Искусственный интеллект (ИИ) является одним из наиболее активно развивающихся направлений в области компьютерных наук. Он представляет собой область, в которой компьютерные системы и алгоритмы моделируют и симулируют различные аспекты человеческого интеллекта. Использование технологий и методов искусственного интеллекта становится все более распространенным во многих сферах, включая бизнес, медицину, финансы и многое другое.

Индивидуальный график
Индивидуальный график
Индивидуальный график
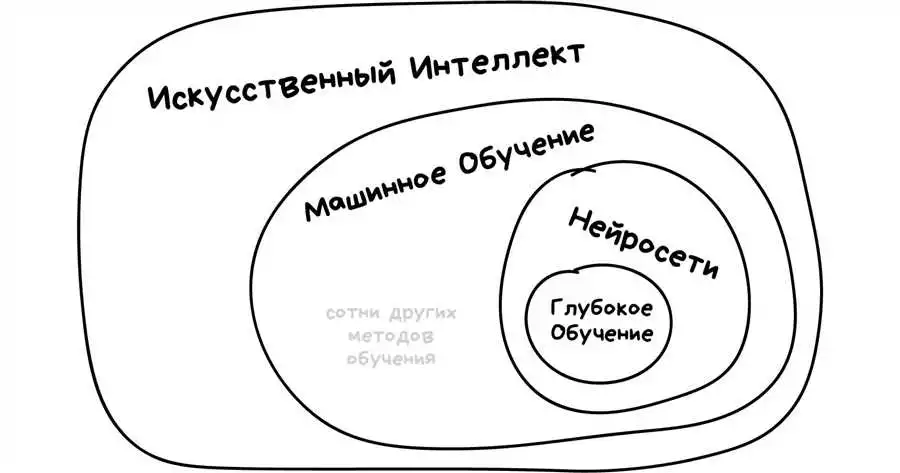
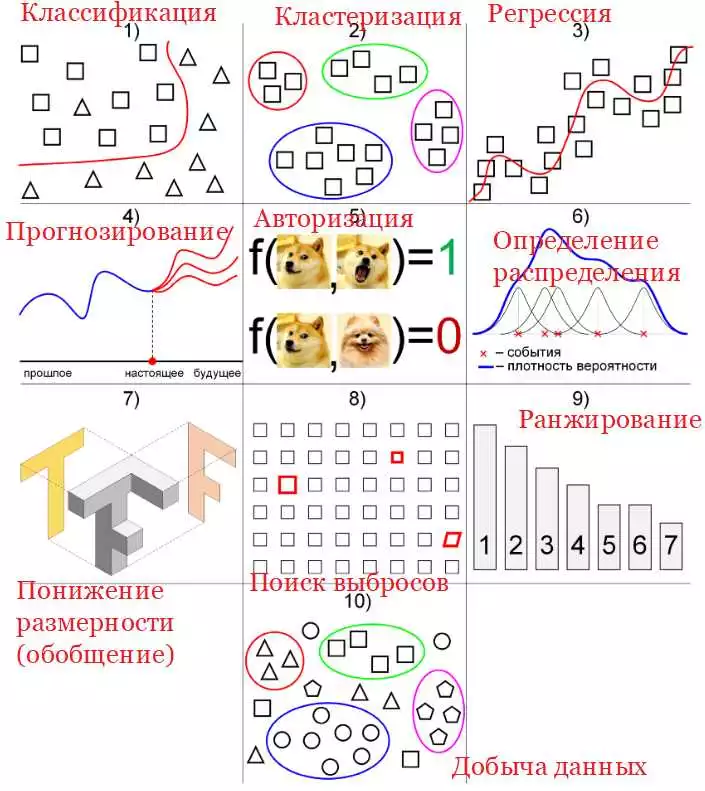
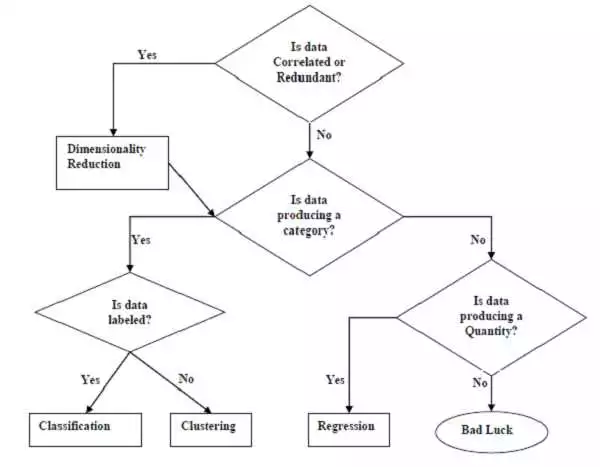
Одной из ключевых задач в области искусственного интеллекта является классификация и кластеризация данных. Классификация относит обьекты к одной или нескольким заданным категориям, в то время как кластеризация группирует объекты схожего типа в отдельные классы. Проблема классификации и кластеризации данных является неразрешимой в реальных условиях без использования специальных алгоритмов и методов.
