Если вам когда-либо приходилось работать с веб-страницами, вероятно, вам приходилось сталкиваться с задачей извлечения данных. Независимо от того, нужно ли вам спарсить новости с сайта, собрать информацию для анализа или просто извлечь определенные элементы из HTML-кода, на помощь приходит библиотека BeautifulSoup.

Индивидуальный график
Индивидуальный график
Индивидуальный график
BeautifulSoup — это инструмент, который облегчает парсинг и извлечение данных из HTML или XML файлов. Он предоставляет простой способ найти и извлечь информацию из структурированных данных, не требуя написания многословного и неуклюжего кода.
В этом пошаговом руководстве мы рассмотрим основы использования BeautifulSoup для извлечения данных из HTML-кода. Мы покажем, как установить BeautifulSoup, как использовать его для парсинга веб-страницы и как найти, извлечь и обработать нужные нам данные.
Как использовать BeautifulSoup для извлечения данных из HTML-кода: пошаговое руководство
BeautifulSoup является одной из самых популярных библиотек Python для парсинга HTML-кода. С его помощью можно очень просто извлекать данные, такие как текст, ссылки, таблицы и многое другое, из HTML-кода.
В этом пошаговом руководстве мы рассмотрим, как использовать BeautifulSoup для извлечения данных из HTML-кода. Вот инструкция:
- Установите BeautifulSoup, если у вас его еще нет. Откройте командную строку и выполните команду
pip install beautifulsoup4. - Импортируйте BeautifulSoup в свой код:
from bs4 import BeautifulSoup. - Прочитайте HTML-код из файла или получите его с помощью запроса к веб-странице.
- Создайте объект BeautifulSoup, передав HTML-код и указав парсер. Например:
soup = BeautifulSoup(html, 'html.parser'). - Используйте методы и атрибуты BeautifulSoup для извлечения нужных данных. Например, для извлечения текста из тега
<p>, используйтеsoup.find('p').text. - Повторяйте шаги 5 и 6, чтобы извлечь все необходимые данные.
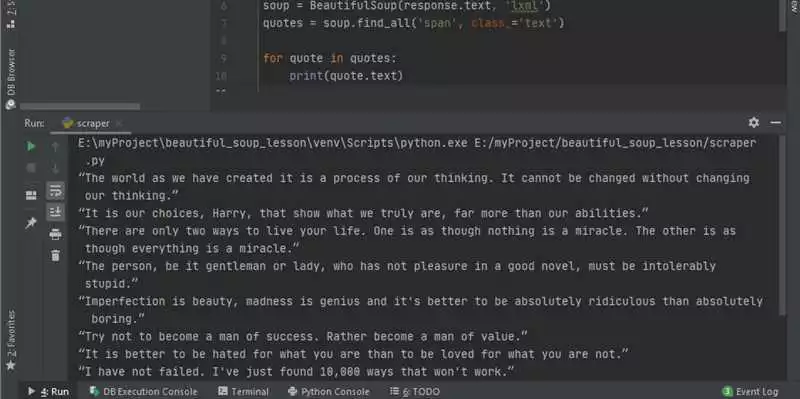
Пример использования BeautifulSoup для извлечения ссылок из HTML-кода:
from bs4 import BeautifulSoup
html = '''
<html>
<body>
<a href="https://example.com">Ссылка 1</a>
<a href="https://example.com">Ссылка 2</a>
<a href="https://example.com">Ссылка 3</a>
</body>
</html>
'''
soup = BeautifulSoup(html, 'html.parser')
links = soup.find_all('a')
for link in links:
print(link['href'])
Этот код найдет все теги <a> в HTML-коде и выведет значения атрибута href для каждой ссылки.
Таким образом, BeautifulSoup облегчает процесс извлечения данных из HTML-кода и предоставляет удобные методы для работы с ними. Используйте данное руководство, чтобы начать использование BeautifulSoup и извлекать нужные данные из HTML-кода.
Работа с библиотекой BeautifulSoup working-with-the-beautifulsoup-library
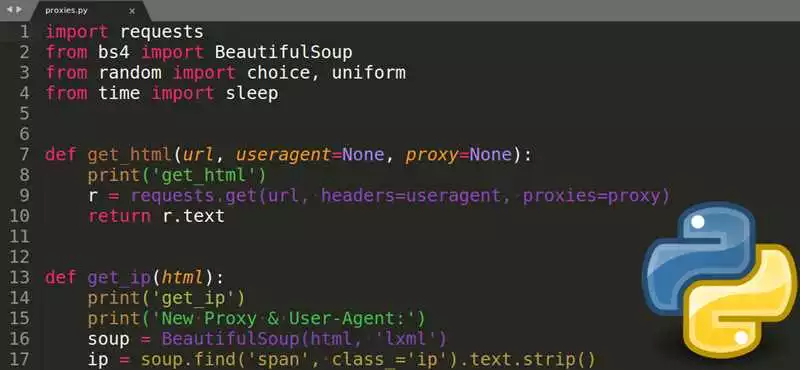
В этом руководстве мы рассмотрим использование библиотеки BeautifulSoup для извлечения данных из HTML-кода. BeautifulSoup — это популярная библиотека для парсинга и обработки HTML-кода. Она предоставляет удобные инструменты для поиска, извлечения и манипулирования данными в HTML-структурах. Это отличная инструкция для тех, кто хочет научиться работать с HTML-кодом и извлекать информацию из веб-страниц.
