Машинное обучение — это важный подход, который позволяет программам «обучаться» на основе данных и опыта, а не явно программироваться для решения конкретных задач. Основополагающими методами машинного обучения являются классификация и регрессия.

Индивидуальный график
Индивидуальный график
Индивидуальный график
Классификация — это процесс отнесения объектов к одному из нескольких заранее определенных классов. Ведущими алгоритмами классификации являются метод опорных векторов (SVM), наивный Байесовский классификатор и деревья решений.
Регрессия, в свою очередь, позволяет решать задачи предсказания числовых значений на основе имеющихся данных. Для этого применяются алгоритмы линейной регрессии, регрессионные деревья и нейронные сети.
Помимо базовых алгоритмов обучения с учителем, существуют также методы обучения без учителя, которые не требуют использования размеченных данных. Эти методы основаны на выявлении скрытых закономерностей в данных и на поиске группировок или шаблонов. Популярными алгоритмами обучения без учителя являются кластеризация, снижение размерности и ассоциативные правила.
Основные алгоритмы машинного обучения на Python предлагают различные подходы и стратегии для решения задач. Использование этих алгоритмов становится все более распространенным в различных сферах, включая обработку естественного языка, компьютерное зрение, медицину и финансы.
Основные алгоритмы машинного обучения на Python: виды и применение
Машинное обучение — это базовые методы, стратегии и алгоритмы, которые позволяют компьютерной программе приобретать опыт и улучшать свою производительность без явного программирования.
Существуют две основные разновидности алгоритмов машинного обучения — классификации и регрессии.
Алгоритмы классификации предсказывают, к какому классу или категории принадлежит объект на основе предварительно определенных меток. Они используются в таких задачах, как распознавание образов, определение эмоционального тона сообщения, фильтрация спама и многих других. Python предлагает множество популярных алгоритмов классификации, таких как логистическая регрессия, метод опорных векторов (SVM), случайный лес и градиентный бустинг.
Алгоритмы регрессии используются для предсказания численных значений на основе имеющихся данных. Они помогают строить модели, которые прогнозируют, например, цену дома на основе его характеристик или спрос на товар. Некоторые популярные алгоритмы регрессии в Python включают линейную и полиномиальную регрессию, решающие деревья и случайный лес.
Ведущие алгоритмы машинного обучения могут быть разделены на две категории: алгоритмы с учителем и без учителя.
Алгоритмы с учителем требуют наличия помеченных данных, то есть таких данных, в которых каждый объект имеет соответствующую метку или результат. Эти алгоритмы используются для построения моделей и предсказания меток для новых данных. Некоторые ключевые алгоритмы обучения с учителем на Python включают логистическую регрессию, метод опорных векторов, деревья решений и случайный лес.
Алгоритмы без учителя используются для анализа данных без наличия помеченных данных. Они исследуют данные и выявляют скрытые закономерности и группы без предварительных знаний о классах объектов. Некоторые популярные алгоритмы без учителя в Python включают метод главных компонент, кластеризацию и ассоциативные правила.
Использование Python для обучения моделей машинного обучения позволяет эффективно реализовывать и применять эти различные алгоритмы. Python предлагает широкий выбор библиотек и фреймворков, таких как scikit-learn, TensorFlow и PyTorch, которые облегчают процесс разработки моделей и обучения алгоритмов машинного обучения.
Важно понимать, что выбор алгоритма и подхода к обучению зависит от конкретной задачи и данных. Чтобы достичь наилучших результатов, необходимо анализировать и экспериментировать с различными методами и моделями.