Python — один из наиболее популярных языков программирования для решения задач искусственного интеллекта. Он предоставляет широкий спектр библиотек и инструментов, которые упрощают и ускоряют процесс обучения и использования алгоритмов машинного обучения и классификации. Python стал практически стандартным языком для программирования задач, связанных с искусственным интеллектом и машинным обучением.
Python и искусственный интеллект: решение задач классификации и кластеризации
Искусственный интеллект (ИИ) – это область компьютерной науки, которая занимается созданием интеллектуальных систем, способных обучаться и принимать решения на основе накопленных знаний.
Одной из самых распространенных задач в области искусственного интеллекта является классификация объектов и группировка их по определенным признакам. В этом контексте Python стал одним из наиболее популярных языков программирования.
Проблемы и способы их решения
Одной из проблем при решении задач классификации и кластеризации является огромное количество данных, с которыми нужно работать. Для этого необходимы эффективные алгоритмы и методы, которые могут быть реализованы с использованием Python.
Python предоставляет различные библиотеки и инструменты для решения задач классификации и кластеризации. Одной из таких библиотек является scikit-learn, которая позволяет реализовать различные алгоритмы машинного обучения.
Методы классификации

Основные методы классификации включают в себя:
- Логистическая регрессия
- Метод опорных векторов (SVM)
- Решающие деревья
- Случайный лес
- Нейронные сети
Методы кластеризации
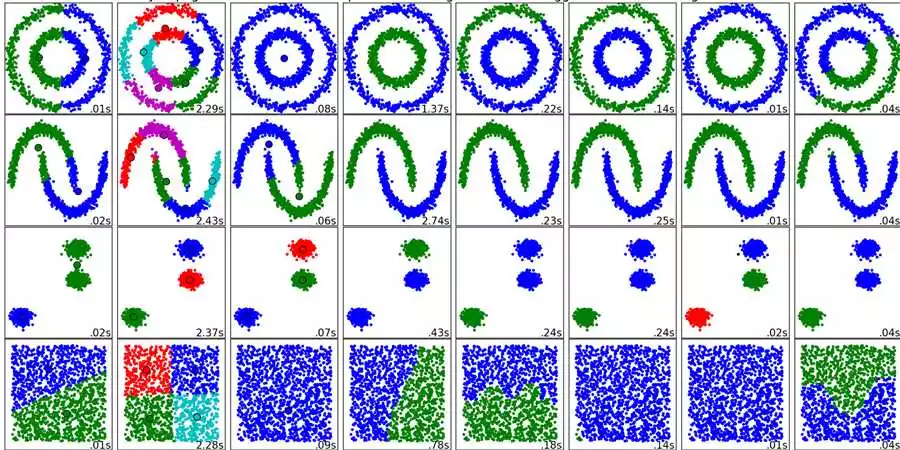
Методы кластеризации позволяют группировать объекты похожих характеристик. В Python доступны следующие методы кластеризации:
- k-средних
- DBSCAN
- Иерархическая кластеризация
- Агломеративная кластеризация
Обучение и использование моделей с помощью Python
В Python доступны различные методы обучения моделей и их использования для классификации и кластеризации данных. С помощью библиотеки scikit-learn можно реализовать следующие шаги:
- Подготовка данных: предварительная обработка, нормализация и преобразование данных.