Чтобы начать работу с BeautifulSoup, первым шагом является установка библиотеки. Для этого можно использовать менеджер пакетов pip. Откройте командную строку и выполните следующую команду:
pip install beautifulsoup4
После установки библиотеки мы можем начать процесс извлечения данных из HTML-кода. Вот основные шаги, которые вам нужно выполнить:
- Загрузите HTML-код:
html = "Это пример HTML-кода.
"
- Импортируйте библиотеку BeautifulSoup:
from bs4 import BeautifulSoup - Создайте объект BeautifulSoup:
soup = BeautifulSoup(html, 'html.parser') - Используйте методы и атрибуты BeautifulSoup для извлечения необходимых данных.
BeautifulSoup предоставляет различные методы и атрибуты для поиска и извлечения данных. Например, чтобы найти и получить содержимое тега <h1>, вы можете использовать следующий код:
soup.find('h1').textЭтот код найдет первый тег <h1> в HTML-коде и вернет его содержимое.
Вы также можете использовать методы поиска, такие как find_all, чтобы найти все теги с определенным именем или атрибутом. Например, следующий код найдет все теги <p> в HTML-коде:
soup.find_all('p')Используя BeautifulSoup, вы можете выполнять множество операций с HTML-кодом, включая поиск элементов по их классам, атрибутам, нахождение дочерних элементов и многое другое.
В заключение можно сказать, что использование BeautifulSoup для извлечения данных из HTML-кода — это мощный инструмент, который может быть использован для анализа и обработки информации на веб-страницах. Он позволяет легко находить и извлекать данные, делая процесс автоматизированным и эффективным.
Установка BeautifulSoup и его зависимостей
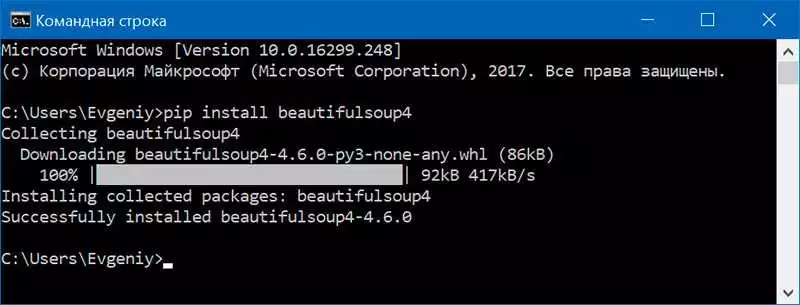
BeautifulSoup — это мощная библиотека пайтон для парсинга HTML-кода и извлечения данных. В этом руководстве мы рассмотрим инструкцию по установке и использованию этой библиотеки.
Первым шагом является установка BeautifulSoup и его зависимостей. Для этого мы можем воспользоваться менеджером пакетов пайтон — pip. Откройте командную строку и введите следующую команду:
pip install beautifulsoup4
Эта команда установит саму библиотеку BeautifulSoup. Однако, у BeautifulSoup есть зависимость, которая также должна быть установлена. Это библиотека lxml, которая используется BeautifulSoup для обработки и разбора HTML-кода.
Для установки lxml выполните следующую команду:
pip install lxml
После успешной установки BeautifulSoup и его зависимостей, мы готовы начать использование этой библиотеки для парсинга HTML-кода и извлечения данных.
Подключение и инициализация BeautifulSoup
BeautifulSoup — это библиотека Python, которая позволяет выполнять пошаговое извлечение данных из HTML-кода. В этом руководстве мы рассмотрим пошаговую инструкцию по использованию BeautifulSoup для парсинга HTML-кода и извлечения данных.
Для начала, вам нужно установить библиотеку BeautifulSoup, если ее нет. Для этого вы можете использовать pip, выполнив следующую команду:
pip install beautifulsoup4
После установки библиотеки BeautifulSoup вы можете начать использовать ее в своем коде. Подключите библиотеку, добавив следующий import в верхней части своего файла Python:
from bs4 import BeautifulSoup
Теперь вы можете инициализировать объект BeautifulSoup, передавая ему HTML-код для парсинга. Вы можете передать HTML-код, сохраненный в переменной, или прочитать его непосредственно из файла.
Вот пример инициализации BeautifulSoup с HTML-кодом, сохраненным в переменной:
html_code = "<html><body><p>Пример HTML-кода</p></body></html>"
soup = BeautifulSoup(html_code, 'html.parser')
Вы также можете инициализировать BeautifulSoup, прочитав HTML-код из файла:
with open('file.html', 'r') as file:
soup = BeautifulSoup(file, 'html.parser')
Теперь вы готовы использовать объект BeautifulSoup для извлечения данных из HTML-кода. Пройдите по документации BeautifulSoup, чтобы узнать больше о доступных методах и функциях для различных видов парсинга и извлечения данных.