Алгоритмы машинного обучения
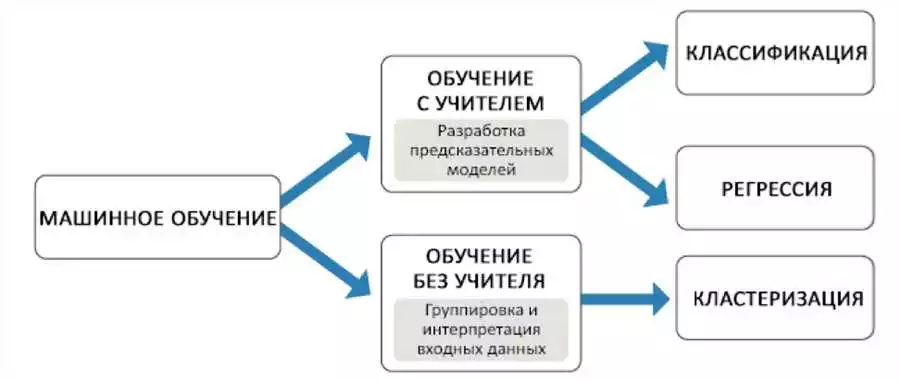
Алгоритмы машинного обучения в Python являются основополагающими методами в области искусственного интеллекта. Они позволяют компьютерам самостоятельно извлекать знания из данных и делать прогнозы на их основе.
Алгоритмы машинного обучения классифицируются по различным признакам. Один из ключевых признаков — это стратегия обучения. Существуют две основные стратегии: обучение с учителем и обучение без учителя.
В обучении с учителем имеются размеченные данные, где каждый пример обладает известным значением целевой переменной. Задача алгоритма — научиться предсказывать значения целевой переменной на новых данных. Виды алгоритмов обучения с учителем: классификация и регрессия. Алгоритмы классификации разделяют данные на группы или категории, а алгоритмы регрессии предсказывают численное значение целевой переменной.
В обучении без учителя разметка данных отсутствует. Алгоритмы машинного обучения без учителя находят в данных закономерности или шаблоны, выявляют скрытые структуры или проводят кластеризацию. Основные виды алгоритмов без учителя: кластеризация, снижение размерности и ассоциативные правила.
Важным аспектом алгоритмов машинного обучения является выбор подходящей модели. Наиболее популярные модели включают в себя линейную регрессию, метод k-средних, метод опорных векторов, случайный лес и нейронные сети. Каждая из этих моделей имеет свои особенности и применяется в разных областях.
Базовые алгоритмы машинного обучения являются основополагающими для дальнейшего изучения и использования в более сложных задачах. Они строятся на различных методах и подходах, таких как метод максимального правдоподобия, градиентный спуск и метод опорных векторов.
Ведущие алгоритмы машинного обучения в Python широко применяются в различных областях, таких как финансы, медицина, реклама и многие другие. Их использование позволяет автоматизировать процессы, обнаруживать закономерности и предсказывать будущие события с высокой точностью.
| Виды алгоритмов | Примеры |
|---|---|
| Обучение с учителем | Логистическая регрессия, метод опорных векторов, случайный лес |
| Обучение без учителя | Кластеризация k-средних, метод главных компонент, ассоциативные правила |
Выбор подходящего алгоритма машинного обучения зависит от задачи, доступных данных и требований к результату. Различные алгоритмы и модели предлагают широкий спектр возможностей для решения разных типов задач и имеют свои преимущества и недостатки. Изучение и применение алгоритмов машинного обучения на Python является важным шагом для понимания и использования искусственного интеллекта в различных сферах деятельности.
Supervised learning

Обучение с учителем (supervised learning) — это один из основных подходов в машинном обучении. В отличие от обучения без учителя, где модель алгоритма обрабатывает данные без предварительного знания о правильных ответах, в обучении с учителем модель обучается на основе предоставленных примеров входных данных и соответствующих им выходных данных, которые называются метками классов.
Ключевым преимуществом обучения с учителем является возможность классификации или регрессии данных. Классификация предполагает разделение данных на определенные классы, в то время как регрессия предсказывает численные значения. Для этого существует широкий спектр моделей и алгоритмов, каждый из которых имеет свои особенности и применим в разных ситуациях.
Основополагающие стратегии обучения с учителем включают:
- Деревья решений
- Метод ближайших соседей (k Nearest Neighbors)
- Линейная регрессия
- Логистическая регрессия
- Метод опорных векторов (Support Vector Machines)
- Случайный лес
- Градиентный бустинг
Каждый из этих методов имеет свои преимущества и недостатки, а также определенные предположения о данных.
В Python существует множество библиотек и фреймворков для реализации алгоритмов обучения с учителем, таких как scikit-learn, TensorFlow, и PyTorch. Они предоставляют широкий выбор реализаций различных моделей и алгоритмов, а также инструменты для обработки и визуализации данных.