- Выбор модели и ее параметров.
- Обучение модели на тренировочных данных.
- Оценка модели с использованием метрик качества.
- Применение модели для предсказания и/или кластеризации новых данных.
Python позволяет легко написать и отладить код для решения задач классификации и кластеризации, а также предоставляет удобные инструменты для визуализации результатов.
Искусственный интеллект в Python
Использование Python для решения задач классификации и кластеризации с использованием искусственного интеллекта стало широко распространено. Python предоставляет обширный функционал для работы с данными, машинным обучением и глубоким обучением.
Изучение и программирование с использованием Python позволяют эффективно решать задачи классификации и кластеризации в области искусственного интеллекта. Большое количество библиотек и инструментов позволяют легко реализовывать различные алгоритмы и методы.
Python и искусственный интеллект идеально сочетаются для решения задач классификации и кластеризации, и продолжают играть важную роль в развитии и применении искусственного интеллекта в различных сферах.
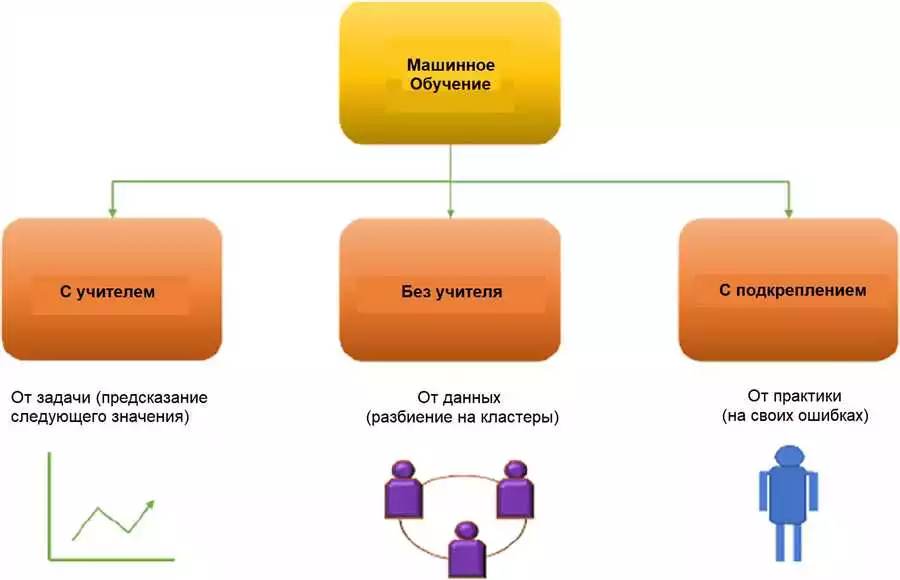
Алгоритмы машинного обучения для решения задач классификации
Искусственный интеллект (AI) стал неотъемлемой частью нашей жизни, и для решения различных задач категоризации и классификации AI использует машинное обучение. В этой статье рассмотрим некоторые из алгоритмов и методов, которые можно использовать для решения задач классификации с использованием языка программирования Python.
Одной из основных проблем в задачах классификации является группировка данных по различным категориям. Алгоритмы машинного обучения помогают автоматически определить классы или категории данных на основе предоставленных обучающих примеров.
