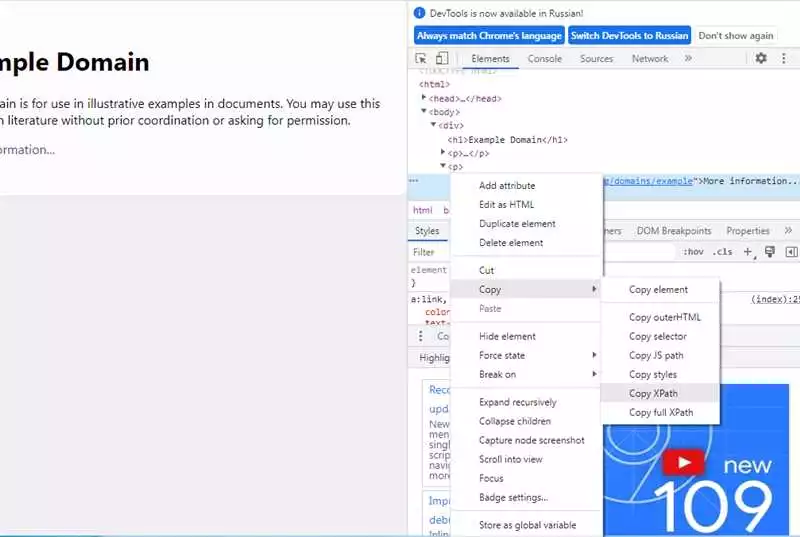
С помощью библиотеки BeautifulSoup в Python можно легко преобразовывать веб-страницы в структурированные данные. В данном разделе представлены несколько примеров использования BeautifulSoup для парсинга веб-страниц.
1. Получение текстового контента из HTML-элемента
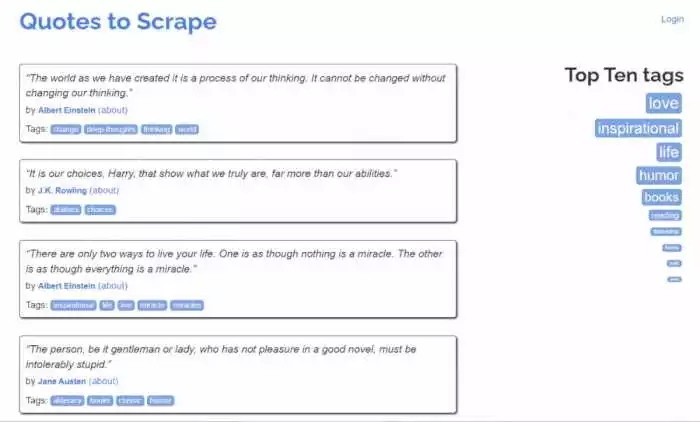
Для получения текстового содержимого из HTML-элемента используется метод get_text(). Этот метод извлекает все текстовые данные из HTML-элемента, включая все вложенные элементы.
from bs4 import BeautifulSoup
# HTML-код страницы
html = """
<html>
<body>
<h1>Привет, мир!</h1>
<p>Это пример использования BeautifulSoup.</p>
</body>
</html>
"""
# Создание объекта BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
# Извлечение текстового содержимого из тега <p>
content = soup.find('p').get_text()
print(content)
# Вывод: "Это пример использования BeautifulSoup."
2. Извлечение данных из списка
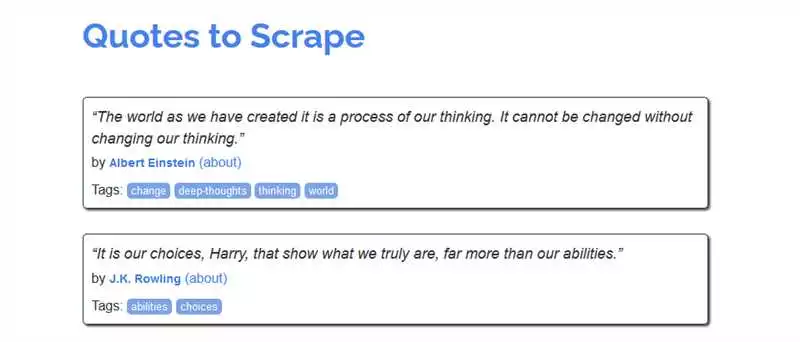
Для извлечения данных из списка можно использовать методы find_all() и find(). Метод find_all() возвращает все элементы списка, удовлетворяющие заданным критериям, а метод find() возвращает первый элемент списка, удовлетворяющий критериям.
from bs4 import BeautifulSoup
# HTML-код списка
html = """
<ul>
<li>Пункт 1</li>
<li>Пункт 2</li>
<li>Пункт 3</li>
</ul>
"""
# Создание объекта BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
# Извлечение всех элементов списка
items = soup.find_all('li')
for item in items:
print(item.get_text())
# Вывод:
# "Пункт 1"
# "Пункт 2"
# "Пункт 3"
3. Извлечение данных из таблицы
Для извлечения данных из таблицы можно использовать методы find_all() и find(), а также методы для работы со строками и столбцами таблицы.
from bs4 import BeautifulSoup
# HTML-код таблицы
html = """
<table>
<tr>
<th>Заголовок 1</th>
<th>Заголовок 2</th>
</tr>
<tr>
<td>Ячейка 1</td>
<td>Ячейка 2</td>
</tr>
<tr>
<td>Ячейка 3</td>
<td>Ячейка 4</td>
</tr>
</table>
"""
# Создание объекта BeautifulSoup
soup = BeautifulSoup(html, 'html.parser')
# Извлечение всех ячеек таблицы
rows = soup.find_all('tr')
for row in rows:
cells = row.find_all('td')
for cell in cells:
print(cell.get_text())
print('---')
# Вывод:
# "Ячейка 1"
# "Ячейка 2"
# "---"
# "Ячейка 3"
# "Ячейка 4"
# "---"
Таким образом, с помощью библиотеки BeautifulSoup в Python можно легко преобразовывать веб-страницы в структурированные данные и извлекать необходимую информацию.
Автоматизация задач на Python

Автоматизация задач на Python — это процесс использования программных возможностей Python для выполнения повторяющихся действий и обработки данных.
Одной из основных задач, которые могут быть автоматизированы с помощью Python, является преобразование веб-страниц в структурированные данные. Для этой задачи может быть использован модуль BeautifulSoup, который предоставляет инструменты для анализа и извлечения данных из HTML и XML.
Python обеспечивает широкие возможности для работы с данными, включая чтение и запись файлов, манипуляции с базами данных, парсинг и обработку текста и другие операции. Благодаря этим возможностям, Python становится мощным инструментом для автоматизации задач, связанных с обработкой данных и веб-страниц.
Преобразование веб-страниц в структурированные данные может быть полезно во многих сферах деятельности. Например, это может быть использовано для сбора информации с веб-сайтов, составления отчетов, мониторинга изменений на веб-страницах и других задач.
Преимущества автоматизации задач на Python включают увеличение производительности за счет ускорения выполнения задач и устранения человеческого фактора, улучшение точности благодаря автоматической обработке данных и снижение риска ошибок, а также упрощение и улучшение работы с данными для повторяющихся задач.
В итоге, автоматизация задач на Python с использованием BeautifulSoup и других инструментов может значительно упростить и ускорить рабочий процесс, а также помочь получить более точные и структурированные данные.