Обучение с учителем является одним из важных и популярных подходов в машинном обучении. Оно нашло применение во многих областях, включая финансы, медицину, рекламу и др. Использование эффективных методов и алгоритмов обучения с учителем может существенно улучшить качество предсказаний и решение задач в различных областях деятельности.
Unsupervised learning
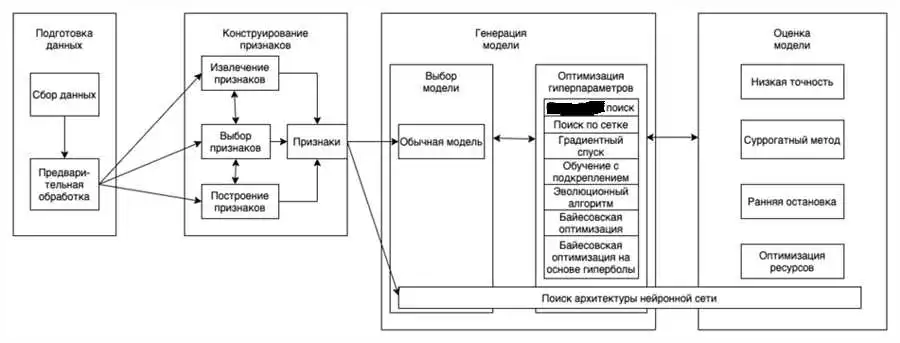
Использование алгоритмов и моделей без учителя (unsupervised learning) является одним из основополагающих и важных подходов в машинном обучении.
Методы без учителя не требуют наличия помеченных данных, то есть данных, размеченных специалистом-учителем. Вместо этого, модели без учителя самостоятельно находят закономерности, шаблоны или структуры в данных.
Основные стратегии применения алгоритмов без учителя включают следующие:
-
Кластеризация данных — разделение данных на группы (кластеры) по схожим признакам или свойствам. Ведущие методы кластеризации включают K-means, DBSCAN, и иерархическую кластеризацию.
-
Обнаружение аномалий — поиск необычных или отклоняющихся экземпляров в данных. Это полезно, например, для обнаружения мошеннических операций или неисправностей в системе. Популярными методами обнаружения аномалий являются Local Outlier Factor (LOF) и Isolation Forest.
-
Рекомендательные системы — предсказание предпочтений пользователей или рекомендации товаров на основе схожести между пользователями или товарами. Например, коллаборативная фильтрация и ассоциативные правила.
-
Снижение размерности данных — методы сжатия данных или конвертирования их в низкоразмерное пространство с минимальной потерей информации. Примерами таких методов являются PCA (Principal Component Analysis) и t-SNE.
Методы без учителя являются главными инструментами машинного обучения. Они позволяют находить скрытые закономерности и структуры в данных без необходимости подготовки размеченных обучающих данных. Применение этих методов находит широкое применение в таких областях, как анализ данных, маркетинг, медицина, финансы и другие.