Python предлагает различные способы программирования для изучения и решения задач классификации. Некоторые из популярных алгоритмов и методов, которые можно использовать, включают:
- Наивный Байесовский классификатор
- Логистическая регрессия
- Метод k-ближайших соседей
- Метод опорных векторов
- Деревья принятия решений
- Случайные леса
Каждый из этих алгоритмов имеет свои особенности и подходит для разных типов задач классификации. Они используются для обучения моделей на основе предоставленных данных и последующего классифицирования неизвестных данных.
Один из наиболее распространенных способов классификации в машинном обучении — это использование нейронных сетей. Нейронные сети состоят из искусственных нейронов, которые имитируют работу нервной системы человека. Они могут обрабатывать большие объемы данных и использоваться для решения сложных задач классификации.
Python предлагает богатые библиотеки и инструменты, такие как TensorFlow и PyTorch, для обучения и развертывания нейронных сетей. С их помощью можно создавать и настраивать различные архитектуры нейронных сетей для решения сложных задач классификации.
В заключение, алгоритмы машинного обучения являются мощным инструментом для решения задач классификации с помощью Python и искусственного интеллекта. Изучение и использование этих алгоритмов позволяет создавать эффективные модели для классификации данных и получать точные результаты в различных областях: от медицины до банковского дела.
Процесс классификации в машинном обучении

Классификация является одним из основных методов машинного обучения и искусственного интеллекта. Ее главной задачей является разделение объектов на заранее определенные категории. Данные категории могут быть представлены числами, метками или названиями. В процессе классификации используются методы и алгоритмы, которые позволяют классифицировать объекты на основе имеющихся данных.
Классификация играет важную роль в решении различных задач, таких как анализ текстов, распознавание изображений, определение категории покупателей и многих других. Python — это один из наиболее популярных языков программирования для работы с искусственным интеллектом и машинным обучением.
Процесс классификации с использованием Python искусственного интеллекта включает в себя следующие шаги:
- Сбор данных: в этом шаге происходит сбор данных, которые будут использоваться для обучения алгоритма классификации.
- Подготовка данных: данные, собранные на предыдущем шаге, требуют предварительной обработки и преобразования для того, чтобы они могли быть использованы алгоритмами классификации.
- Выбор модели: на этом этапе выбирается модель классификации, которая будет использоваться для решения задачи классификации. В Python существует множество библиотек и алгоритмов, которые могут быть использованы для этой цели.
- Обучение модели: на этом этапе выбранная модель обучается на собранных и подготовленных данных. Для обучения модели используются различные методы и алгоритмы.
- Тестирование модели: после завершения обучения модели она тестируется на новых данных, чтобы проверить ее точность и эффективность. В Python существуют методы для тестирования модели и оценки ее качества.
Важной задачей классификации в машинном обучении является также кластеризация. Кластеризация заключается в группировке объектов в кластеры на основе их сходства. Задача кластеризации в машинном обучении решается с помощью различных методов и алгоритмов, которые позволяют определить наиболее оптимальное разбиение объектов на кластеры. Python предлагает различные способы и методы для решения задач кластеризации с использованием искусственного интеллекта и машинного обучения.
Популярные алгоритмы классификации в Python

В машинном обучении с использованием искусственного интеллекта (ИИ) существуют различные способы решения задач классификации и кластеризации. Python — это мощный язык программирования, который предлагает множество инструментов и библиотек для решения этих проблем.
Рассмотрение популярных алгоритмов классификации в Python позволяет углубиться в изучение ИИ и искусственного интеллекта. Эти алгоритмы предлагают различные методы и техники для категоризации данных и решения задач классификации и кластеризации.
Ниже приведены некоторые из популярных алгоритмов классификации в Python:
-
Метод k-ближайших соседей (k-NN): Этот алгоритм использует данные об объектах, чтобы определить класс нового объекта. Он основывается на том, что объекты одного и того же класса обычно находятся близко друг к другу в пространстве признаков.