Применение алгоритмов машинного обучения
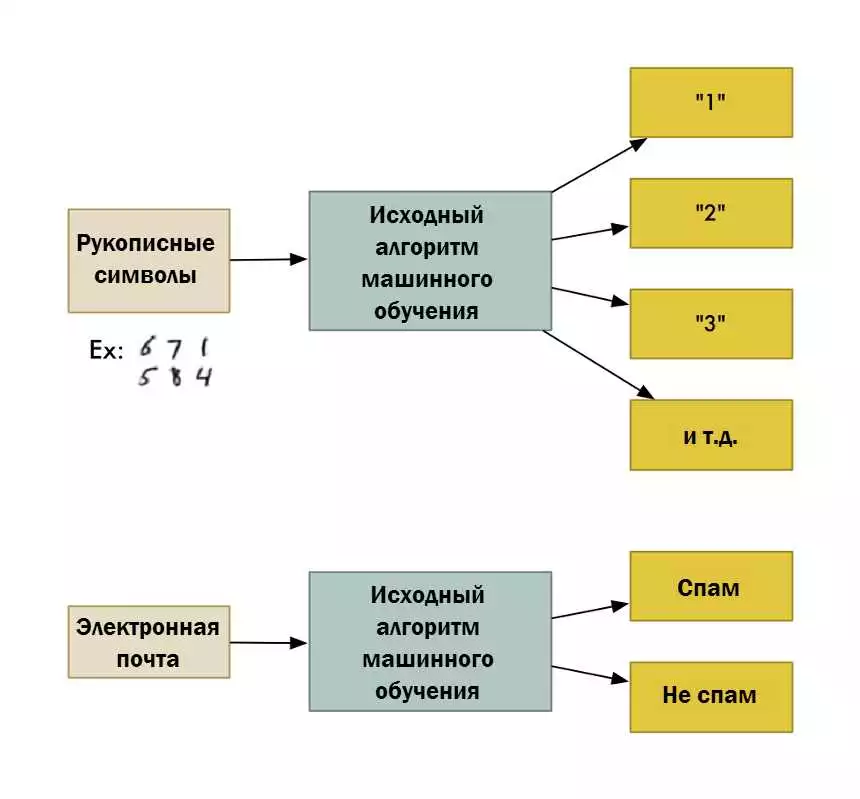
Алгоритмы машинного обучения на языке программирования Python широко применяются в различных областях, таких как искусственный интеллект, анализ данных и биоинформатика. Они позволяют моделировать и анализировать данные, а также делать прогнозы и принимать решения на основе имеющихся данных.
Существует множество различных подходов и методов машинного обучения, которые могут быть применены с помощью языка Python. Эти подходы включают в себя как обучение с учителем, так и без учителя, которые используются для разных задач и имеют различные стратегии обучения.
Одним из самых популярных методов машинного обучения является классификация, которая позволяет разделить объекты на определенные категории и прогнозировать их принадлежность к этим категориям. Модели классификации на основе алгоритмов машинного обучения в Python могут быть использованы для решения задач в области медицины, биологии, финансов и других областей.
Другим важным видом алгоритмов машинного обучения является регрессия, которая позволяет предсказать значения некоторой зависимой переменной на основе других переменных. Это наиболее часто используется в экономическом прогнозировании, маркетинговых исследованиях и других областях, где требуется прогнозирование будущих значений.
Важными базовыми методами машинного обучения являются методы обучения без учителя. Они позволяют находить скрытые закономерности и шаблоны в данных, которые могут быть использованы для обнаружения аномалий, кластеризации данных и других задач. Например, алгоритмы кластеризации могут использоваться для группировки клиентов, а алгоритмы обнаружения аномалий могут быть использованы для выявления необычных действий на основе исторических данных.
Применение алгоритмов машинного обучения на языке Python играет важную роль во многих областях и является ключевым инструментом для анализа, моделирования и прогнозирования данных. Популярные и ведущие алгоритмы машинного обучения, такие как деревья решений, случайные леса и нейронные сети, предоставляют различные методы и подходы для решения задач анализа данных.
Главные применения алгоритмов машинного обучения:
- Классификация данных на основе заданных категорий.
- Регрессия для прогнозирования будущих значений.
- Кластеризация для группировки данных.
- Обнаружение аномалий и необычных паттернов.
- Автоматическое принятие решений на основе имеющихся данных.
Важным аспектом применения алгоритмов машинного обучения на языке программирования Python является выбор подходящей модели и определение соответствующих методов и стратегий обучения. Это требует глубокого понимания алгоритмов и их основополагающих принципов, а также умения применять их на практике для решения конкретных задач.
| Название метода | Применение |
|---|---|
| Деревья решений | Классификация и регрессия |
| Случайные леса | Классификация и регрессия |
| Нейронные сети | Классификация и регрессия |
| Кластеризация K-средних | Группировка данных |
| Алгоритмы обнаружения аномалий | Обнаружение аномалий в данных |
Использование алгоритмов машинного обучения на языке программирования Python является важным инструментом для анализа данных и принятия решений на основе имеющихся данных. Они позволяют моделировать и анализировать данные, делать прогнозы и находить скрытые закономерности в данных. Понимание и применение различных видов и методов алгоритмов машинного обучения является ключевым навыком для специалистов в области анализа данных и искусственного интеллекта.