-
Логистическая регрессия: Этот алгоритм используется для бинарной (двухклассовой) и многоклассовой классификации. Он предсказывает вероятности принадлежности объекта к каждому классу.
-
Метод опорных векторов (SVM): Этот алгоритм строит гиперплоскость в пространстве признаков, которая разделяет объекты разных классов. Он находит оптимальную гиперплоскость, максимизирующую зазор между классами.
-
Случайный лес: Этот алгоритм комбинирует несколько решающих деревьев для решения задач классификации. Каждое дерево в лесу голосует за принадлежность объекта к определенному классу, и класс с наибольшим количеством голосов становится предсказанным классом.
-
Нейронные сети: Этот алгоритм имитирует работу нервной системы человека и используется для решения сложных задач классификации. Он состоит из множества взаимосвязанных нейронов, которые могут обучаться на основе данных.
Это лишь некоторые из алгоритмов классификации, доступных в Python. Каждый из них имеет свои преимущества и недостатки, и выбор алгоритма зависит от конкретной задачи и данных. Python предлагает богатый набор инструментов для работы с алгоритмами классификации и кластеризации, что делает его популярным языком для решения задач машинного обучения и искусственного интеллекта.
Алгоритмы машинного обучения для решения задач кластеризации
Кластеризация — один из важных способов категоризации данных. С помощью алгоритмов машинного обучения и искусственного интеллекта (ИИ) можно группировать данные в кластеры на основе их сходства. Рассмотрим некоторые методы машинного обучения для решения задач кластеризации с использованием Python:
- K-Means: один из самых популярных алгоритмов кластеризации. Он разбивает данные на кластеры, где каждый кластер представляет собой набор точек, близких по схожести между собой. K-Means позволяет задать количество кластеров, алгоритм итеративно переназначает точки кластерам и обновляет их центроиды.
- DBSCAN: алгоритм, основывающийся на плотности данных. Он автоматически определяет количество кластеров и выявляет выбросы. DBSCAN группирует точки, находящиеся внутри плотных областей, и помечает точки, находящиеся в разреженных областях, как выбросы.
- Hierarchical Clustering: алгоритм, основывающийся на иерархической группировке данных. Он строит дерево кластеров, где каждый узел представляет собой кластер, а ребра — объединение кластеров. Метод может быть агломеративным (снизу вверх) или дивизионным (сверху вниз).
Каждый из этих алгоритмов имеет свои преимущества и недостатки, и выбор подходящего метода зависит от исследуемых данных и требований решаемой задачи.
Проблемы, связанные с кластеризацией, включают сложность выбора оптимального числа кластеров, выбор подходящей метрики расстояния и обработку выбросов. Для решения этих проблем можно использовать различные методы, такие как оценка силуэта, индексы качества кластеризации и методы обработки выбросов.
Использование Python для решения задач кластеризации позволяет упростить процесс программирования и изучение алгоритмов машинного обучения. Python имеет богатую экосистему библиотек для машинного обучения, таких как scikit-learn, tensorflow и keras, которые предоставляют готовые реализации алгоритмов кластеризации и инструменты для анализа и визуализации данных.
| import | numpy | as | np |
|---|---|---|---|
| from | sklearn.cluster | import | KMeans |
| X | = | np.array([[1, 2], [1, 4], [1, 0], [4, 2], [4, 4], [4, 0]]) | |
| kmeans | = | KMeans(n_clusters=2) | |
| kmeans.fit(X) | |||
| labels | = | kmeans.labels_ |
В данном примере мы импортируем необходимые модули, создаем массив данных X, создаем объект KMeans с параметром n_clusters=2, вызываем метод fit для обучения модели и получаем метки кластеров. Это только небольшая часть функционала доступного в Python для решения задач кластеризации.
Алгоритмы машинного обучения для решения задач кластеризации вместе с Python предоставляют мощный инструмент для анализа данных и поиска скрытых закономерностей. Изучение и применение этих методов позволяет эффективно решать задачи кластеризации и получать ценные знания из данных.