Классификация
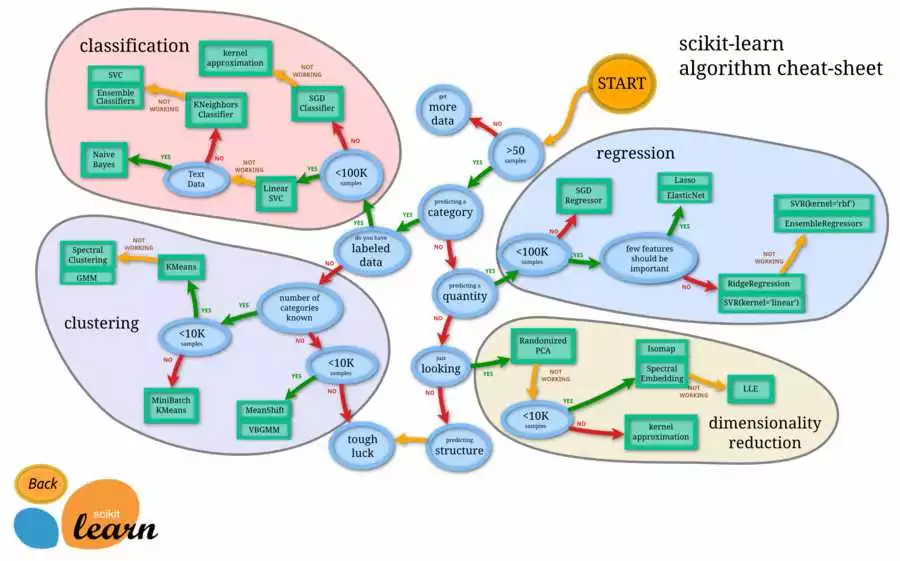
Классификация — один из самых популярных и главных подходов в машинном обучении. Она относится к обучению с учителем, где модель обучается на основе размеченных данных с известными метками классов. В классификации задача заключается в определении, к какому из заранее заданных классов относится новый набор данных.
Для задач классификации используются различные алгоритмы и методы. Ведущие алгоритмы классификации в машинном обучении на Python включают в себя:
- Линейные модели (например, логистическая регрессия)
- Решающие деревья
- Случайный лес
- Метод опорных векторов (SVM)
- Наивный Байесовский классификатор
- Метод ближайших соседей (K-Nearest Neighbors)
- Нейронные сети
Классификация имеет широкое применение в различных областях, таких как медицина, финансы, маркетинг, компьютерное зрение и другие. Она позволяет решать задачи диагностики, прогнозирования, обнаружения аномалий, сегментации аудитории и многое другое.
Для эффективного использования классификации необходимо правильно выбрать модель и подход, а также правильно подготовить данные. Методы классификации могут быть бинарными (разделяют данные на два класса) или многоклассовыми (разделяют данные на более чем два класса).
В базовых стратегиях классификации можно выделить следующие подходы:
- Бинарная классификация
- Многоклассовая классификация
- Иерархическая классификация
- Классификация с несбалансированными классами
Основополагающим принципом классификации является использование обучающих данных с известными метками классов, чтобы научить модель различать разновидности и классифицировать новые данные.