Процесс кластеризации в машинном обучении

Кластеризация — это метод изучения данных в машинном обучении, который занимается группировкой объектов в подобные категории. Кластеризация используется для решения различных задач, таких как классификация и категоризация данных.
Прежде чем рассмотреть процесс кластеризации, важно понять, что такое искусственный интеллект (ИИ) и машинное обучение (МО). Искусственный интеллект — это область компьютерных наук, которая занимается созданием систем, способных исполнять задачи, требующие интеллекта. Машинное обучение — это подраздел искусственного интеллекта, который фокусируется на разработке алгоритмов для автоматического извлечения полезной информации из данных.
Процесс кластеризации включает в себя следующие шаги:
- Подготовка данных: В этом шаге данные очищаются и преобразуются в удобный формат для алгоритма кластеризации. Это включает в себя удаление выбросов и обработку пропущенных значений.
- Выбор метода кластеризации: В этом шаге выбирается подходящий метод кластеризации для решения конкретной задачи. Существует множество методов кластеризации, таких как иерархическая кластеризация, k-средних и DBSCAN.
- Применение алгоритма кластеризации: В этом шаге выбранный метод кластеризации применяется к данным, и объекты группируются в кластеры на основе их сходства.
- Оценка результатов: В этом шаге оценивается качество полученного решения кластеризации. Это может включать в себя вычисление метрик, таких как силуэт, и визуализацию кластеров.
- Интерпретация результатов: В этом шаге результаты кластеризации анализируются и интерпретируются с целью получения новых знаний или принятия решений.
Кластеризация является мощным инструментом для решения различных проблем, таких как обнаружение аномалий, сегментация пользователей и анализ социальных сетей. Важно выбрать подходящий метод кластеризации и правильно настроить его параметры для получения хороших результатов.
Python, с его обширными библиотеками для машинного обучения, такими как scikit-learn и tensorflow, является популярным языком программирования для решения задач кластеризации. С его использованием можно легко реализовать различные методы кластеризации и провести анализ данных.
В заключение, процесс кластеризации в машинном обучении представляет собой последовательность шагов для решения задач группировки данных. Выбор подходящего метода кластеризации, обработка данных и оценка результатов — ключевые компоненты успешного решения задачи кластеризации.
Популярные алгоритмы кластеризации в Python
Кластеризация — это метод машинного обучения, с помощью которого можно группировать данные по их схожим характеристикам. В области искусственного интеллекта существует множество методов и алгоритмов кластеризации, которые позволяют решать различные проблемы.
Python — это изучение мощный язык программирования, который предоставляет богатый набор инструментов для работы с искусственным интеллектом и машинным обучением. С использованием Python можно легко решать задачи классификации и кластеризации с помощью различных алгоритмов и методов.
Ниже рассмотрены некоторые популярные алгоритмы кластеризации в Python:
- K-means: один из самых популярных алгоритмов кластеризации. Он работает по принципу группировки данных в заданное количество кластеров, минимизируя сумму квадратов расстояний между центроидами кластеров и точками данных.
- DBSCAN: алгоритм, основанный на плотности данных. Он автоматически определяет количество кластеров и группирует точки данных на основе их плотности.
- Hierarchical clustering: метод иерархической кластеризации, который строит иерархическое дерево кластеров. Он может быть агломеративным (снизу вверх) или дивизивным (сверху вниз).
- Mean-Shift: алгоритм, который находит пики плотности данных и определяет кластеры, исходя из этих пиков. Он может быть использован для кластеризации данных с неизвестным количеством кластеров.
Это только некоторые из способов кластеризации данных с использованием Python. Обучение классификации и кластеризации данных является важной задачей в искусственном интеллекте и машинном обучении. Python предоставляет богатый набор инструментов и библиотек, таких как scikit-learn и TensorFlow, которые упрощают процесс анализа данных и кластеризации.