Примеры кода на Python для классификации
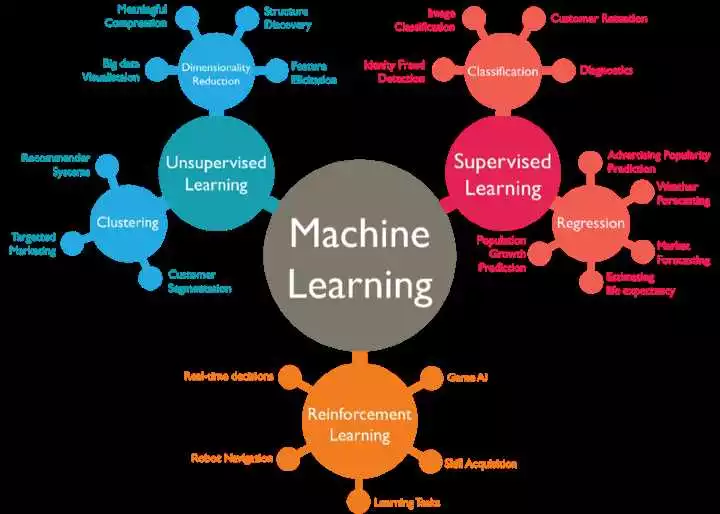
Пример логистической регрессии:
«`python
from sklearn.linear_model import LogisticRegression
# Создание модели логистической регрессии
model = LogisticRegression()
# Обучение модели на обучающих данных
model.fit(X_train, y_train)
# Предсказание классов для новых данных
predictions = model.predict(X_test)
«`
Пример случайного леса:
«`python
from sklearn.ensemble import RandomForestClassifier
# Создание модели случайного леса
model = RandomForestClassifier()
# Обучение модели на обучающих данных
model.fit(X_train, y_train)
# Предсказание классов для новых данных
predictions = model.predict(X_test)
«`
Пример метода опорных векторов (SVM):
«`python
from sklearn.svm import SVC
# Создание модели метода опорных векторов
model = SVC()
# Обучение модели на обучающих данных
model.fit(X_train, y_train)
# Предсказание классов для новых данных
predictions = model.predict(X_test)
«`
Это лишь некоторые примеры кода на языке Python для классификации. Python предоставляет широкие возможности для реализации различных методов и алгоритмов классификации.
Регрессия
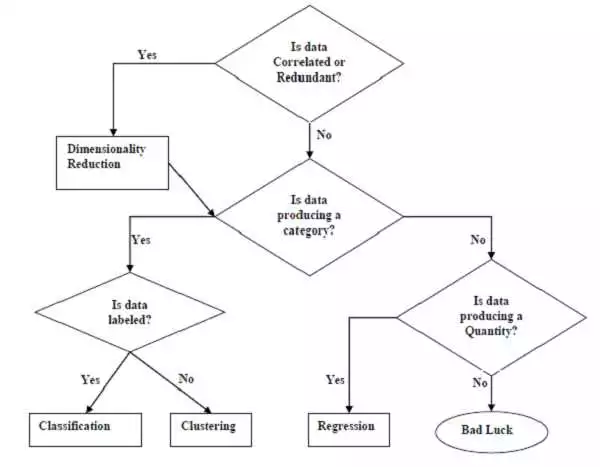
Регрессия — один из важных методов машинного обучения на Python. Этот алгоритм используется для предсказания числовых значений и относится к обучению с учителем.
Регрессия отличается от классификации тем, что она работает с непрерывными значениями, в то время как классификация работает с дискретными значениями.
В области регрессии существует несколько разновидностей и стратегий обучения, ведущие методы которых рассматриваются ниже:
- Линейная регрессия — один из главных методов регрессии. Целью этой модели является поиск линейной зависимости между признаками и целевой переменной.
- Полиномиальная регрессия — расширение линейной регрессии, которое позволяет учесть нелинейные зависимости между признаками и целевой переменной.
- Гребневая регрессия — метод, который используется для борьбы с переобучением моделей путем добавления регуляризации.
- Лассо-регрессия — аналогична гребневой регрессии, но с добавленным условием отбора признаков, что делает ее основополагающей для фильтрации признаков.
- Регрессия на основе деревьев — использует деревья для построения модели регрессии. Включает в себя такие методы, как решающее дерево, случайный лес и градиентный бустинг.
Важные разновидности регрессии могут быть как с использованием учителя, так и без использования:
- Регрессия с учителем — тип моделей, требующих размеченных данных для обучения и сопоставления признаков с целевой переменной.
- Регрессия без учителя — методы, которые обучаются на неразмеченных данных, определяя закономерности в данных и позволяя выполнять предсказания на основе этих закономерностей.
Регрессия является одним из базовых подходов в машинном обучении, и ее использование широко распространено в различных областях:
- Экономика — для прогнозирования экономический показателей и ценовых изменений.
- Маркетинг — для анализа и прогнозирования спроса на товары и услуги.
- Медицина — для предсказания заболеваний и влияния лекарств на пациента.
- Финансы — для прогнозирования финансовых показателей и оценки рисков на рынках.
Таким образом, регрессия является одним из ведущих методов машинного обучения на Python, который предоставляет инструменты для предсказания числовых значений на основе обучения с учителем и без учителя.